



























.png)









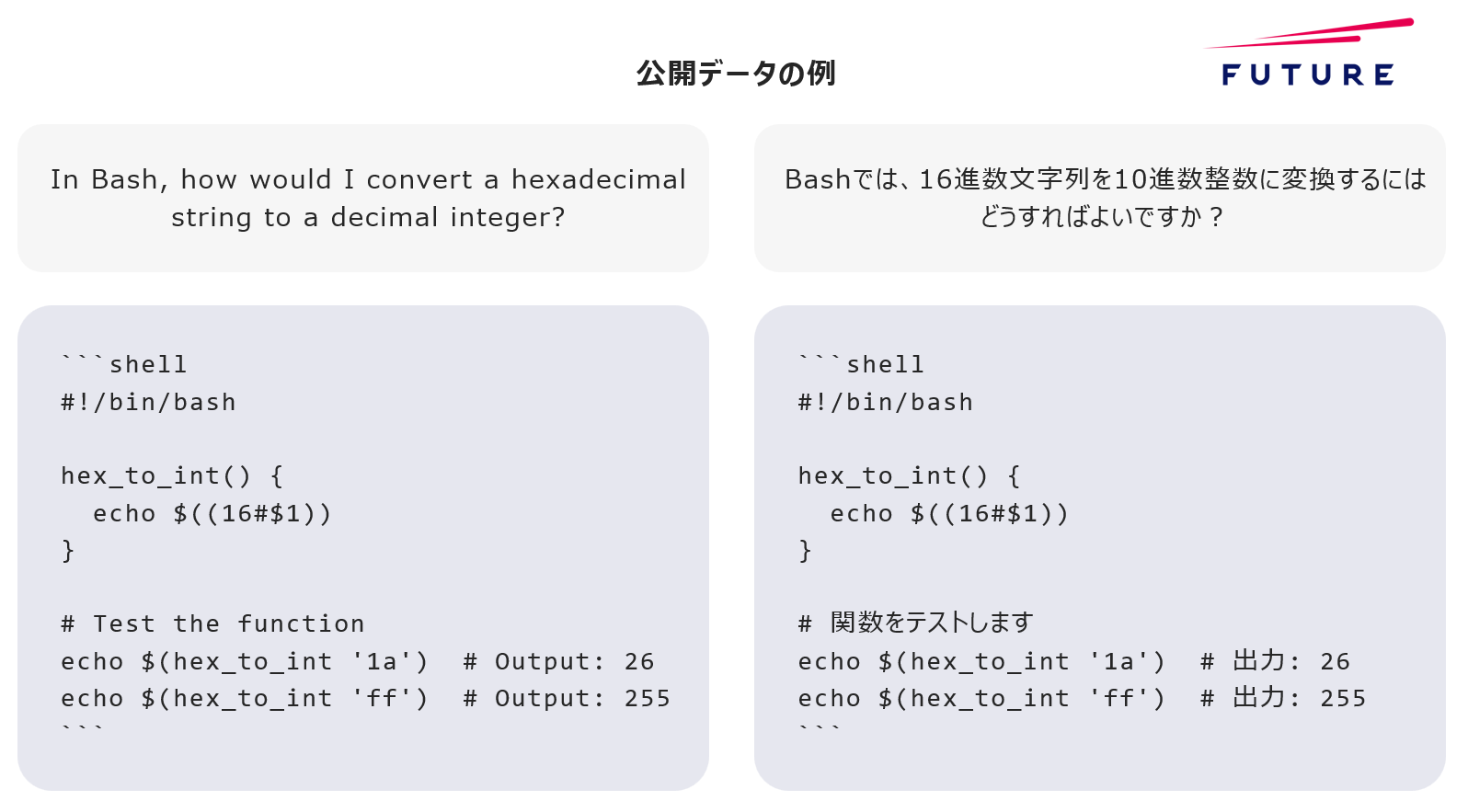
フューチャーは、人がLLMに与える指示とそれに対する回答のペアで構成される、ソフトウェア開発に関するインストラクションチューニング(Instruction-Tuning)データを無償公開した。
LLMの開発には良質な学習データが必要な一方、日本語に特化したソフトウェアに関するインストラクションチューニングデータが限られることが同分野の研究開発における障壁になっている。
同社は、2024年10月より経済産業省とNEDO(国立研究開発法人 新エネルギー・産業技術総合開発機構)が実施する国内生成AIの開発力強化プロジェクト「GENIAC」に採択され、「日本語とソフトウェア開発に特化した基盤モデル」の研究開発を行ってきた。
今回公開したデータは、同プロジェクトの研究過程においてベンチマークとしたLLMをもとに自動生成したもの。同社は、このデータを活用し、開発した「Llama 3.1 Future Code Ja」が、特に日本語の指示によるソースコード補完能力に優れていることを確認している。
この記事は参考になりましたか?
- この記事の著者
-

CodeZine編集部(コードジンヘンシュウブ)
CodeZineは、株式会社翔泳社が運営するソフトウェア開発者向けのWebメディアです。「デベロッパーの成長と課題解決に貢献するメディア」をコンセプトに、現場で役立つ最新情報を日々お届けします。
※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です
