




































マルチスレッド・プログラミングのためのC++ライブラリ:インテルTBB(Threading Building Blocks)はこれまでにも何度か紹介してきました(記事1、記事2、記事3)。商用版とOpenSource版があり、無償のOpenSource版はTBB Homeから入手できます。
適当なディレクトリに展開し、環境変数:TBBROOTをそのディレクトリに設定して準備完了、実行時には<TBBROOT>/bin配下にあるDLLを必要とします。ビルド時にはインクルード・パス:<TBBROOT>/include およびライブラリ・パス:<TBBROOT>/lib/ia32/vc12を設定します(アーキテクチャとコンパイラに応じて、例えば64bitでvc++9であれば<TBBROOT>/lib/intel64/vc9です)。
マルチスレッドで高速化
TBBのチュートリアル・ドキュメントにこんなサンプルを見つけました。
「f(x) = x^2 + x^3 が与えられたとき、f(1) + f(2) + …… + f(10) を求めよ」
というもの。素直に実装すればどうということはありません。
#include <iostream>
using namespace std;
typedef int item;
item calc(int lo, int hi) {
item reswult = 0;
for ( int i = lo; i <= hi; ++i ) {
item x = i;
result += x*x + x*x*x;
}
return result;
}
int main() {
cout << calc(1,10) << endl;
}
こんなところでしょうか。itemがintやdouble程度なら一瞬で終わっちゃうプログラムです。
けども例えばitemが1000次の正方行列だったら、x*xはその中で百万回のかけ算が行われます。要素かけ算一回が1マイクロ秒で求まるとしても、百万回のかけ算なら1秒を要します。単純に見える計算でも分野によってはかなりの計算量となり、高速化が求められることが少なくありません。
itemのかけ算に200ms、たし算に100msかかるよう、busy-waitを仕込んで実測してみました(積算している+=を除いて)。x*x + x*x*x はかけ算3回/たし算1回を行うので700ms、それを10回繰り返しますから700msかかることになります。
#ifndef UTILS_H_
#define UTILS_H_
#include <chrono>
#include <cstdio>
#include <iostream>
// durationミリ秒のビジーウェイト
void busy_wait(int duration) {
using namespace std::chrono;
auto start = high_resolution_clock::now();
auto stop = start;
do {
stop = high_resolution_clock::now();
} while ( duration_cast<milliseconds>(stop - start) < milliseconds(duration));
}
// めっちゃ遅いかけ算とたし算
template<typename T> inline T slow_add(T x, T y) { busy_wait(100); return x + y; }
template<typename T> inline T slow_mul(T x, T y) { busy_wait(200); return x * y; }
// かけ算とたし算が(わざと)苦手な slow_item<T>
template<typename T>
class slow_item {
T value_;
public:
slow_item(T value =T()) : value_(value) {}
T value() const { return value_; }
slow_item& operator+=(const slow_item& x) { value_ += x.value(); return *this; }
};
template<typename T> inline
slow_item<T> operator+(const slow_item<T>& x, const slow_item<T>& y) {
return slow_add(x.value(), y.value());
}
template<typename T> inline
slow_item<T> operator*(const slow_item<T>& x, const slow_item<T>& y) {
return slow_mul(x.value(), y.value());
}
template<typename T> inline T value(T x) { return x; }
template<typename T> inline T value(const slow_item<T>& x) { return x.value(); }
// 関数fの呼び出しに要する時間を測る
template<typename Function, typename ...Args>
void measure(Function f, Args ...args) {
auto start = chrono::high_resolution_clock::now();
f(args...);
auto stop = chrono::high_resolution_clock::now();
std::cout << chrono::duration_cast<chrono::milliseconds>(stop - start).count() << "[ms]\n";
}
// デバッグ用
#ifdef _DEBUG
#define trace(format,...) printf(format, __VA_ARGS__)
#else
#define trace(format,...)
#endif
#endif
#include "utils.h"
using namespace std;
typedef slow_item<int> item;
/* x = 1, 2, ... 10
x^2 + x^3 の総和を求める
*/
item calc(int lo, int hi) {
item result = 0;
for ( int i = lo; i <= hi; ++i ) {
item x = i;
result += x*x + x*x*x;
}
return result;
}
int main() {
item result;
measure([&result]() { result = calc(1,10); });
cout << value(result) << endl;
}
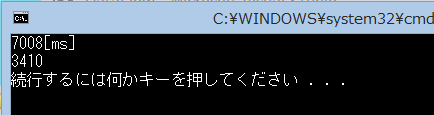
かけ算/たし算の所要時間は動かせないとして、もっと速く計算できないものでしょうか。複数のCPUが同時に動いてくれるなら可能です。x*x と x*x*x とを同時に計算し、双方の結果が揃ったところでたし算すれば、双方の結果が出揃うまでに400ms/たし算に100msで合せて500ms、10回やって5000msに短縮できるはず。C++11のスレッド・ライブラリ:<future>で試してみます。
#include <future>
#include "utils.h"
using namespace std;
typedef slow_item<int> item;
/* x = 1, 2, ... 10
x^2 + x^3 の総和を求める
*/
item calc(int lo, int hi) {
item result = 0;
for ( int i = 1; i <= 10; ++i ) {
item x = i;
// 2つのスレッドで二乗と三乗を求め
future<item> square = async([](item x){ return x*x; }, x);
future<item> cube = async([](item x){ return x*x*x;}, x);
// 両者の結果が揃ったら加える
result += square.get() + cube.get();
}
return result;
}
int main() {
item result;
measure([&result]() { result = calc(1,10); });
cout << value(result) << endl;
}
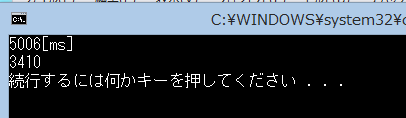
……もっと速くなるでしょうか。dual-core機で2つのスレッドが同時に動けるとして、f(x)を求める過程で2つのスレッドが同時に動いているのは200msの間だけ、残る300msは一方のスレッドが暇を持て余しています。遊んでいるスレッドに次のf(x+1)をやらせることができるなら、2つのスレッドがフル稼働して半分の時間で完了すると期待できます。TBB:Flow Graphで構築するデータフローはそれを可能にしてくれます。

