





































対象読者
- Java経験者(初心者可)
- RxJava未経験者
- リアクティブプログラミング未経験者
※ ただし、前回までの連載を読んでいる前提です。
ParallelFlowableについて
ParallelFlowableはバージョン2.0.5より新しく追加された機能で、後続のオペレータやSubscriberに通知するデータを複数のタイムライン(公式では「rail(レール)」と呼ばれている)に分配して、各データの処理を異なるレール上で処理を行う機能を持つFlowableの一種です。そのため、1つのデータを受け取って処理を実行している最中に、次のデータを別スレッド上で動くレールにて受け取り処理をすることで、複数の処理を同時に実行する(並列モードにする)ことが可能になります。基本的にはParallelFlowableがデータを一つずつ順番に、それぞれのレールに渡すようになっています。

このParallelFlowableはバージョン2.0の間は実験的(Experimental)な位置づけでしたが、2.1にバージョンアップした段階でベータ(Beta)にステータスが上がりました。ただし、今後フィードバックなどを受けて仕様が変わる可能性もあるので、本番環境など実際のプロダクトとして使うのは安定板が出るまで待った方がいいでしょう。
また、ParallelFlowableはFlowableにしかなくObservableには同等の機能を持ったクラスはありません。これは並列で処理を行っている際に、その中のあるレールの処理が遅くなる場合、バックプレッシャーをかけて通知するデータ数に制限をかけないと、そのレールにて処理をすべきデータが無制限に貯まっていく危険性があるためです。ParallelFlowableでは、データを各レールに振り分ける際にそのレールが受け取るデータ数のリクエストを受け、その分だけ通知した後は次のリクエストが来るまで、それ以上のデータを通知しないようにバックプレッシャーをかけて受け取るデータ数を制限することが必要になります。もし、レールの処理が遅れてデータ数のリクエストが来ていない場合は、そのレールに対してデータの振り分けがスキップされます。
加えて、ParallelFlowableは異なるレール上で処理を行うため、購読するSubscriberも複数になります。そのため、ParallelFlowableのsubscribeメソッドはSubscriberの配列を受け取るようになっています。その際、レールの数とSubscriberの数を一致させないと、通知するSubscriberやデータを受け取るためのレールがないといったことが起こり、エラーになってしまいます。
また、ParallelFlowableからFlowableに変換し直すメソッドもあり、データに関する処理を並列モードで行い、最終的にFlowableに変換して1つのSubscriberにデータを通知することも可能です。ただし、各レールでデータの処理を非同期で行うため、結果となるデータの通知順が元のデータ順と同じになることを保証されなくなることに注意する必要があります。
FlowableにあるtakeやskipなどのいくつかのオペレータはParallelFlowableにはありません。それらのオペレータを使う必要がある場合は、ParallelFlowableに変換する前後で使用しなければいけません。
ParallelFlowableの生成
PralellFlowableを生成するには、データを通知するための元となるFlowableが必要です。そして、そのFlowableを変換して新しいParallelFlowableを生成します。この変換するためのオペレータは2種類あり、1つはParallelFlowableのstaticメソッドであるfromメソッド、もう1つはFlowableのインスタンスメソッドであるparallelメソッドになります。ただし、staticメソッドとインスタンスメソッドの違いはあっても、処理する内容は同じです。

fromメソッド(ParallelFlowableのstaticメソッド)
-
from(Publisher<? extends T> source) -
from(Publisher<? extends T> source, int parallelism) -
from(Publisher<? extends T> source, int parallelism, int prefetch)
※PublisherはFlowableが実装しているインターフェース
parallelメソッド(Flowableのインスタンスメソッド)
-
parallel() -
parallel(int parallelism) -
parallel(int parallelism, int prefetch)
| 引数の型 | 引数名 | 説明 |
|---|---|---|
| Publisher | source | ParallelFlowableに変換されるFlowable。fromメソッドでしか使わない。 |
| int | parallelism | データを分配する際のレール数。デフォルト(指定しない場合)では実行環境の論理プロセッサ数。 |
| int | prefetch | 元となるFlowableに通知するようにリクエストするデータ数。デフォルト(指定しない場合)では128。 |
まず、ここで重要になるのが引数のparallelismです。レールをいくつに分割するのかを設定する値ですが、この引数を設定しない場合はデフォルトで実行環境の論理プロセッサ数になります。しかしParallelFlowableを購読する場合、レール数と同じ数だけのSubscriberが必要になり、そうでない場合はエラーが通知されます。一方、最終的にParallelFlowableからFlowableに変換する場合は、いくつレールがあっても最終的に1つのレールにマージされるため、明示的な指定をしなくてもレールの数とSubscriberの数が不一致であることに関するエラーが通知されることはありません。実行環境の論理プロセッサ数によってレール数が変わるということは、その環境にとってベストパフォーマンスと考えられるレールの分配がされることになります。この変数の設定はParallelFlowable自身に対して購読するのか、もしくはFlowableに変換するのかによって、明示的に指定するほうがいいのか、デフォルトのままのほうがいいのかが変わってきます。
次に気を付けるべきことは引数のprefetchです。これはParallelFlowableの元となるFlowableがそのParallelFlowableへ通知するようにリクエストされたデータ数で、この引数を指定しない場合は自動的に128が設定されます。observeOnメソッドの場合と同様にリクエストしたデータ数の75%分のデータを通知したら、75%分のデータ数のリクエストを繰り返すようになります。つまり、後続の処理が異なるスレッド上で実行されている場合や、後続の処理が通知スピードより遅い場合、データはキャッシュされることになります。通知データはキャッシュから送られ、リクエストしたデータ数分を超えた場合はエラーになってしまいます。これを意識していないと、例えば元のFlowableに処理待ちのデータを破棄する設定(BackpressureStrategy.DROP)がしてあり、Subscriber側で1件ずつ通知するようにリクエストを行っていたとしても、通知データはバッファされたデータから通知されるため、ドロップされると想定していた古いデータが通知される可能性があるので注意が必要です。
Schedulerの設定(runOnメソッド)
ここで注意しておかないといけないこととして、ParallelFlowableは自動的に非同期処理を行うわけではないことがあります。Schedulerの指定をしていないParallelFlowableは元のFlowableの処理が実行されているスレッド上でParallelFlowableの全レールの処理が実行されるため、あるデータを通知したら、そのデータを受け取ったレールの処理が終わるまで次のデータを通知せず、そのレールの処理が終わって初めて次のデータを別のレールに通知し、そのレールで処理が終わるまで通知元の処理も待機するといったことを繰り返すようになります。
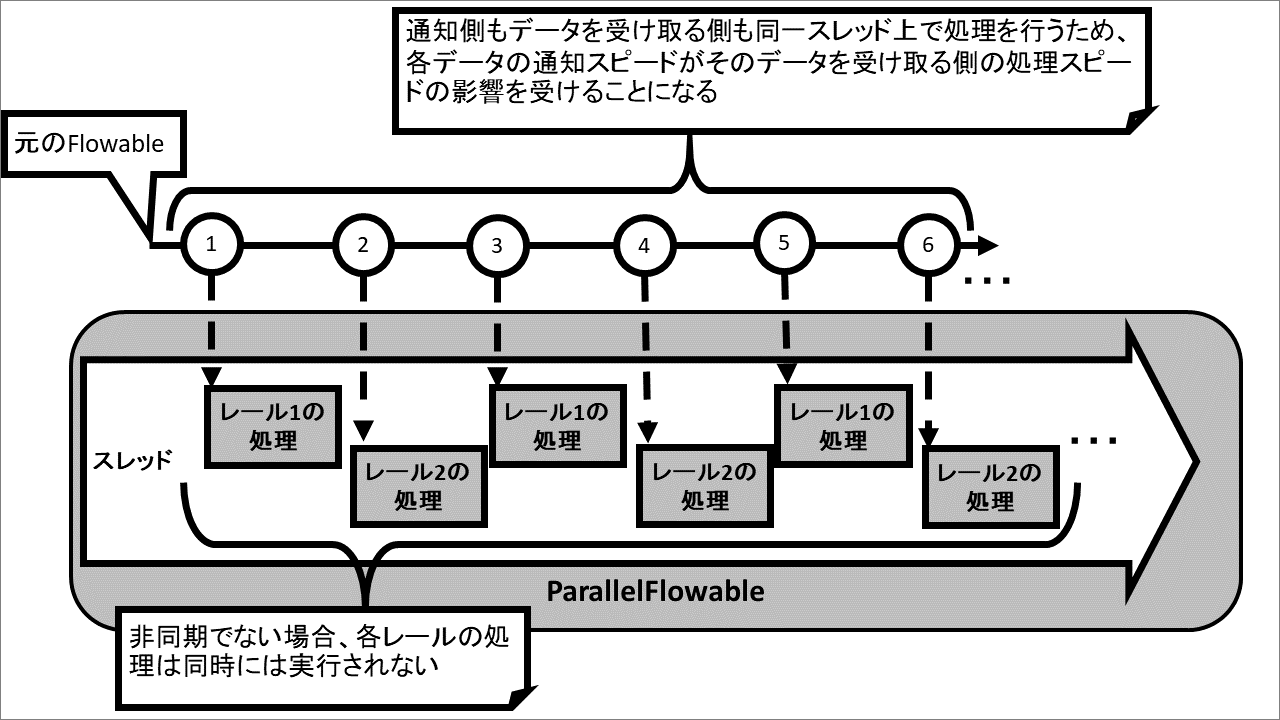
これでは、後続のオペレータやSubscriberに異なるデータを順番に振り分けているのにも関わらず、パフォーマンスとしては何のメリットもありません。それに対し、ParallelFlowableにSchedulerを設定すると、各レールの処理を異なるスレッド上で実行する並列処理になるため、各レールが元のFlowableや他のレールの処理を待機させることがなくなり、パフォーマンスの向上が期待できるようになります。ただし、その場合は各レールの処理が共有される可変のオブジェクトにアクセスしないといった、非同期処理を行っても問題がない作りになっていることが条件になります。
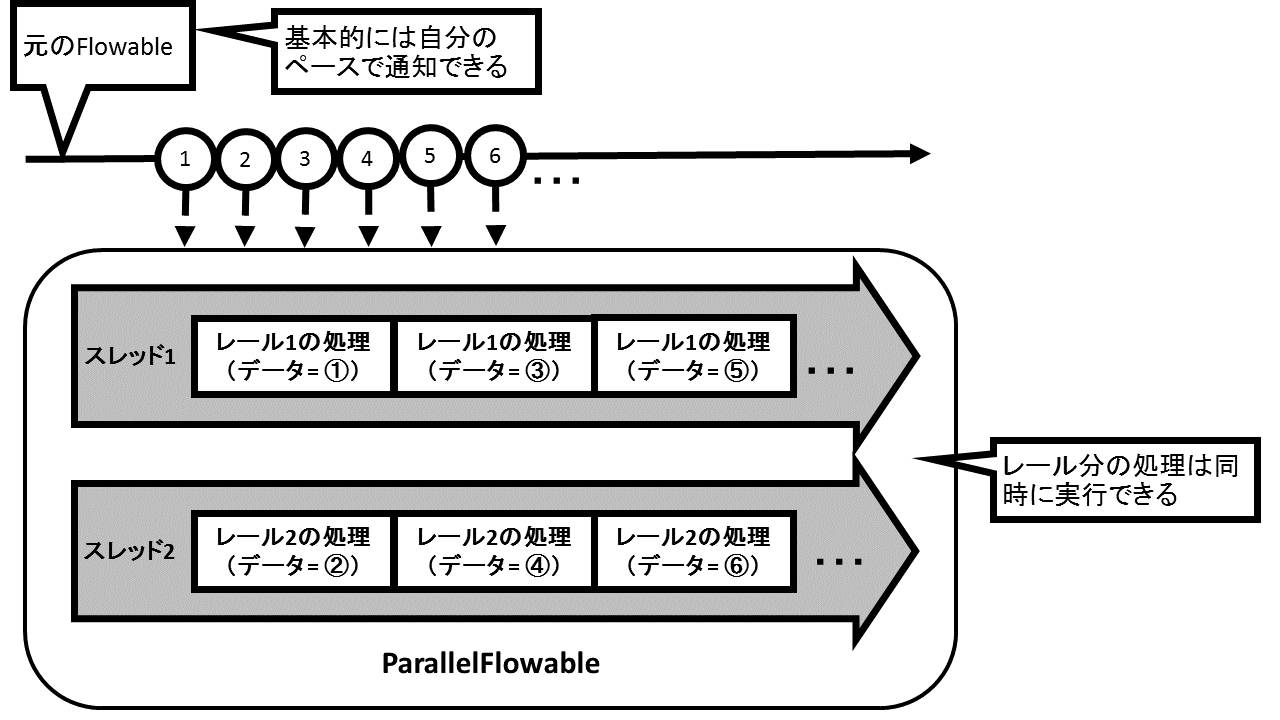
このことを行うため、ParallelFlowableには各レールの処理を指定したScheduler上で実行させるメソッドとしてrunOnメソッドを用意しています。
runOnメソッド
-
runOn(Scheduler scheduler) -
runOn(Scheduler scheduler, int prefetch)
| 引数の型 | 引数名 | 説明 |
|---|---|---|
| Scheduler | scheduler | 各レールの処理をどうようなスレッド上で行うのかを指定するScheduler。 |
| int | prefetch | 各レールが通知するようにリクエストするデータ数。デフォルト(指定しない場合)では128。 |
第2引数のprefetchは各レールが通知するようにリクエストするデータ数です。この引数がない場合はデフォルトで128になります。データ数をリクエストするということは、データを受け取る側の処理が通知する処理より遅くなった場合、対象のレールに通知されるデータはバッファされ、現在のデータの処理が終わってからようやくバッファされたデータから次のデータを受け取るようになることを意味します。例えば、1つのレールの処理が遅い場合、そのレールが受け取るはずのデータはバッファされ、他のレールはバッファされたデータとは異なるデータを受け取り、次々と処理をしていくようになります。

これを避けるには、runOnメソッドのデフォルトを変更し、1件しかデータを通知しないようにリクエストさせる必要があります。すると、各データはデータを受け取る準備ができたレールにのみ次々とデータを通知するようになります。

ただし、注意しないといけない点もあります。全てのレールの処理が遅くなる場合、上流の処理のほうで処理待ちのデータをバッファすることになるので、そこをうまく調整しないとMissingBackpressureExceptionが発生し、エラー通知されることになります。

