





































シェアード・エブリシング・クラスタのスケーラビリティ
シェアード・エブリシング・クラスタはすべてのノードがストレージのすべてのデータにアクセスすることが可能で、複数のノードが同じ表の同じ行データをキャッシュすることが可能です。そのため「クラスタ構成に対応するために表をパーティショニングする」ということが必須ではありません。パーティショニング設計は論理データ構造を維持したままSQL処理の演算量を下げるために行います。
シェアード・エブリシング・クラスタはすべてのノードが同じ行データをキャッシュできるため、SELECT文のような読み取りのみの処理は複数のノードで同じ行にアクセスするSQLを同時に実行することができます。そのため、パーティショニングした表でもどの表パーティションにアクセスが集中するかということと関係なくノードを追加して性能を上げることができます。
シェアード・エブリシング・クラスタで注意するケースは、同一データもしくはとても狭い範囲のデータに多くのセッションから更新が集中するアクセス・パターンです。あるノードで行を更新しようとしたとき、そのノードで更新対象行に対する排他ロックを持っていなければ、ノード間の排他制御をかけて更新します。そのため、複数のノードが狭い範囲の同一データを更新しようとすると、ノード間の排他制御が多発します。
これに対処するには、表や索引のパーティショニングがよく使用されます。データの物理的な格納場所を分散させるために、列の値をハッシュしてパーティションを特定するハッシュ・パーティショニングがよく使用されます。列の値が異なると異なるパーティションに格納されるため、排他ロック獲得の衝突が低減されます。
また、分析処理に特化したデータベースは「データを更新する」という機能を捨てたものもあります。データベース内のデータが変化することを考慮しなくてよくなるため、ノード間のデータの整合性を取ることを省略しています。
アクセス・パターンとスケーラビリティ
索引やパーティションなどの物理構造は、実行される特定の処理の演算量を下げるために設計します。シェアード・ナッシング・クラスタはノードとデータのパーティショニングが密接に結びついていますが、シェアード・エブリシング・クラスタは結びついていません。この違いがデータベース・システムの用途に関わってきます。
シェアード・ナッシング・クラスタはデータへのアクセス・パターンがそのままクラスタの各ノードのリソース消費に直結します。アプリケーションのデータ・アクセス・パターンとパーティション設計が適合し「各パーティションへのアクセス・パターンがほぼ均等になる」「SQL処理による複数表へのアクセスがなるべく1ノード内で完結する」という条件を満たすとき、クラスタのノードの追加と性能向上が強い相関を持ちます。逆にアプリケーションが改修されて新しいアクセス・パターンが発生したとき、既存のパーティショニング設計がクラスタ・ノード構成と適合していなければ高い性能が出せないということになります。マイクロサービス・アーキテクチャのように、アプリケーションの役割を分割してそこからアクセスするデータベースも特定のマイクロサービスのアクセス・パターンに特化したものでよければシェアード・ナッシング・クラスタが適合できます。
シェアード・エブリシング・クラスタはデータの値とDBサーバー・ノードが結びついていません。そのため、ある特定のアクセス・パターンに特化したパーティショニング設計をしていても、そこからアプリケーションのデータ・アクセスのパターンが変化したとしてもすべてのノードのハードウェア・リソースを使用することができます。そのため、システム用途の拡張に対しデータベースそのものを増やさずに対応できる場合があります。
ハードウェア・リソースの進歩とこれからのデータベース
ここまでは、複数の物理サーバーを組み合わせるクラスタ構成の限界や課題について見てきました。しかし、近年の劇的なハードウェアの進化は、こうしたデータベース・アーキテクチャの前提そのものを大きく変えようとしています。
2000年ごろのCPU1ソケットあたり1コアだったころは、1つのアプリケーションを動かすためのデータベース・サーバーのハードウェア・リソースの不足気味だったので、1つのデータベースが1つのアプリケーションのために用意されるというシステム・アーキテクチャが当たり前でした。オンライン・トランザクション処理用のデータベースが生成したデータを、ETL処理やレプリケーション機能で分析用データベースにデータを移し替えるという構成が確立しました。
その前提を継承したシステムがクラウドで構成されるようになり、2010年ごろ以降ではクラウドで稼働させることを暗黙の前提としたシェアード・ナッシング・クラスタがNewSQLというキーワードで注目を浴びました。しかし、それ以後も半導体の集積度が急速に進み、2026年現在ではマザーボード1枚あたりCPU100コア以上やテラバイトの単位のメモリーなどのハードウェア・リソースが使用できる状況にあります。半導体の微細化技術はまだ進歩しており、物理マシン1台当たりのハードウェア・リソースはまだしばらく増加していくでしょう。
物理マシン1台当たりのCPUやメモリーが膨大な量が使用できるようになったということは、データベース・エンジン・ソフトウェアのスケール・アップによる性能向上の対応能力(スケーラビリティ)が求められるようになります。10数コアなら性能が飽和していたソフトウェアが、100コア以上でも性能がスケールするかはそれこそソフトウェア・アーキテクチャの良し悪しにかかっています。
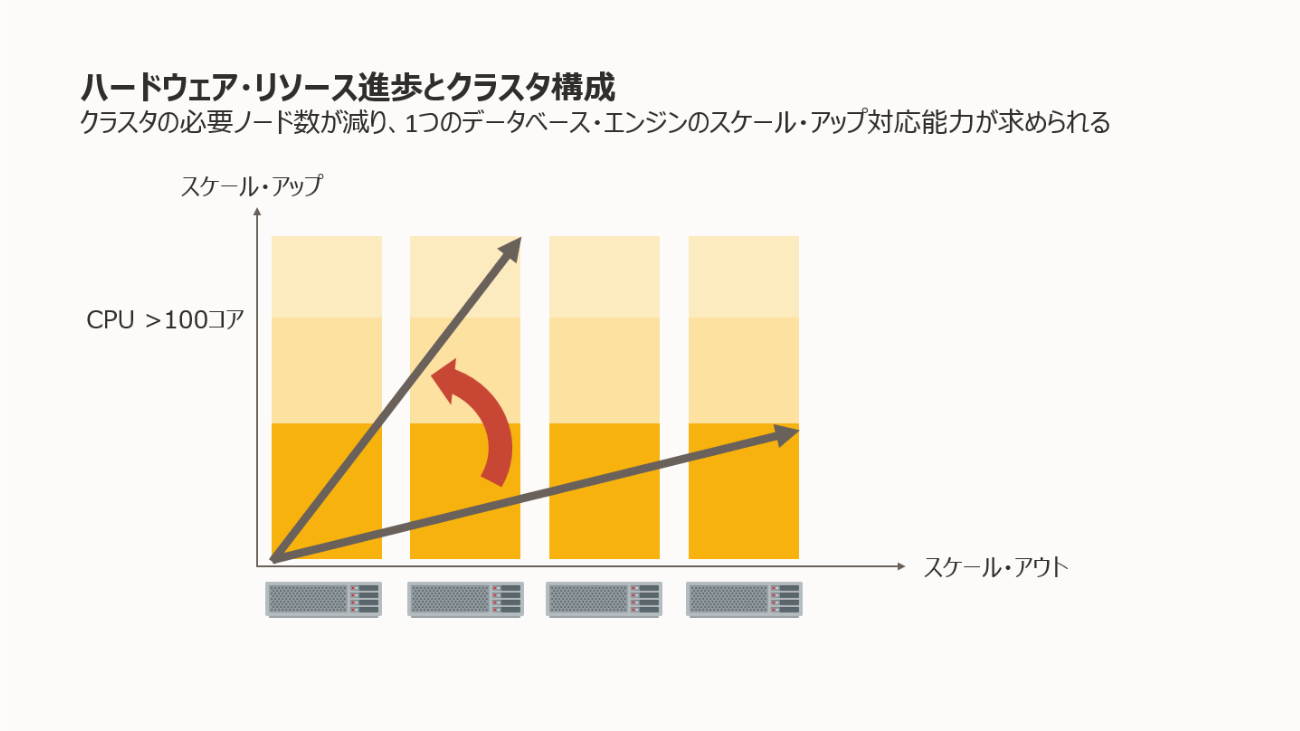
スケール・アップでのスケーラビリティが高いデータベース・エンジンのクラスタ構成では、クラスタのノード数も過去より少なくて済むということになります。また、1台の物理マシン上に複数の仮想マシンやデータベースのマルチテナント構成で複数のデータベースを稼働させるという構成も当たり前のように使われるようになりました。
これらは、多くの場合において、単一アプリケーションのデータベースが求めるハードウェア・リソースはクラスタ構成を取らなくともまかなえるようになってきていることを表しています。しかし、ITシステムは複数のアプリケーションが高度に連携しあうようになっており、1つのITシステムの中には複数のデータベースが存在しています。これら複数のデータベースのデータの整合性と、ホストするハードウェア・リソースの総量を考えます。
ITシステム全体を見渡すと、オンライン・トランザクション処理が生成したデータを分析するといった、性質の異なる処理がデータベースに対して発行されます。過去においては、1つのアプリケーションが発行するデータベース処理の負荷要求を満たすことが1台の物理マシンでは難しかったために、用途別にデータベースを構築し、データベース間でデータを複製するというシステム構成が取られていました。この構成では1つのデータベースに求める用途やアクセス・パターンが限定的であったため、そのアクセス・パターンに特化したチューニングを施したデータベースで対応できました。
その副作用として、データベース間でデータを複製する工程を挟むと、データが生成される側とそれを複製する側のデータベース間でデータの整合性がずれている時間帯が発生します。従来のITシステム・アーキテクチャではオンライン・トランザクション処理のユーザーと分析処理のユーザーは完全に異なる対象であったため、データベース間の「多少の」時間的な整合性のずれは問題になりませんでした。しかし、これからのAIエージェントの活用を考えると、データベース間のデータの整合性のずれがいずれ大きな問題として取り上げられてくるでしょう。AIエージェント群がシステムの中に存在する複数のデータベースにアクセスするとき、データの整合性がとれていないと不正確な状況を作り出してしまうのです。
ところが、1台の物理マシンが100以上のCPUコアやテラバイト単位のメモリーの膨大なリソースを持つようになると「ハードウェア・リソース不足なため1つのデータベースは1つのアプリケーションに特化する」という制約が外れます。また、膨大なリソースを持つ物理マシンでさらにクラスタも構成できる状況にあるのです。
2000年ごろの制約に基づく「1つのアプリケーションに特化したデータベース間でデータを複製する」というシステム・デザインが四半世紀経過した今でも合理的なものであるかは、そろそろ再検討される時期に来ているのではないでしょうか。
第1回で説明したように、リレーショナル・モデルとSQLの実装は「求めるデータの集合のみを記述し、それを導出する高速なアルゴリズムはデータベース・エンジンが自動生成する」というモデルです。
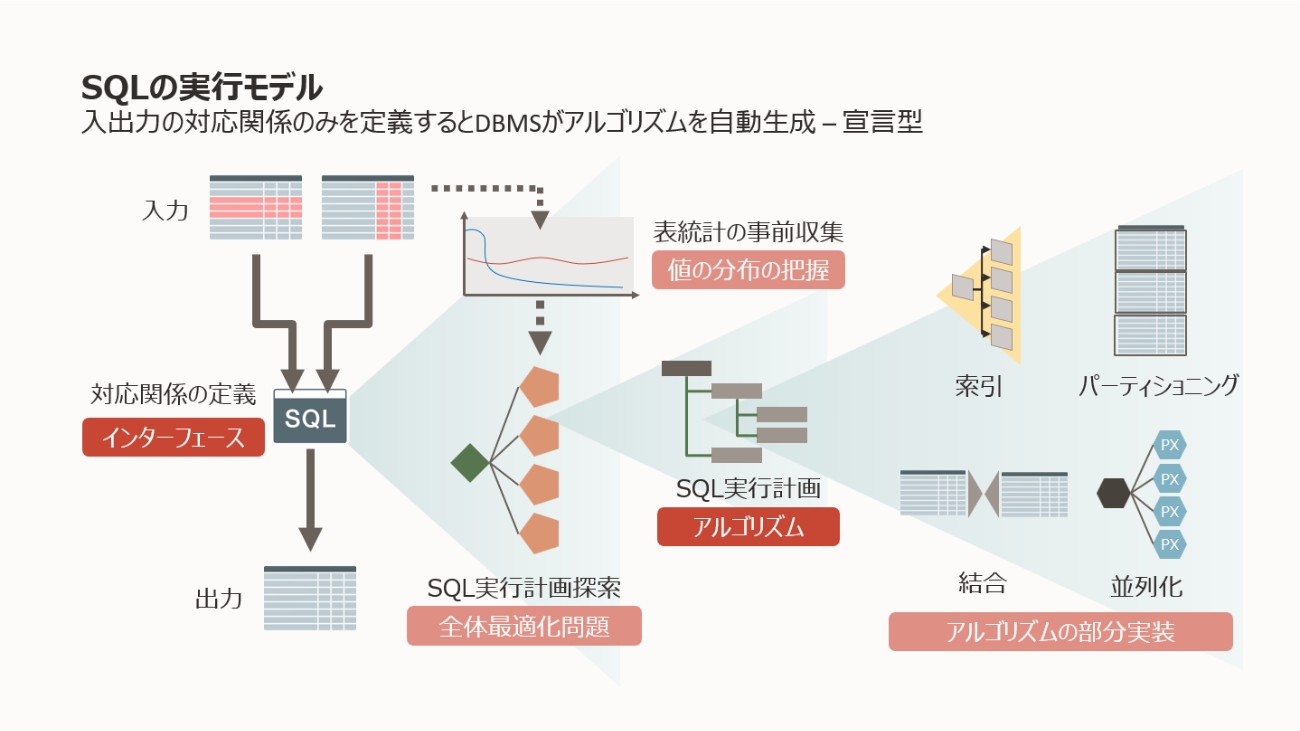
オンライン・トランザクション処理や分析処理といった処理の性質の違いによるアルゴリズムの最適化はデータベース・エンジンが吸収するべきなのです。20世紀の時点で、1つのデータベースでオンライン・トランザクション処理と分析処理を行いたいという願望はありました。その概念は21世紀になってから名前が付けられHybrid Transactional Analytical Processing(HTAP)やTranslyticalと呼ばれています。ですが、実装の難易度から、性質の異なるワークロードに1つの表が対応するのは困難でした。
近年のデータベース・エンジンはリレーショナル・モデルだけではなく、マルチモデル/マルチワークロードに対応すると謳うものが増えてきました。しかしその実態は「異なる表としてならば異なるワークロードに最適化した表を1つのデータベースの中に保持できる」というものがかなりあります。しかしこれではオンライン・トランザクション処理用の表で生成されたデータを分析用の表に複製することになり、用途別にデータベースを分けていたのと本質的には変わっていません。
1つの表に対してマルチワークロードに対応するには、性質の異なるアクセス・パターンへの最適化を同居させることになり、データベース・エンジンはより難易度の高い実装が求められます。たとえばデータベースの物理構造としてよく使われるものの例として、オンライン・トランザクション処理では第2回で解説した少数の行を特定するのに適する索引が使用され、分析系処理では第3回で扱った広範囲なデータ・アクセスの範囲を絞り込むパーティショニングが適用されます。これらを融合させるだけでもデータベース・エンジンによって実装レベルが異なります。個々の機能ごとなら「実装しています」と言えても、ほとんどのデータベース・エンジンは1つの表に複数のアクセス・パターンのための最適化実装を共存させることができていません。これが特定の用途に特化したデータベース・エンジンです。これに対し「複数用途の最適化を1つの表に実装することでマルチモデル/マルチワークロードに対応する」概念をOracle AI DatabaseではConverged Databaseと呼んでいます。
システムの拡張や改修にともない、データ量の増加やアクセス・パターンが変化します。今後のシステム・アーキテクチャ全体にかかわる変化として、AIエージェントがデータベースにアクセスするようになります。AIエージェントにとっては、どのデータベースがどの処理用途に最適化されているかは関係なく、SQLの処理モデルの原点に立ち返った「こういうデータが欲しい」というリクエストをデータベースに発行します。このとき、膨大なリソースをもつハードウェアが使用できるという前提においては、追加した機能に合わせてデータベースを新たに追加してデータの複製を増やすのではなく、データの整合性を考慮すると既存のデータベースでも対応できることが望ましく、そのアクセス・パターン変化と負荷の増加に対応できるデータベース・エンジンが必要なのです。

