







































はじめに
Jakarta CommonsはJakartaのさまざまなプロジェクトで使われている再利用可能なクラスの集まりですが、独立したコンポーネントとして自分のJavaプロジェクトの中でも利用できます。本稿はJakarta Commonsのさまざまなコンポーネントを紹介する3回シリーズの第2回です。このシリーズでは実際のサンプルアプリケーションを通じてJakarta Commonsコンポーネントの使い方を説明しています(前回の記事を読むには、ここをクリック)。これらのサンプルは、Jakarta Commonsコンポーネントを例示するだけのものではなく、各自のJavaプロジェクトで再利用できる完全なアプリケーションです。
本稿では次のコンポーネントを取り上げます。
- Codec
- DBCP
- DBUtils
- i18n
本稿には完全なソースコードが付属しています。ソースコードを実際に試すには、ダウンロードしたzipファイルをローカルドライブに展開し、各サンプルのテストケースをJUnitで実行してください。
Codec
Commons Codecには、フォネティックエンコーダ、HexおよびBase64エンコーダ、URLエンコーダといった、一般的なエンコード/デコードアルゴリズムが含まれています。フォネティックエンコーダは言語エンコーダで、検索エンジン、スペルチェック関数、デジタル辞書などのアプリケーションで利用できます。HexおよびBase64エンコーダは、文字を使ってバイナリデータを表現するアプリケーションで利用できます。URLエンコーダはさらにいくつかの機能を持っており、JDKのURLEncoderおよびURLDecoderクラスの代替と考えられます。
このコンポーネントにはDigestUtilsクラスも含まれており、SHAおよびMD5ダイジェストを作成するのに利用できます。次のセクションで、これらのクラスの使い方を実際のサンプルで示します。
言語エンコーダ
フォネティックアルゴリズムは発音が似ている単語を判別するのに使われます。入力された単語に対して代替案を提示するワープロアプリケーションが格好の例と言えるでしょう。Commons Codecには、Soundex、Metaphone、RefinedSoundex、DoubleMetaphoneという4つのクラスが含まれています。各クラスは別々のアルゴリズムを使って、ある単語の発音が別の単語と似ているかどうかを判別します。これらのアルゴリズムの説明を読むと、MetaphoneのほうがSoundexよりも正確だとわかります。
最初のサンプルアプリケーションでは、似通った単語から綴りの誤った単語を判定するためにSoundexクラスを使用しています。また、Strategyデザインパターンを使ってアルゴリズムを選択するようになっているので、他の3つのクラスのアルゴリズムをサポートするようにアプリケーションを修正することも可能です(このアプリケーションのクラスはソースコードの「src」フォルダ内のパッケージ「in.co.narayanan.commons.codec」に収められています)。
「words.txt」ファイルには短い単語リストが含まれています。Wordsクラスは、このファイルからの単語リストのロードを抽象化しており、IWordsインターフェイスに従っています。WordsAssistantはアプリケーションのエントリポイントクラスです。このクラスはSoundexアルゴリズムの1つを使って似通った単語を調べ、IWordsインターフェイスによって、それらの単語にアクセスします。リスト1はWordsAssistantクラス内のgetSimilarWordsメソッドの実装です。これはSoundexStrategyクラスからストラテジを選び、単語を繰り返し調べて一致するものを探します。このとき、ISimilarWordStrategyインターフェイス内のisSimilarメソッドを呼び出して一致するものを判別します。それから一致する単語をリストに追加し、呼び出し元に返します。
ISimilarWordStrategy strategy =
SoundexStrategy.getStrategy(type);
List<String> similarWords = new ArrayList<String>();
// Iterate the words and append similar words to the list
// and return
Iterator<String> wordsList = words.getWords().iterator();
String fileWord;
while(wordsList.hasNext()) {
fileWord = wordsList.next();
try {
if(strategy.isSimilar(searchWord, fileWord)) {
similarWords.add(fileWord);
}
} catch (WordsAssistantException e) {
throw new WordsAssistantException(
"Unable to determine similar words", e);
}
}
return similarWords;
SoundexStrategyクラスとCharDiffStrategyクラスはISimilarWordStrategyインターフェイスに実装を提供し、CommonsのSoundexクラスを使用します。リスト2はISimilarWordStrategyインターフェイスの定義です。このインターフェイスにisSimilarメソッドを実装すれば、新しいストラテジをサンプルアプリケーションにプラグインすることができます。
public interface ISimilarWordStrategy { boolean isSimilar(String word1, String word2) throws WordsAssistantException; }
リスト3では、org.apache.commons.codec.language.Soundexクラス内のsoundexメソッドが単語間での発音の類似性を調べます。このメソッドは似通った単語について同一となるコードを返し、それらを比較して単語どうしが似ているかどうかを判定します。たとえば、「compont」「component」「compenent」という単語なら、このコードはA515になります。
private static class SoundexStrategy extends SimilarWordStrategy { public boolean isSimilar(String word1, String word2) throws WordsAssistantException { return soundex.soundex(word1).equals( soundex.soundex(word2)); } }
リスト4では、org.apache.commons.codec.language.Soundexクラス内のdifferenceメソッドが0~4の数を返します。4は一致度が最も高く、0は一致度が最も低いことを表します。このサンプルではピボットを2に設定しています。JUnitテストケースクラスTestLanguageEncodersはメインクラスメソッドgetSimilarWordsを呼び出すことにより、このアプリケーションのデモを実行します。
private static class CharDiffStrategy extends SimilarWordStrategy { private static final int DIFF_RANGE = 2; public boolean isSimilar(String word1, String word2) throws WordsAssistantException { try { return (soundex.difference(word1, word2) > DIFF_RANGE) ? true : false; } catch (EncoderException e) { throw new WordsAssistantException( "Unable to determine the similarity", e); } } }
バイナリエンコーダ
バイナリエンコーダはバイナリデータをASCII形式で伝送するのに利用できます。たとえば、XMLに格納されたデジタル名刺にイメージを添付する必要がある場合、バイナリエンコーダはアルゴリズムの1つを使ってイメージのバイナリデータをエンコードし、それを専用のタグでXMLファイルに追加することができます。
「org.apache.commons.codec.binary」パッケージには、Base64、BinaryCodec、Hexというクラスが含まれており、それぞれがバイナリデータの異なるエンコード方法を表現しています。サンプルアプリケーションではBase64アルゴリズムを使用しており、これによりバイナリファイルをエンコードしてXMLに格納します。XMLファイルには、検索可能な名前/値ペアの形式でデータを記述したメタデータが含まれます。
in.co.narayanan.commons.codec.WrapItクラスは、このサンプルで使用する唯一のクラスです。これはバイナリファイルをエンコードし、XMLコンテンツとともにメタデータを作成します。リスト5は、このクラスによって生成されるサンプルXMLです。
<data> <meta-data> <entry name='keywords' value='Image, Personal, Face, Profile'/> <entry name='filename' value='test.bmp'/> <entry name='author' value='Narayanan A R'/> </meta-data> <binary> Qk0+QwAAAAAAADYAAAAoAAAASQAAAE4AAAABABgAAAAAAAhDAAAAAAAAAAAAAADLMjC7MhCLEZB7AWBK8QAa0LAX0HAUUDla6Y7vLw7vLw7vLw7vHx7vHx7vHx7vHx7v
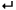 DLMjC7MhCLEZB7AWBK8QAa0LAX0HAUUDla6Y7vLw7vLw7vLw7vHx7vHx7vHx7vHx7v
DLMjC7MhCLEZB7AWBK8QAa0LAX0HAUUDla6Y7vLw7vLw7vLw7vHx7vHx7vHx7vHx7v エンコードされたバイナリデータは<binary>タグで囲まれています。メタデータは一連の<entry>タグとして表現されています。バイナリコンテンツをエンコードしてXMLファイルに格納すると、インターネットでの伝送が簡単になります。たとえば、処理のためにWebサービスレイヤに送られるXMLのVisaアプリケーションフォームで、イメージや、履歴書、卒業証明書などのバイナリコンテンツを伝送することができます。
リスト6はWrapItクラスから抜粋したコードで、これにより一度に1,024バイトを読み取って実際のエンコードを行います。ファイルから読み取った最後のデータ群に対して一度だけtruncateBytesメソッドを呼び出します。encodeBase64Chunked静的メソッドはエンコードされたコンテンツを76文字のブロックに分割して可読性を高めます。メタデータはXML形式のデータを検索可能できるようにします。
while((bytesRead=inputStream.read(binaryData)) != -1) { if(bytesRead < 1024) { encodedBinaryData = Base64.encodeBase64Chunked( truncateBytes(binaryData, bytesRead)); } else { encodedBinaryData = Base64.encodeBase64Chunked(binaryData); } encodedData.write(encodedBinaryData); }
URLエンコーダ
org.apache.commons.codec.net.URLCodecクラスは、文字列、オブジェクト、またはバイト配列に対するwww-form-urlencodedエンコード方式を実装しています。このクラスは、JDKのURLEncoderクラスと次の点で異なります。
- 指定された文字セットに対してエンコードとデコードを実行できる。
- 文字列に加え、オブジェクトやバイト配列にも有効。
このクラスのサンプルはありません。javadocのURLCodecを見れば容易に理解できるからです。

