サンプルアプリケーションの概要
今回作成するアプリケーションは、以下の3つのアプリケーション(サブ機能)で構成されます。
① 「IoTデバイスのデータを受信してデータベースに保存する」アプリケーション
② 「蓄積されたデータおよび随時更新されるデータをグラフとして可視化する」アプリケーション
③ 「過去データを元に機械学習モデルを用いて故障予測を行う」アプリケーション
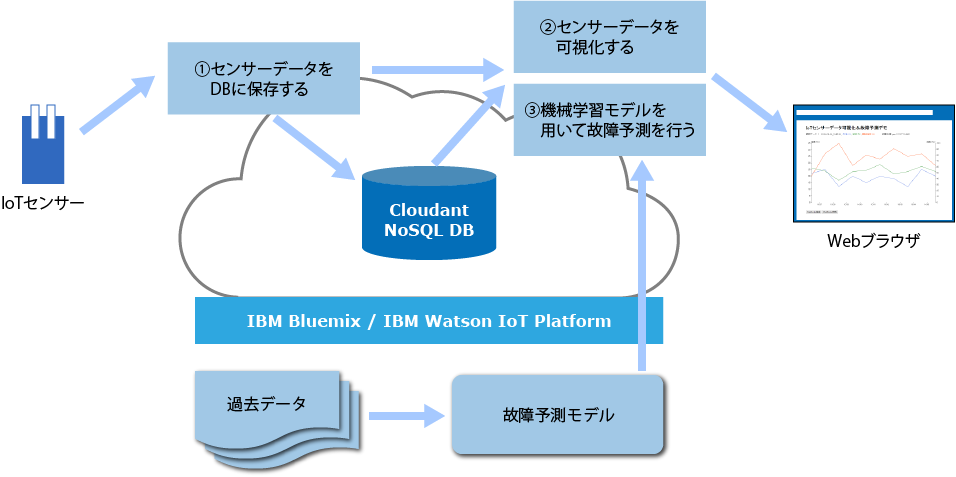
また、アプリケーションの全体像は図1のようになっています。
図1:アプリケーション全体像
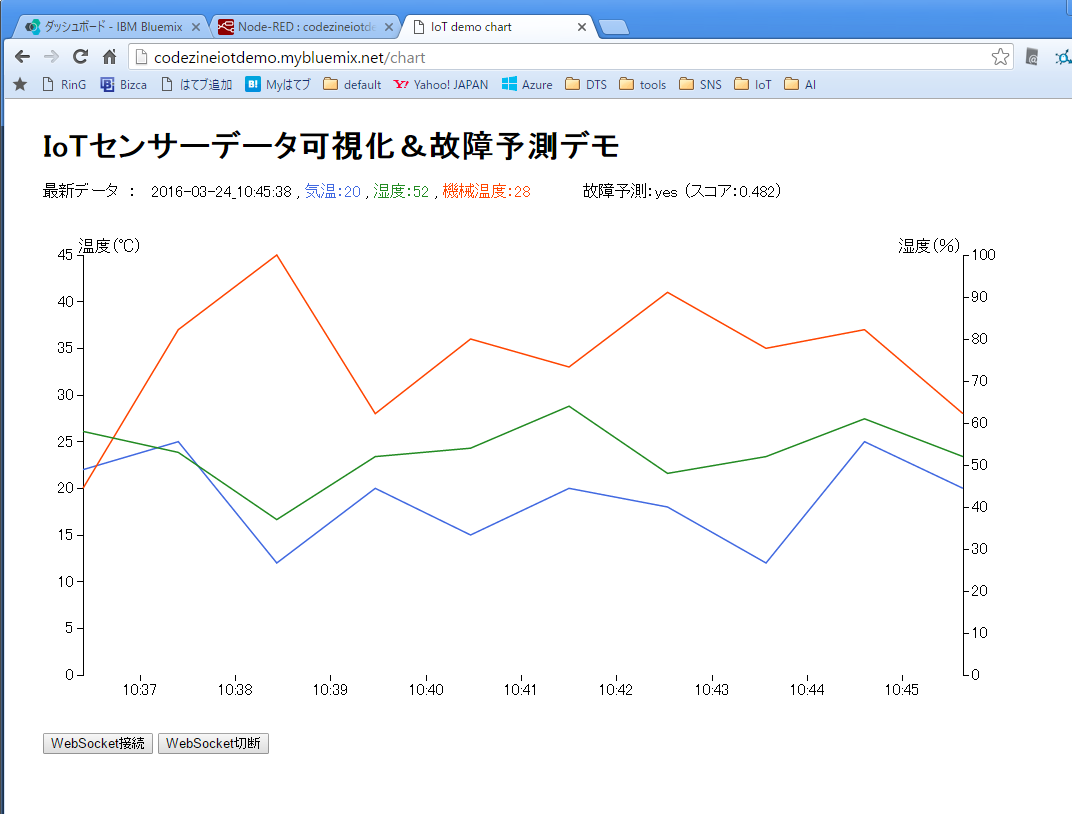
完成したアプリケーションは、画面1のようなグラフと故障予測有無を表示します。
画面1:完成したアプリケーションのスクリーンショット
「IoTデバイスのデータを受信してデータベースに保存する」アプリケーション
センサーデバイスの準備
まず、センサーデータを送信するデバイスを準備する必要があります。ArduinoやRasberryPiなどを利用することができますが、今回は本連載第2回に引き続き「IoTセンサーシミュレーター 」を利用します。
Webブラウザで開いたIoTセンサーシミュレーターは、開いている間ずっと、次の3つのデータを取得・送信し続けます。
気温(Temperature)
湿度(Humidity)
機器温度(Object Temperature)
IoTセンサーシミュレーター(画面2)は、画面の左右ボタンで気温・湿度・機器温度を切り替えられ、それぞれ画面の上下ボタンで値(温度や湿度)を変更することができます[1]
画面2:センサーシミュレーターの画面
アプリケーション本体の作成
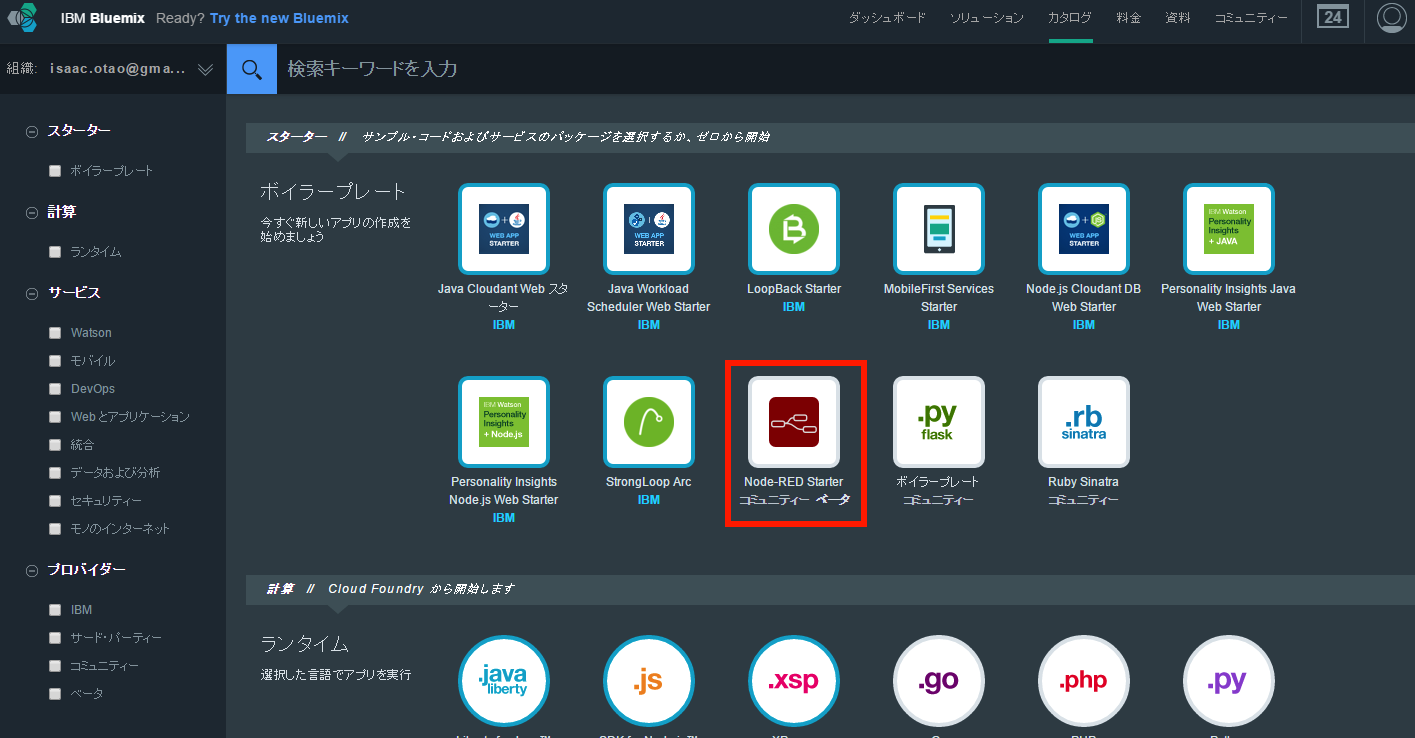
次に、アプリケーション本体を作成します。Bluemixにログインし、カタログ画面 から「ボイラープレート」の中にある「Node-RED Starter」を選択します(画面3)。
画面3:「ボイラープレート」の中にある「Node-RED Starter」を選択
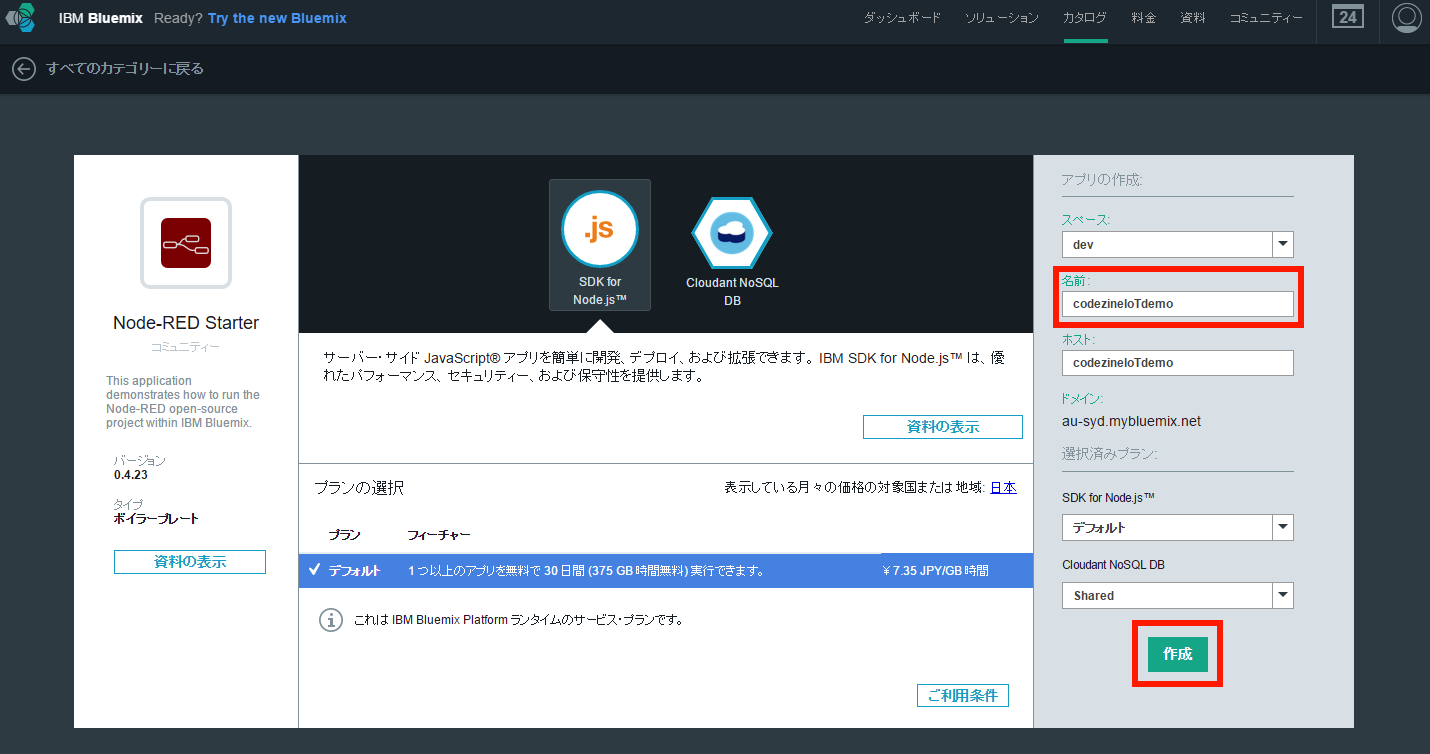
Node-REDアプリ作成画面にて、アプリケーションの名前を指定します。この名前は後にアプリケーションを公開する際のURLになります。なお、画面中央を見ると、開発SDKとして「Node.js」、データストアとして「Cloudant NoSQL DB」が利用されていることがわかります。名前を入力したら「作成」ボタンを押します(画面4)。
画面4:アプリケーションの名前を指定
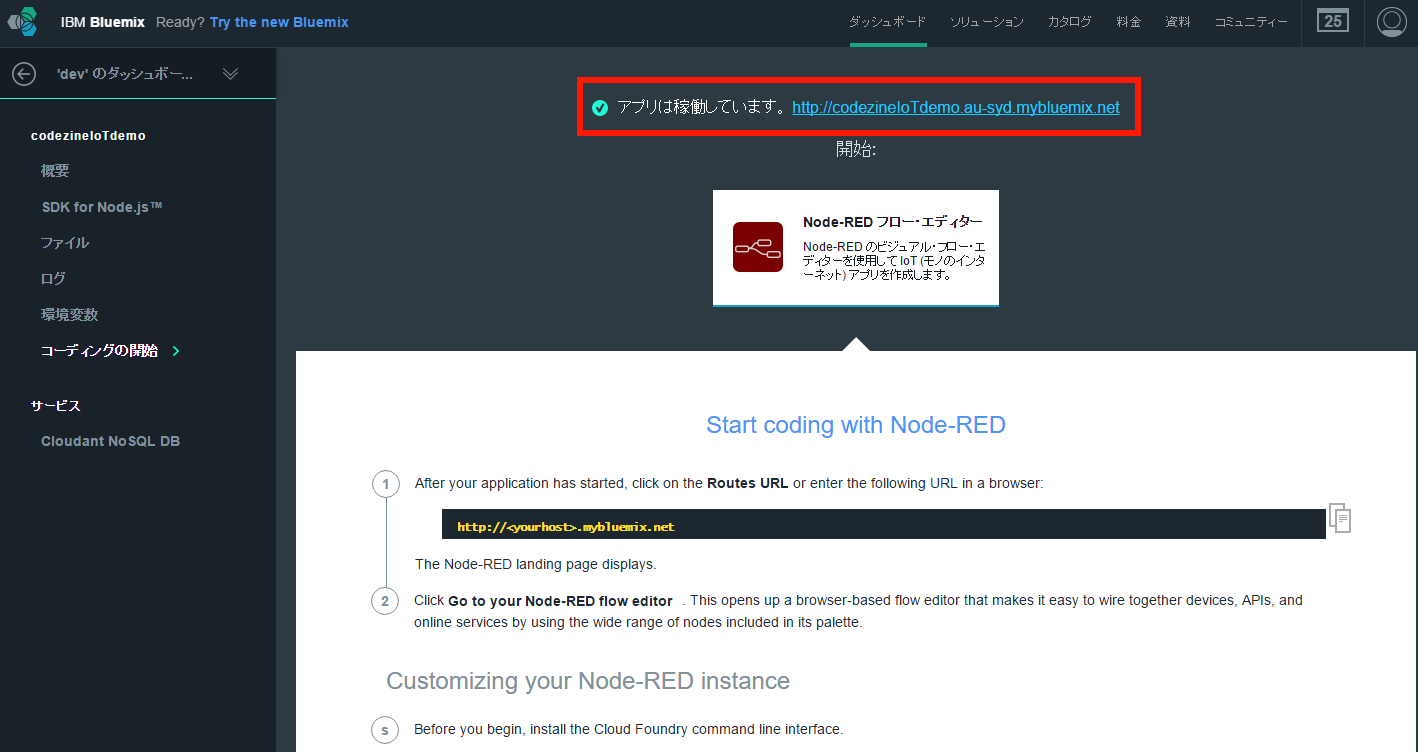
次の画面でしばらく待つと「アプリは稼働しています」と表示されます。先ほど指定した名前が含まれたアプリケーションのURLも、その右に表示されるのでクリックします(画面5)。
画面5:先ほど指定した名前が含まれたアプリケーションのURLをクリック
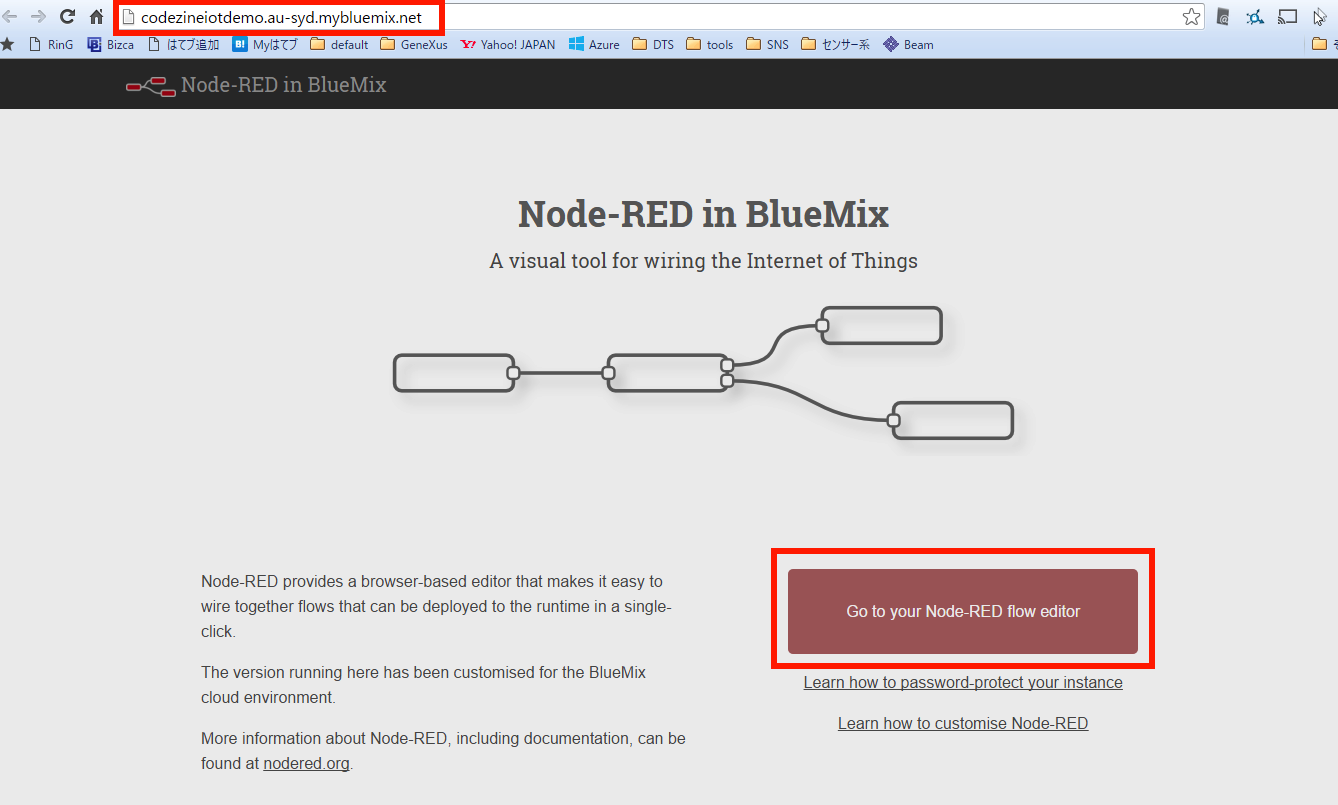
すると、別ウィンドウでアプリのデフォルト画面が表示されます。ブラウザのアドレスバーを見ると、自分のアプリケーションのURLとなっていることがわかります。「Go to your Node-RED flow editor」をクリックしてください(画面6)。
画面6:「Go to your Node-RED flow editor」をクリック
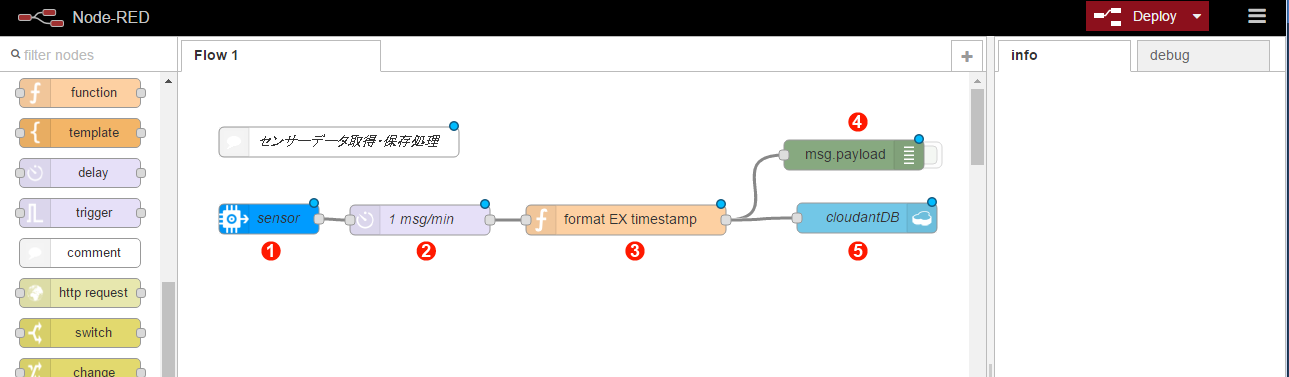
Node-REDのフローエディター画面が表示されますので、画面7のように「センサーデータ取得・保存処理」フローを作成してください。フローの作成は、画面左側にあるノードパレットで使用するノードを選んで、画面中央のワークスペースに配置し、他のノードと線でつなぐとともに、配置したノードに必要な設定を行うという手順で進めていきます。詳しくは、本連載第2回 をご覧ください。第2回に記載されているフローエディターのログインユーザー名とパスワードの設定も行うことをお勧めします。
画面7:「センサーデータ取得・保存処理」フロー
なお、本記事のサンプルファイル「codezine_iotdemo_nodered_app1.json」を使って、フローエディターにフローをインポートすることもできます。インポートの方法も同じく本連載第2回をご覧ください。
画面7のようにノードを配置したら、各ノードをダブルクリックして以下の内容を確認・設定します。
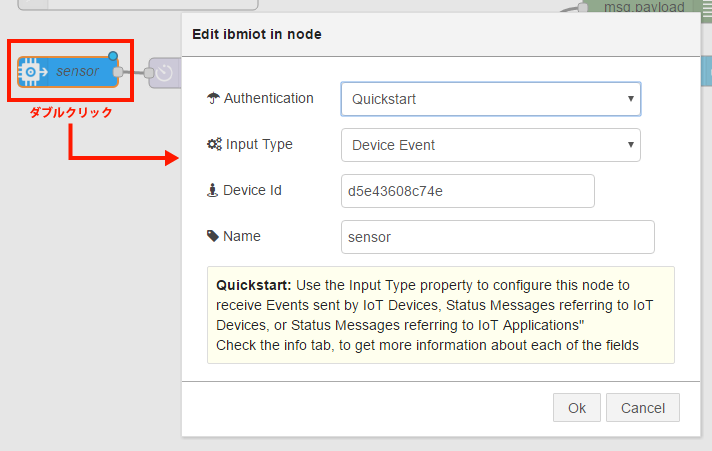
① input >「ibmiot」ノード
Authentication: Quickstart
Input Type: Device Event
Device Id: 先ほどシミュレーターでメモしたMACアドレス
Name: 任意(画面7では「sensor」)
画面8:① input >「ibmiot」ノードの設定
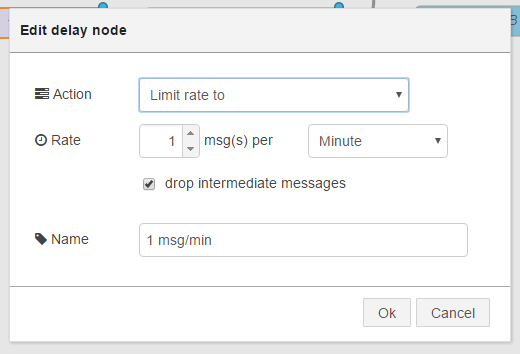
② function >「delay」ノード
Action: Limit rate to
Rate: 1 msg(s) per Minute
「drop intermediate messages」にチェック
Name: 任意(画面7では「1 msg/min」)
画面9:② function >「delay」ノードの設定
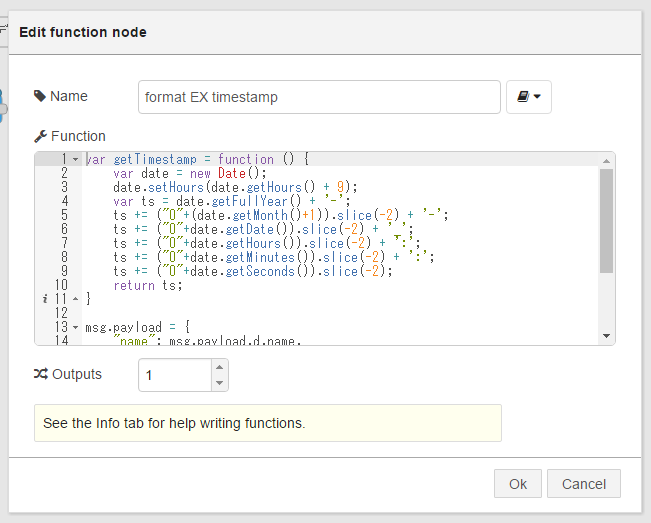
③ function >「function」ノード
Name: 任意(画面7では「format EX timestamp」)
Function: 後に示すコードを入力
Outputs: 1
Function欄に入力するコード
var getTimestamp = function () {
var date = new Date();
date.setHours(date.getHours() + 9);
var ts = date.getFullYear() + '-';
ts += ("0"+(date.getMonth()+1)).slice(-2) + '-';
ts += ("0"+date.getDate()).slice(-2) + '_';
ts += ("0"+date.getHours()).slice(-2) + ':';
ts += ("0"+date.getMinutes()).slice(-2) + ':';
ts += ("0"+date.getSeconds()).slice(-2);
return ts;
}
msg.payload = {
"name": msg.payload.d.name,
"timestamp": getTimestamp(),
"temp": msg.payload.d.temp,
"humidity": msg.payload.d.humidity,
"objectTemp": msg.payload.d.objectTemp
};
return msg;
このfunctionノードで、データベースに保存する名前と値の内容を作成しています。今回はセンサーデータの気温・湿度・機器温度の他に、nameとしてセンサーのMACアドレス、timestampとしてセンサーデータ受信の時刻を設定しています。
画面10:③ function >「function」ノードの設定
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
「IoTデバイスのデータを受信してデータベースに保存する」アプリケーション(続き)
アプリケーション本体の作成(続き)
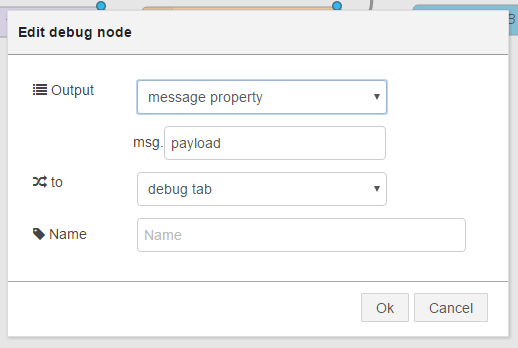
④ output >「debug」ノード
デフォルトのままでOKです(画面11はデフォルト値)。
Output: message property
to: debug tab
画面11:output >「debug」ノードの設定。デフォルトのままでOK
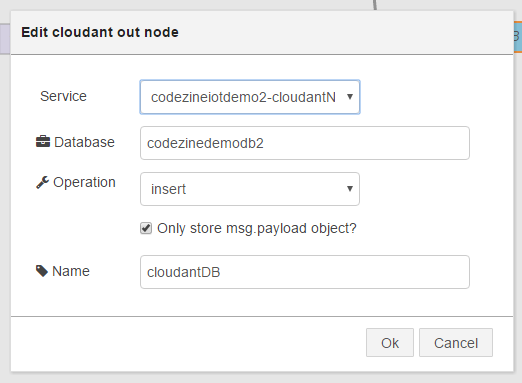
⑤ storage >「cloudant」ノード
cloudantノードには2種類ありますが、ここは端子が1つだけのものを使います。
Service: 自動で割り振り(「作成したアプリケーション名-cloudantNOSQLDB」という形式)
Database: 任意の名前。必須(画面7では「codezinedemodb2」)
Operation: insert
「Only store msg.payload object?」にチェック
Name: 任意(画面7では「cloudantDB」)
Database欄には、本来であればBluemixのサービスとして提供されているCloudantのデータベースを作成して、その名前を指定しますが、ここで指定することで後ほど(Deploy実行時)アプリケーション用のデータベースが新規に作成されます。
画面12:⑤ storage >「cloudant」ノードの設定
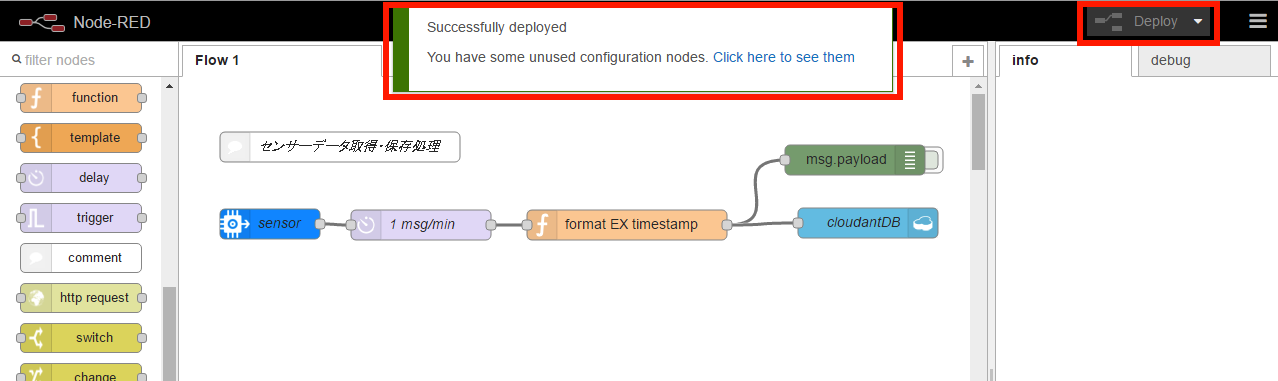
ここまで入力・確認できたら、フローエディター画面右上の「Deploy」ボタンを押すと、アプリケーションがビルドされてサーバー上にデプロイされます。現時点では、UIがないのでサーバー上でバックエンド処理を行うアプリケーションということになります。
「Deploy」ボタンを押してしばらく待つと、デプロイ成功のメッセージが表示されます(画面13)。
画面13:デプロイ成功のメッセージが表示
動作確認
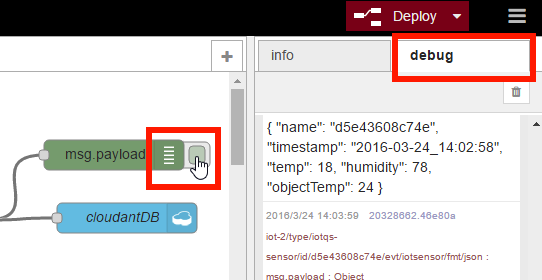
デプロイが成功したら、動作確認を行います。debugノードの右側にあるタブのようなスイッチでデバッグ出力のON/OFFを切り替えることができます。デバッグ出力をONにして、フローエディター右側の「debug」タブを選択すると、デバッグメッセージが表示されます(画面14)。
画面14:デバッグ出力の切り替えとデバッグメッセージの表示
IoTセンサーシミュレーターのウィンドウで気温・湿度・機器温度を変更すると、デバッグ出力されている値も変更されていることが確認できると思います。ただし、このアプリケーションではセンサーデータを1分ごとに受け取るようにしている(delayノードの処理)ことに注意してください。
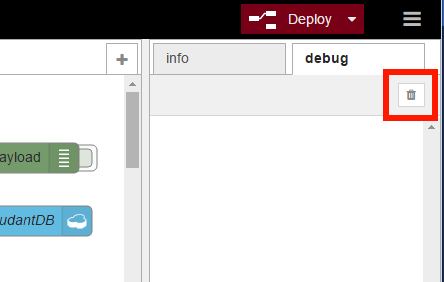
デバッグメッセージの確認が終わったら、デバッグ出力をOFFにしておきましょう。また、「debug」タブのゴミ箱アイコンをクリックすると「debug」タブをクリアすることができます(画面15)。
画面15:「debug」タブのクリア
センサーデータをアプリケーションが受け取っていることが確認できたので、次はデータベースへ保存されていることを確認します。
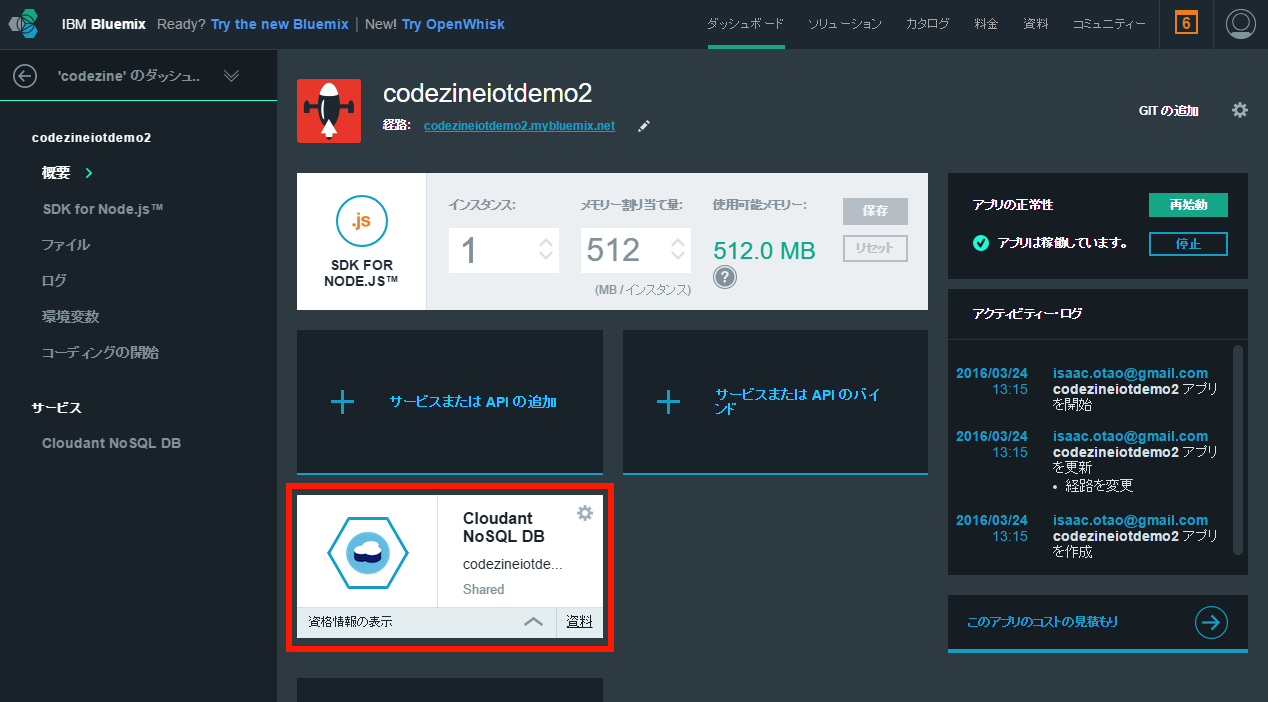
Bluemixのコンソール画面 を開き、上部のメニューから「ダッシュボード」をクリックし、現在作成したアプリケーションを選択すると次の画面に移るので「Cloudant NoSQL DB」をクリックします(画面16)。
画面16:Bluemixのコンソール画面で「Cloudant NoSQL DB」をクリック
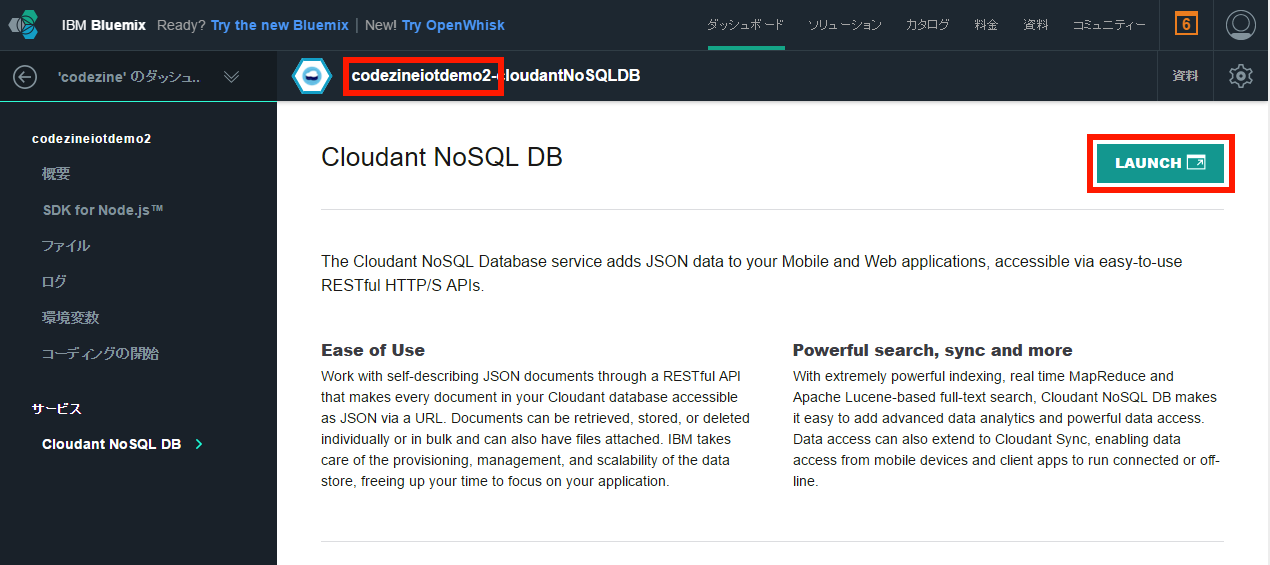
Cloudantインスタンスの画面が表示されるので、今回作成したアプリケーション名が表示されていることを確認して、右側の「LAUNCH」ボタンをクリックします(画面17)。
画面17:アプリケーション名を確認して「LAUNCH」ボタンをクリック
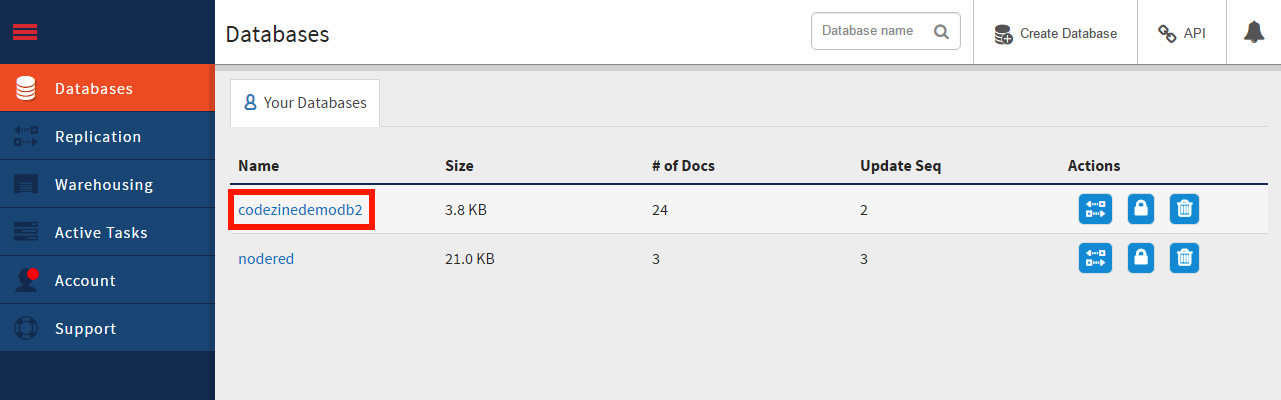
別ウィンドウでCloudant Dashboard画面が開きます。先ほどフローエディターで設定した名前のデータベース(ここではcodezinedemodb2)があるので、それをクリックします(画面18)。
画面18:フローエディターで設定した名前のデータベースをクリック
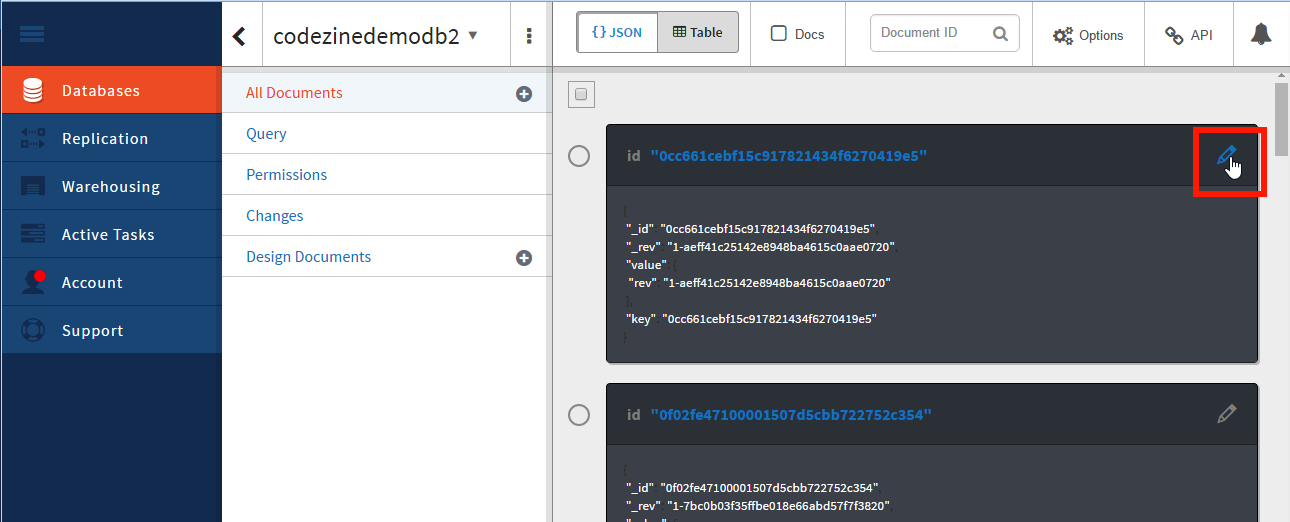
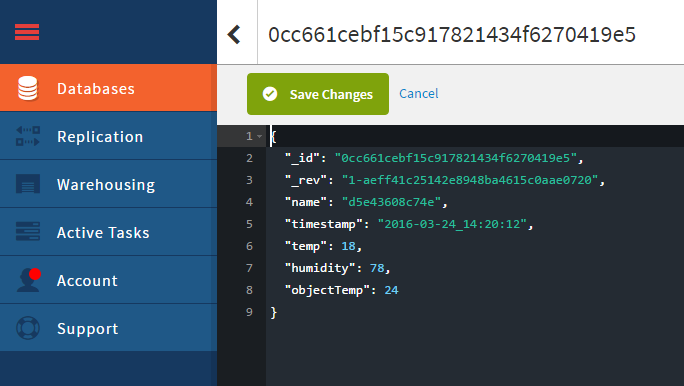
開いた画面で、Cloudantの各データベースに格納されているデータやインデックスを確認できます。画面右側には、格納されているデータが一覧で表示されています。各データの右端にある「Edit document」とツールチップ表示されるペンのアイコンをクリックすると、各データの内容を確認できます(画面19)。
画面19:Cloudantのデータベースに格納されているデータを確認する
画面20のように各データの内容が表示されます。Debugタブに出力されていたのと同様、name、timestamp、temp、humidity、objectTempが含まれていればOKです。
画面20:設定したデータベースに保存されているデータの内容
ここまでで、第1段階の「IoTデバイスのデータを受信してデータベースに保存する」アプリケーションは終了です。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
「蓄積されたデータおよび随時更新されるデータをグラフとして可視化する」アプリケーション
次に作成するのは、一言で言えば「データベースの内容をグラフ表示するWebアプリケーション」です。「D3.js」というJavaScriptライブラリを使って、第一段階でデータベースに格納されたデータをグラフ化します。
D3.jsのD3とは「Data Driven Document」のことで、強力なデータおよびドキュメント操作が可能です。ニューヨーク・タイムズ紙のWebサイトやOpen Street Mapの編集用エディター、ソーシャルグラフなど様々な用途で使われています。公式サイト のExampleには、様々な事例が掲載されています。今回はD3.jsを使って、基本的な折れ線グラフ(Line Chart)を作成します。
画面21:D3.jsの公式サイト
「蓄積されたデータおよび随時更新されるデータをグラフとして可視化する」アプリケーションの作成は、次の4ステップで進めます。
① Cloudantのインデックス作成
② Cloudantからデータを取得する処理の作成
③ Webアプリケーション本体の作成
④ センサーデータが更新されるたびにグラフを更新する処理の作成
Cloudantのインデックス作成
Cloudantでは検索処理を行うために、検索対象となる項目のインデックスを作成する必要があります。今回はTimestampによって最新レコードを取得するため、Timestampのインデックスを作成します。Cloudanat Dashboardのデータベース画面にて、「Design Documents」の「+」アイコンをクリックし「New Search Index」を選択します(画面22)。
画面22:Cloudantのインデックス作成
「Create Search Index」タブが開くので、以下の値を設定して「Save Document and Build Index」をクリックして、設定をセーブします。
「Create Search Index」タブ
_design/: index
Index name: 任意だが必須(画面23ではIndexByTimestamp)
Search index function: 後に示すコードを入力
Analyzer: Single
Type: Keyword
Search index function欄に入力するコード
function (doc) {
index("timestamp", doc.timestamp, {"store": true});
}
画面23:「Create Search Index」タブの設定
セーブすると、インデックスが作成されます(画面24)。
画面24:インデックスが作成された
Cloudantからデータを取得する処理の作成
続いて、作成したインデックスを用いてCloudantからデータを取得する処理を作成します。Node-REDフローエディターを開き、画面25に示すフローを作成してください。本記事の添付ファイル(codezine_iotdemo_nodered_app2-a.json)からインポートすることもできます。
画面25:インデックスを用いてCloudantからデータを取得する処理のフロー
各ノードをダブルクリックして、次のように設定を確認・編集してください。
① input >「Inject」ノード
デフォルトのままでOKです。
② function >「function」ノード
Name: 任意(画面25では「search param」)
Function: 後に示すコードを入力
Function欄に入力するコード
msg.payload = {
"query": "timestamp: 2016*",
"sort" : "-timestamp<string>",
"limit": 2
};
return msg;
ここでは、Cloudantの検索APIに対するパラメーターを指定しています。「timestampで2016が先頭一致するデータを、降順でソートして、2件取得」という意味です。
画面26:Cloudantの検索APIに対するパラメーターを指定
③ storage >「cloudant」ノード
今回は両側に端子が付いているノードを使います。
Service: プルダウンで「本アプリケーション名-cloudantNoSQLDB」を選択
Database: 先ほど作成したデータベース名
Search by: search indexindex / 先ほど作成したインデックス名(例えば IndexByTimestamp)
Name: 任意(画面25では「cloudant」)
画面27:③ storage >「cloudant」ノードの設定
④ output >「debug」ノード
デフォルトのままでOKです。
各ノードの確認・編集が終わったら「Deploy」して、動作確認します。Injectノードのボタンを押すと処理が実行され、Cloudantからのレスポンスが「debug」タブに表示されます(画面28)。
画面28:Cloudantからのレスポンスが「debug」タブに表示される
Cloudantからは、次のようなJSON形式の配列データが返ってきます。確認が終わったら、debugノードの出力をOFFにしておきましょう。
[
{ "_id": "36e86023793826c0feed6d98bfdbbfbf",
"_rev": "1-17e5db35ee9966970c48f810b02f325c",
"name": "d5e43608c74e",
"timestamp": "2016-03-24_17:23:02",
"temp": 18,
"humidity": 78,
"objectTemp": 24
},
{ "_id": "292064bfb6ee841d0e47c3aea48e3219",
"_rev": "1-dcb4ff5982f6574d5e85b1ddc1423521",
"name": "d5e43608c74e",
"timestamp": "2016-03-24_17:22:02",
"temp": 18,
"humidity": 78,
"objectTemp": 24
}
]
クエリを実行してCloudantからデータを取得することが確認できたので、グラフを表示するWebアプリケーションは、この処理をAjaxで呼び出す仕組みで実装します。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
「蓄積されたデータおよび随時更新されるデータをグラフとして可視化する」アプリケーション(続き)
Webアプリケーション本体の作成
では、Webアプリケーション本体を作成していきます。Node-REDフローエディターで、画面29に示すフローを作成してください。本記事の添付ファイル(codezine_iotdemo_nodered_app2-b.json)からインポートすることもできます。
画面29:Webアプリケーション本体のフローを作成
各ノードの設定を確認・編集していきます。最初に、「Cloudantからデータ取得処理」フローを修正します。
① input >「http」ノード
Injectノードと差し替えて、functionノード(「search param」)につなげます。
Method: GET
URL: /data
Name: 任意(画面29では「[get] /data」)
ここで指定したURLは、Ajaxによるデータ取得処理の呼び出しで使います。
画面30:① input >「http」ノードの設定
② functionノード(「search param」)
Function欄に入力するコード
msg.payload = {
"query": "timestamp: 2016*",
"sort" : "-timestamp<string>",
"limit": msg.payload.num
};
return msg;
HTTPリクエストのパラメーターとして"num"を設定することで、取得する件数を動的に指定できるようにしています。
上述したhttpノードで設定したURLと合わせて、例えば10件データを取得するためには次のURLをAjaxで発行すればよいことになります。
画面31:② functionノード(「search param」)の設定
③ output >「http response」ノード
画面側へレスポンスを返すために新規に追加して、Cloudantノードの出力側へつなげます。http responseノードは特に設定する項目はありません。
また、以前の手順でつなげてあったdebugノードはそのまま残しておいて構いません。
次に、「Webアプリケーション」フローを追加します。
④ input >「http」ノード
Method: GET
URL: /
Name: 任意(画面29では「[get]/」)
グラフ表示するページのURLをここで設定します。上記設定の場合は作成したアプリケーションのルートとなります(例 http://codezineiotdemo.mybluemix.net/)。例えば、ここで「/chart」を設定すると、「http://codezineiotdemo.mybluemix.net/chart」がページのURLとなります。
画面32:④ input >「http」ノードの設定
⑤ function >「template」ノード
Name: 任意(画面29では「index.html」。.htmlはなくても構いません)
set property: msg.payload(デフォルトのまま)
Template: 後に示すコードを入力(サンプルファイル「index_app2-b.html」)
Format: Mustache template(デフォルトのまま)
Template欄に入力するコード(▼クリックするとプルダウンしてコードが表示されます)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<!-- jQuery -->
<script src="http://code.jquery.com/jquery-1.12.0.min.js"></script>
<!-- d3.js -->
<script src="http://d3js.org/d3.v3.min.js" charset="utf-8"></script>
<title>IoT demo chart</title>
<style>
.axis path,
.axis line {
fill: none;
stroke: #000;
shape-rendering: crispEdges;
}
.x.axis path {
display: none;
}
.line {
fill: none;
stroke: royalblue;
stroke-width: 1.5px;
}
.line2 {
fill: none;
stroke: orangered;
stroke-width: 1.5px;
}
.line3 {
fill: none;
stroke: forestgreen;
stroke-width: 1.5px;
}
</style>
<script type="text/javascript">
//グラフ用のデータ配列
var data = [];
window.addEventListener('load', function () {
//Cloudant APIのURL
var recordnum = 10;
var dataurl = "./data?num=" + recordnum;
//Cloudantからデータ取得して初期表示
d3.json(dataurl, function(datas){
//console.log("===== d3.json ========");
//console.log(datas);
//JSONで取得する項目はそのまま使えるのでグラフ用配列にセット
data = datas;
//配列の順序を入れ替えてセット→D3.jsがよしなにしてくれるので不要
// for (var i in datas){
// data.unshift(datas[i]);
// }
//console.log("==== data object =====");
//console.log(data);
//グラフ描画処理
drawInitialChart();
//最新データを表示
var dispdata = {
timestamp : formatDateTime(new Date(datas[0].timestamp)),
temp : datas[0].temp,
humidity : datas[0].humidity,
objectTemp : datas[0].objectTemp
};
disp_info(dispdata);
});
});
</script>
</head>
<body>
<div style="margin:30px;">
<h1>IoTセンサーデータ可視化デモ</h1>
<div>
<p>最新データ :
<span id="latestts">timestamp</span>
, <span style="color:royalblue;">気温:<span id="latesttemp">xx</span></span>
, <span style="color:forestgreen;">湿度:<span id="latesthum">xx</span></span>
, <span style="color:orangered;">機械温度:<span id="latestot">xx</span></span>
</p>
</div>
<div id="chartarea"></div>
<p></p>
</div>
<script>
//D3.js 初期処理
//表示サイズを設定
var areasize = {width: 960, height: 500};
var margin = {top: 40, right: 40, bottom: 40, left: 40};
//グラフ表示用の高さと幅
var chartwidth = areasize.width - margin.left - margin.right;
var chartheight = areasize.height - margin.top - margin.bottom;
var formatDateTime = d3.time.format("%Y-%m-%d_%H:%M:%S");
var parseDate = d3.time.format("%Y-%m-%d_%H:%M:%S").parse;
//SVG領域の設定
var svg = d3.select("#chartarea").append("svg")
.attr("width", areasize.width)
.attr("height", areasize.height)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
var x = d3.time.scale()
.range([0, chartwidth]);
var y = d3.scale.linear()
.range([chartheight, 0]);
var y2 = d3.scale.linear()
.range([chartheight, 0]);
var xAxis = d3.svg.axis()
.scale(x)
.orient("bottom");
//.orient("bottom")
//.tickFormat(d3.time.format("%m/%d_%H:%M"));
//温度のY軸(左側)
var yAxis = d3.svg.axis()
.scale(y)
.orient("left");
//湿度のY軸(右側)
var yAxis2 = d3.svg.axis()
.scale(y2)
.orient("right");
//ライン・気温
var line = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y(d.temp); });
//ライン・機器温度
var line2 = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y(d.objectTemp); });
//ライン・湿度
var line3 = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y2(d.humidity); });
//グラフの初期描画処理 データ取得後にコールされる
function drawInitialChart(){
//console.log("===== drawInitialChart ======");
data.forEach(function(d){
d.timestamp = parseDate(d.timestamp);
d.temp = +d.temp;
d.objectTemp = +d.objectTemp;
d.humidity = +d.humidity;
});
//X軸のドメイン=Timestampの最小値と最大値
x.domain(d3.extent(data, function(d){ return d.timestamp; }));
//Y軸のドメイン=0から、気温Maxと機器温度Maxの大きい方
var maxtemp = d3.max(data, function(d){ return d.temp; });
var maxobjtemp = d3.max(data, function(d){ return d.objectTemp; });
var max_y = maxtemp > maxobjtemp ? maxtemp : maxobjtemp;
y.domain([0, max_y]);
//Y軸(湿度)は0-100固定
y2.domain([0, 100]);
//X軸 描画
svg.append("g")
.attr("class", "x axis")
.attr("transform", "translate(0, " + chartheight + ")")
.call(xAxis);
//Y軸(左) 描画
svg.append("g")
.attr("class", "y axis")
.call(yAxis)
.append("text")
.attr("transform", "translate(60,-20) rotate(0)")
.attr("y", 6)
.attr("dy", ".7em")
.style("text-anchor", "end")
.text("温度(℃)");
//Y軸(右) 描画
svg.append("g")
.attr("class", "y axis")
.attr("transform", "translate(" + chartwidth + " ,0)")
.call(yAxis2)
.append("text")
.attr("transform", "translate(0,-20) rotate(0)")
.attr("y", 6)
.attr("dy", ".7em")
.style("text-anchor", "end")
.text("湿度(%)");
svg.append("path")
.datum(data)
.attr("class", "line")
.attr("d", line);
svg.append("path")
.datum(data)
.attr("class", "line2")
.attr("d", line2);
svg.append("path")
.datum(data)
.attr("class", "line3")
.attr("d", line3);
}
//最新データ表示
function disp_info(wsdata){
$("#latestts").text(wsdata.timestamp);
$("#latesttemp").text(wsdata.temp);
$("#latesthum").text(wsdata.humidity);
$("#latestot").text(wsdata.objectTemp);
}
</script>
</body>
</html>
以下、コードの説明です。
12~41行目 :D3.jsのグラフ用CSSの設定です。.lineが気温、.line2が機器温度、.line3が湿度の線となり、分かりやすくするためにそれぞれ色を変えています。
49~77行目 :Cloudantのデータを取得するためのAjax発行処理です。D3.jsでは、54行目の「d3.json(dataurl, function(datas){・・・}という一行の表記だけでdataurlのAjaxを発行してJSON形式の戻り値dataを得て、「・・・」の処理を行う、ということが指定できます。取得したデータを使ってグラフ描画の処理を行いますので、グラフ描画処理はこのd3.jsonのfunctionブロック内に記述します。
103~155行目 :D3.jsの初期処理(共通設定)です。今回は、1つのエリアに3つ線があり、かつ温度(気温、機器温度)と湿度という2軸(Y軸が2つ)というグラフになっているので、その分、設定項目は増えています。
159~221行目 :グラフの描画処理です。Ajax発行ブロック内からコールされます。170~178行目で設定しているドメインというのは、グラフのX軸・Y軸の値の範囲です。180~205行目でX軸・Y軸を描画して、207~220行目でラインを描画しています。
画面33:⑤ function >「template」ノードの設定
⑥ output >「http response」ノード
設定する項目はありません。
ここまで確認・編集できたら動作確認します。Webブラウザで、本アプリケーションのルートURL(例 http://codezineiotdemo.mybluemix.net/)にアクセスし、画面34のようなグラフが表示されれば成功です。
画面34:このようなグラフが表示されたら動作確認は成功
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
「蓄積されたデータおよび随時更新されるデータをグラフとして可視化する」アプリケーション(続き)
センサーデータが更新されるたびにグラフを更新する処理の作成
第2段階の最後のステップは、センサーデータが更新されるたびにグラフを更新する処理の作成です。この処理にはWebSocketを使います。Node-REDフローエディターで既存のフローに対し、画面35で赤く囲った部分を追加・修正してください。本記事のサンプルファイル(codezine_iotdemo_nodered_app2-c.json)からインポート(追加・修正部分のみ)することもできます。
画面35:「センサーデータが更新されるたびにグラフを更新する処理の作成」のための追加・修正部分
ここで行うのは、2つのノードの追加・変更のみです。
① output >「websocket」ノードの追加
「format EX timestamp」のfunctionノードから接続します。websocketノードをダブルクリックして以下を設定します。
Type: Listen on
Path: /ws/sensor(ペンアイコンをクリックして追加してください)
Name: 任意(画面35では「websocket」)
画面36:output >「websocket」ノードの設定
画面37:Path欄の設定。WecSocketリスナーの新規追加
② 「Template」ノード(index.html)の修正
Template: 後に示すコードを入力(サンプルファイル「index_app2-c.html」)
Template欄に入力するコード(▼クリックするとプルダウンしてコードが表示されます)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<!-- jQuery -->
<script src="http://code.jquery.com/jquery-1.12.0.min.js"></script>
<!-- d3.js -->
<script src="http://d3js.org/d3.v3.min.js" charset="utf-8"></script>
<title>IoT demo chart</title>
<style>
.axis path,
.axis line {
fill: none;
stroke: #000;
shape-rendering: crispEdges;
}
.x.axis path {
display: none;
}
.line {
fill: none;
stroke: royalblue;
stroke-width: 1.5px;
}
.line2 {
fill: none;
stroke: orangered;
stroke-width: 1.5px;
}
.line3 {
fill: none;
stroke: forestgreen;
stroke-width: 1.5px;
}
</style>
<script type="text/javascript">
//グラフ用のデータ配列
var data = [];
//WebSocket接続用 Node-REDで生成した文字列を指定
var wsUrl = 'ws://codezineiotdemo.mybluemix.net/ws/sensor';
var socket;
window.addEventListener('load', function () {
//Cloudant APIのURL
var recordnum = 10;
var dataurl = "./data?num=" + recordnum;
//Cloudantからデータ取得して初期表示
d3.json(dataurl, function(datas){
//console.log("===== d3.json ========");
//console.log(datas);
//JSONで取得する項目はそのまま使えるのでグラフ用配列にセット
data = datas;
//配列の順序を入れ替えてセット→D3.jsがよしなにしてくれるので不要
// for (var i in datas){
// data.unshift(datas[i]);
// }
//console.log("==== data object =====");
//console.log(data);
//グラフ描画処理
drawInitialChart();
//最新データを表示
var dispdata = {
timestamp : formatDateTime(new Date(datas[0].timestamp)),
temp : datas[0].temp,
humidity : datas[0].humidity,
objectTemp : datas[0].objectTemp
};
disp_info(dispdata);
});
});
</script>
</head>
<body>
<div style="margin:30px;">
<h1>IoTセンサーデータ可視化デモ</h1>
<div>
<p>最新データ :
<span id="latestts">timestamp</span>
, <span style="color:royalblue;">気温:<span id="latesttemp">xx</span></span>
, <span style="color:forestgreen;">湿度:<span id="latesthum">xx</span></span>
, <span style="color:orangered;">機械温度:<span id="latestot">xx</span></span>
</p>
</div>
<div id="chartarea"></div>
<p></p>
<div>
<button onclick="wsConnect()">WebSocket接続</button>
<button onclick="wsDisconnect()">WebSocket切断</button>
<span id="con-msg">message</span>
</div>
</div>
<script>
//D3.js 初期処理
//表示サイズを設定
var areasize = {width: 960, height: 500};
var margin = {top: 40, right: 40, bottom: 40, left: 40};
//グラフ表示用の高さと幅
var chartwidth = areasize.width - margin.left - margin.right;
var chartheight = areasize.height - margin.top - margin.bottom;
var formatDateTime = d3.time.format("%Y-%m-%d_%H:%M:%S");
var parseDate = d3.time.format("%Y-%m-%d_%H:%M:%S").parse;
//SVG領域の設定
var svg = d3.select("#chartarea").append("svg")
.attr("width", areasize.width)
.attr("height", areasize.height)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
var x = d3.time.scale()
.range([0, chartwidth]);
var y = d3.scale.linear()
.range([chartheight, 0]);
var y2 = d3.scale.linear()
.range([chartheight, 0]);
var xAxis = d3.svg.axis()
.scale(x)
.orient("bottom");
//.orient("bottom")
//.tickFormat(d3.time.format("%m/%d_%H:%M"));
//温度のY軸(左側)
var yAxis = d3.svg.axis()
.scale(y)
.orient("left");
//湿度のY軸(右側)
var yAxis2 = d3.svg.axis()
.scale(y2)
.orient("right");
//ライン・気温
var line = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y(d.temp); });
//ライン・機器温度
var line2 = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y(d.objectTemp); });
//ライン・湿度
var line3 = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y2(d.humidity); });
//グラフの初期描画処理 データ取得後にコールされる
function drawInitialChart(){
//console.log("===== drawInitialChart ======");
data.forEach(function(d){
d.timestamp = parseDate(d.timestamp);
d.temp = +d.temp;
d.objectTemp = +d.objectTemp;
d.humidity = +d.humidity;
});
//X軸のドメイン=Timestampの最小値と最大値
x.domain(d3.extent(data, function(d){ return d.timestamp; }));
//Y軸のドメイン=0から、気温Maxと機器温度Maxの大きい方
var maxtemp = d3.max(data, function(d){ return d.temp; });
var maxobjtemp = d3.max(data, function(d){ return d.objectTemp; });
var max_y = maxtemp > maxobjtemp ? maxtemp : maxobjtemp;
y.domain([0, max_y]);
//Y軸(湿度)は0-100固定
y2.domain([0, 100]);
//X軸 描画
svg.append("g")
.attr("class", "x axis")
.attr("transform", "translate(0, " + chartheight + ")")
.call(xAxis);
//Y軸(左) 描画
svg.append("g")
.attr("class", "y axis")
.call(yAxis)
.append("text")
.attr("transform", "translate(60,-20) rotate(0)")
.attr("y", 6)
.attr("dy", ".7em")
.style("text-anchor", "end")
.text("温度(℃)");
//Y軸(右) 描画
svg.append("g")
.attr("class", "y axis")
.attr("transform", "translate(" + chartwidth + " ,0)")
.call(yAxis2)
.append("text")
.attr("transform", "translate(0,-20) rotate(0)")
.attr("y", 6)
.attr("dy", ".7em")
.style("text-anchor", "end")
.text("湿度(%)");
svg.append("path")
.datum(data)
.attr("class", "line")
.attr("d", line);
svg.append("path")
.datum(data)
.attr("class", "line2")
.attr("d", line2);
svg.append("path")
.datum(data)
.attr("class", "line3")
.attr("d", line3);
}
//データ更新時の描画処理
function updateDraw() {
//console.log("===== updateDraw =======");
//console.log(data);
data.forEach(function(d){
d.timestamp = d.timestamp;
d.temp = +d.temp;
d.objectTemp = +d.objectTemp;
d.humidity = +d.humidity;
});
//ドメイン(入力値の範囲)更新
x.domain(d3.extent(data, function(d){ return d.timestamp; }));
var maxtemp = d3.max(data, function(d){ return d.temp; });
var maxobjtemp = d3.max(data, function(d){ return d.objectTemp; });
var max_y = maxtemp > maxobjtemp ? maxtemp : maxobjtemp;
y.domain([0, max_y]);
y2.domain([0, 100]);
//アニメーション宣言
svg = d3.select("#chartarea").transition();
svg.select(".line")
.duration(750)
.attr("d", line(data));
svg.select(".line2")
.duration(750)
.attr("d", line2(data));
svg.select(".line3")
.duration(750)
.attr("d", line3(data));
svg.select(".x.axis")
.duration(750)
.call(xAxis);
svg.select(".y.axis")
.duration(750)
.call(yAxis);
}
//接続・切断時のメッセージを表示
function disp_msg(str) {
var msgarea = $("#con-msg");
msgarea.text(str);
msgarea.stop().fadeIn(0).fadeOut(2000);
}
//最新データ表示
function disp_info(wsdata){
$("#latestts").text(wsdata.timestamp);
$("#latesttemp").text(wsdata.temp);
$("#latesthum").text(wsdata.humidity);
$("#latestot").text(wsdata.objectTemp);
}
//WebSocket接続
function wsConnect() {
socket = new WebSocket(wsUrl);
disp_msg('接続しました。');
socket.onmessage = function(e) {
var wsData = JSON.parse(e.data);
console.log("timestamp:" + wsData.timestamp + " , temp:" + wsData.temp);
//最新データの情報を表示
disp_info(wsData);
//グラフのデータを更新
//グラフ用のデータが新しい順になっているので、配列の先頭に追加する
data.unshift({
timestamp : parseDate(wsData.timestamp),
temp : wsData.temp,
humidity: wsData.humidity,
objectTemp: wsData.objectTemp
});
//配列の末尾を取り除く
data.pop();
//グラフ描画
updateDraw();
};
};
//WebSocket切断
function wsDisconnect() {
socket.close();
disp_msg('切断しました');
};
</script>
</body>
</html>
以下、コードの追加部分の説明です。
47~49行目 :WebSocketの接続用文字列とWebSocketオブジェクトを追加しています。接続用文字列は、
"ws://" + アプリケーションのURI + Node-REDのwebsocketノードで設定した文字列
となります(例 ws://codezineiotdemo.mybluemix.net/ws/sensor)。
101~105行目 :WebSocketの接続/切断用のボタンを追加。
231~273行目 :データ更新時のD3.jsによるグラフ描画処理。更新されたデータを使って、アニメーション処理で描画しています。
292~318行目 :WebSocket接続、受信時の処理。最新1件のデータをグラフ描画用の配列に追加して1件を取り除き、グラフ描画処理を呼び出しています。
ここまで確認・編集できたら動作確認します。Webブラウザで、本アプリケーションのルートURL(例 http://codezineiotdemo.mybluemix.net/)にアクセスします。画面38に示すようなグラフが表示された後に「WebSocket接続」ボタンを押して、しばらく待ってグラフが更新されれば成功です。
画面38:動作確認。グラフがこのように表示されればOK
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
「過去データを元に機械学習モデルを用いて故障予測を行う」アプリケーション
機械学習とは
いよいよ本アプリケーションも最終段階です。IoTのセンサーデータ活用において期待されている機能の一つが故障予測(予知保全)です。故障予測において近年注目の手法が機械学習です。機械学習は人工知能のベースとなる技術で、ある程度の数のサンプルデータ集合を入力して解析を行い、そのデータから有用な規則、ルール、知識表現、判断基準などを抽出するものです。検索エンジン、医療診断、スパムメールの検出、金融市場の予測、DNA配列の分類、音声認識や文字認識などのパターン認識、ゲーム戦略、ロボット制御などに使われています。
機械学習では、あるデータが入力として与えられたときにある答えを出力するシステムを「モデル」と呼びます。通常はこうした機能をもつプログラムを開発するわけですが、機械学習では基本的にユーザーはプログラムを作りません。その代わりに、機械学習アルゴリズムに基づくモデルに対して訓練用データを与えることでモデルが学習して、正しい答えを出力するようになることを期待します。
過去データの準備
故障予測を行うために過去データを準備する必要があります。即ち、過去のどんな状況で故障が発生していたかというデータを基に機械学習モデルを作成します。ただし、今回データベースに蓄積しているセンサーデータだけでは故障が発生していたかどうかという情報がないので、サンプルデータを作成します。
機械学習で用いる様々なデータセットが登録されているサイトが「UCI Machine Learning Repository 」です(画面39)。ここに、半導体製造プロセスに関するデータセット(SECOM Data Set)が登録されているので、今回はこのデータセットをベースに過去データを作成して故障予測を実施していきます。
画面39:UCI Machine Learning Repository
SECOM Data Set にはセンサーデータなど、591項目のデータが含まれているのですが、今回はその中から3項目を抽出して気温・湿度・機械の温度に置き換えたものを使用します。気温・湿度・機械の温度という3つの項目と、機械が故障した/していないという過去データを作成しました(添付ファイルのSECOM_DEMO_DATA.csv)。この過去データを使って機械学習モデルを作成していきます。
SPSS Modelerによる機械学習モデルの作成
機械学習を行うライブラリやツールはいろいろありますが、ここではBluemix上で提供されている「IBM Predictive Analytics」(予測分析)サービスで利用できる「IBM SPSS Modeler」を使います。
まず IBM Predictive Analyticsのページ を開きます。少しスクロールすると、SPSS Modelerのトライアル版を入手するための「TRY」ボタンがありますのでクリックします(画面40)。
画面40:SPSS Modelerトライアル版の入手
対応OSは、Windows XP以降の32bit版、64bit版、Mac OS Xです。ご自分の環境に合わせてダウンロードとインストールを実施してください(画面41)。
画面41:SPSS Modelerトライアル版のダウンロードページ
インストールできたらSPSS Modelerを起動します。スタート画面が表示されるので「新規ストリームを作成する」を選択して「OK」ボタンを押してください(画面42)。
画面42:SPSS Modelerを起動し「新規ストリームを作成する」を選択
SPSS Modelerは、Node-REDと同じような感じでGUIベースで処理フローを作成できます。ここでは画面43に示すフローを作成してください。各ノードをつないでいる矢印は、ノードを右クリックして表示されるメニューにて「接続」を選択してつなげる先のノードを指定します。
画面43:SPSS Modelerで作成する処理フロー
配置できたら、それぞれのノードをダブルクリックして設定していきます。
① 入力 >「可変長ファイル」
「ファイル」タブ
ファイル: ローカルPCに置いてある「SECOM_DEMO_DATA.csv」を指定
「行区切り文字は改行文字です」にチェック
フィールド区切り文字: カンマ
「データ型」タブ
「ロール」 seq_no:レコードID、failure:対象
画面44:「ファイル」タブで行う設定
画面45:「データ型」タブで行う設定
画面46:レコード設定 >「サンプリング」の設定
③ モデル作成 >「自動分類」
設定する項目はありません。「エキスパート」タブを選択すると、使用する候補のアルゴリズム(モデルタイプ)を見ることができます。この中から適切なものが選択されます。
画面47:モデル作成 >「自動分類」の設定
処理フローの設定まで終えたら、画面上部の「現在のストリームを実行」をクリックしてモデル作成を実行します(画面48)。
画面48:機械学習モデルの作成を実行
少し待つと、モデルが作成されます(画面49)。
画面49:機械学習モデルが作成された
作成されたモデルをダブルクリックすると、使われたアルゴリズム(モデル)を確認できます(画面50)。
画面50:使われたアルゴリズム(モデル)
学習した結果のモデルの精度を検証してみましょう。「精度分析」と「テーブル」をフローに追加して実行してください(画面51)。
画面51:「精度分析」と「テーブル」をフローに追加して実行
実行が終わると、結果のウィンドウが表示されます(画面52)。全体としての精度(予測が当たっている率)は約93%でした。テーブルのほうの結果では1レコードごとに予測結果が表示されます。
画面52:学習した結果のモデルの精度を検証した結果
予測モデルファイルの出力
次は、Bluemixで使用するための予測モデルファイルを出力します。新たにフィルターを追加します(画面53)。
画面53:フィルターの追加
フィルターをダブルクリックして「seq_no」と「failure」は対象外にします(画面54)。
画面54:「seq_no」と「failure」は対象外にする
テーブルを右クリックして、「スコアリング枝として使用」にチェックを入れます(画面55)。
画面55:「スコアリング枝として使用」にチェックを入れる
すると、スコアリングするフローの線が緑色になります。この操作を忘れるとBluemix上に予測モデルファイルをアップロードしてもスコアリング対象がないというエラーになるので注意してください。
メニューバーの「ファイル」または画面上の任意の場所を右クリックして「名前を付けてストリームを保存」を選択し、任意の名前を付けて予測モデルファイル(.strファイル)を保存します(画面56)。
画面56:「名前を付けてストリームを保存」を選択して予測モデルファイルを保存
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
「過去データを元に機械学習モデルを用いて故障予測を行う」アプリケーション(続き)
Predictive Analyticsサービスの登録
WebブラウザでBluemixのコンソールにログインし、ダッシュボードから本稿のサンプルアプリケーション(codezineIoTdemo)の画面を表示させて「+サービスまたはAPIの追加」を選択します(画面57)。
画面57:Bluemixのダッシュボードで本稿のアプリケーションを表示させ「+サービスまたはAPIの追加」を選択
カタログ画面が表示されるので、「Predictive Analytics」を選択します(画面58)。
画面58:カタログ画面で「Predictive Analytics」を選択
Predictive Analyticsの画面になるので、右側の「アプリ」に本稿のサンプルアプリケーション「CodeZine IoT demo Predict」が指定されていることを確認し、サービス名を任意で設定して「作成」ボタンをクリックします(画面59)。
画面59:本稿のサンプルアプリケーションが指定されていることを確認し「作成」ボタンをクリック
再ステージングが必要といわれた場合は再ステージングしてください(画面60)。
画面60:再ステージングが必要であることを伝えるメッセージ
しばらく待つと「アプリは稼働しています」と表示されるので、左のメニュー「サービス」に表示されている「Predictive Analytics」をクリックします(画面61)。
画面61:「Predictive Analytics」をクリック
Predictive Analyticsモジュールの画面が表示されます。先ほど入力した名前になっていることと、画面下部に「No Models, Yet」と表示されていることを確認し、画面下部の「New Model Stream」の「Select File」をクリックし、SPSS Modelerで作成した予測モデルファイル(サンプルファイル「secom_predict_model.str」)をアップロードします(画面62)。
画面62:SPSS Modelerで作成した予測モデルファイルをアップロード
Context Idを聞かれるので、任意の名前を付けて「Deploy」をクリックします(画面63)。
画面63:Context Idに任意の名前を付ける
すると、モデル登録されて「Manage Models」にて一覧表示に追加されます。「Deployed Model Usage」でPredictive Analyticsの利用状況(何回スコアリングが実施されたのか)がわかります。Freeプランでは毎月5000回までとなっています。
Predictive AnalyticsをAPIとして利用するための認証情報を確認します。画面左のメニューから「環境変数」を選択します(画面64)。
画面64:画面左のメニューから「環境変数」を選択
環境変数に、先ほど作成したPredictive Analyticsの認証情報が追加されています。アプリケーションからAPI利用をする際にaccess_keyとurlを利用するのでコピーしておきます(画面65)。
画面65:先ほど作成したPredictive Analyticsの認証情報。`access_key`と`url`をコピーしておく
Predictive Analyticsを呼び出して利用する
Node-REDのフローエディターを起動し、画面66のフローを作成してください。本記事のサンプルファイル「codezine_iotdemo_nodered_app3-a.json」をインポートすることもできます。
画面66:「Predictive Analyticsを呼び出して利用する」フロー
各ノードをダブルクリックして設定を確認・編集します。
① input >「Inject」ノード
デフォルトのままでOKです。
② function >「function」ノード
Name: 任意(画面66では「POST Parameter」)
Function: 後に示すコードを入力
Function欄に入力するコード
msg.payload = {
"tablename":"SECOM_DEMO_DATA.csv",
"header":["seq_no","failure","temperature","humidity","objecttemperature"],
"data":[["test1","",25,50,40]]
};
return msg;
API呼び出しにあたって、headerのほうで"seq_no"と"failure"も含める必要があるようですが、この2つの項目は予測には用いないのでダミーのデータで構いません。"temperature"以下3つの項目はとりあえず動作確認したいので直データを指定します。値は任意です。
画面67:function >「function」ノードの設定
③ function >「http request」ノード
両側に端子がついているノードです。
Method: POST
URL:「認証情報URL/score/コンテキストID?accesskey=認証情報アクセスキー」という形式で入力
【例】
https://palbyp.pmservice.ibmcloud.com/pm/v1/score/codezinepredict1?accesskey=tsiabababZ1TxWvabbabtstabbxogqabbimc/BuB1U284a+WZII4a8o25pvJYhSGzcpmqjabbmlwVtsabbPiHxGxQ3pIogjgEOjN0TGtsTcL0h32gVzPabwMbmHXNpi+HL4aabtst4aPabGZUtstXsOpV+04Mu/ngj4ajy8qabbab4WCLtst4ITE1+S/abb4LjOWjtsZg8ZPabs6B3E=)
「Use basic authentication?」にチェックなし
Return: a parsed JSON object
Name: 任意(画面66では「[post] Predict API」)
画面68:function >「http request」ノードの設定
④ output >「debug」ノード
デフォルトのままでOKです。
ここまで確認・編集できたら動作確認を行います。Deploy後、debugノードの出力をONにしてInjectノードをクリックすると処理が実施されます。Predictive Analytics APIの呼び出しに成功すると、Debugタブに以下のようなAPI結果が表示されます。
msg.payload : array [1]
[ { "header": [ "temperature", "humidity", "objecttemperature", "$XF-failure", "$XFC-failure" ], "data": [ [ 25, 50, 40, "yes", 0.4914826378710285 ] ] } ]
入力した値("temperature", "humidity", "objecttemperature")に基づいて予測した結果("$XF-failure", "$XFC-failure")が出力されます。$XF-failureは予測した故障の有無(yes/no)、$XFC-failureは予測に対する確信度(0~1)です。
予測結果が取得できることが確認できたので、あとはセンサーデータの値をパラメーターとしてAPIを呼び出すように変更してあげればOKです。
WebアプリケーションからのPredictive Analytics呼び出し
いよいよラストです。ブラウザにてNode-REDフローエディターを開いて、画面69に示すフローを作成してください。本記事の添付ファイル(codezine_iotdemo_nodered_all.json)をインポートすることもできます。
画面69:「WebアプリケーションからのPredictive Analytics呼び出し」フロー
各ノードをダブルクリックして設定を確認・編集していきます。
① input >「http」ノード
Injectノード(Timestamp)と差し替えます。
Method: GET
URL: /predict
Name: 任意(画面69では「[get]/predict」)
画面70:input >「http」ノードの設定
② function >「function」ノード
Name: 任意(画面69では「POST Parameter」)
Function: 後に示すコードを入力。これにより、HTTPリクエストのパラメーターで気温・湿度・機器温度を指定できるようにします。
Function欄に入力するコード
msg.payload = {
"tablename":"SECOM_DEMO_DATA.csv",
"header":["seq_no","failure","temperature","humidity","objecttemperature"],
"data":[["test1","",
msg.payload.param_temp,
msg.payload.param_hum,
msg.payload.param_objt
]]
return msg;
画面71:function >「function」ノードの設定
③ output >「http response」ノード
Predicitive Analyticsを呼び出しているpostノード(Predict API)からつなげます。設定はデフォルトのままでOKです。
また、「Webアプリケーション」フローも次のように修正します。
④ 「Template」ノード(「index.html」)
Template: 後に示すコードを入力(サンプルファイル「index_app3-b.html」)
Template欄に入力するコード(▼クリックするとプルダウンしてコードが表示されます)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<!-- jQuery -->
<script src="http://code.jquery.com/jquery-1.12.0.min.js"></script>
<!-- d3.js -->
<script src="http://d3js.org/d3.v3.min.js" charset="utf-8"></script>
<title>IoT demo chart</title>
<style>
.axis path,
.axis line {
fill: none;
stroke: #000;
shape-rendering: crispEdges;
}
.x.axis path {
display: none;
}
.line {
fill: none;
stroke: royalblue;
stroke-width: 1.5px;
}
.line2 {
fill: none;
stroke: orangered;
stroke-width: 1.5px;
}
.line3 {
fill: none;
stroke: forestgreen;
stroke-width: 1.5px;
}
</style>
<script type="text/javascript">
//グラフ用のデータ配列
var data = [];
//WebSocket接続用 Node-REDで生成した文字列を指定
var wsUrl = 'ws://codezineiotdemo2.mybluemix.net/ws/sensor';
var socket;
window.addEventListener('load', function () {
//Cloudant APIのURL
var recordnum = 10;
var dataurl = "./data?num=" + recordnum;
//Cloudantからデータ取得して初期表示
d3.json(dataurl, function(datas){
//console.log("===== d3.json ========");
//console.log(datas);
//JSONで取得する項目はそのまま使えるのでグラフ用配列にセット
data = datas;
//配列の順序を入れ替えてセット→D3.jsがよしなにしてくれるので不要
// for (var i in datas){
// data.unshift(datas[i]);
// }
//console.log("==== data object =====");
//console.log(data);
//グラフ描画処理
drawInitialChart();
//最新データを表示
var dispdata = {
timestamp : formatDateTime(new Date(datas[0].timestamp)),
temp : datas[0].temp,
humidity : datas[0].humidity,
objectTemp : datas[0].objectTemp
};
disp_info(dispdata);
});
});
</script>
</head>
<body>
<div style="margin:30px;">
<h1>IoTセンサーデータ可視化&故障予測デモ</h1>
<div>
<p>最新データ :
<span id="latestts">timestamp</span>
, <span style="color:royalblue;">気温:<span id="latesttemp">xx</span></span>
, <span style="color:forestgreen;">湿度:<span id="latesthum">xx</span></span>
, <span style="color:orangered;">機械温度:<span id="latestot">xx</span></span>
<span> </span>
故障予測:<span id="predict_failure"></span>
(スコア:<span id="predict_score"></span>)
</p>
</div>
<div id="chartarea"></div>
<p></p>
<div>
<button onclick="wsConnect()">WebSocket接続</button>
<button onclick="wsDisconnect()">WebSocket切断</button>
<span id="con-msg">message</span>
</div>
</div>
<script>
//D3.js 初期処理
//表示サイズを設定
var areasize = {width: 960, height: 500};
var margin = {top: 40, right: 40, bottom: 40, left: 40};
//グラフ表示用の高さと幅
var chartwidth = areasize.width - margin.left - margin.right;
var chartheight = areasize.height - margin.top - margin.bottom;
var formatDateTime = d3.time.format("%Y-%m-%d_%H:%M:%S");
var parseDate = d3.time.format("%Y-%m-%d_%H:%M:%S").parse;
//SVG領域の設定
var svg = d3.select("#chartarea").append("svg")
.attr("width", areasize.width)
.attr("height", areasize.height)
.append("g")
.attr("transform", "translate(" + margin.left + "," + margin.top + ")");
var x = d3.time.scale()
.range([0, chartwidth]);
var y = d3.scale.linear()
.range([chartheight, 0]);
var y2 = d3.scale.linear()
.range([chartheight, 0]);
var xAxis = d3.svg.axis()
.scale(x)
.orient("bottom");
//.orient("bottom")
//.tickFormat(d3.time.format("%m/%d_%H:%M"));
//温度のY軸(左側)
var yAxis = d3.svg.axis()
.scale(y)
.orient("left");
//湿度のY軸(右側)
var yAxis2 = d3.svg.axis()
.scale(y2)
.orient("right");
//ライン・気温
var line = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y(d.temp); });
//ライン・機器温度
var line2 = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y(d.objectTemp); });
//ライン・湿度
var line3 = d3.svg.line()
.x(function(d){ return x(d.timestamp); })
.y(function(d){ return y2(d.humidity); });
//グラフの初期描画処理 データ取得後にコールされる
function drawInitialChart(){
//console.log("===== drawInitialChart ======");
data.forEach(function(d){
d.timestamp = parseDate(d.timestamp);
d.temp = +d.temp;
d.objectTemp = +d.objectTemp;
d.humidity = +d.humidity;
});
//X軸のドメイン=Timestampの最小値と最大値
x.domain(d3.extent(data, function(d){ return d.timestamp; }));
//Y軸のドメイン=0から、気温Maxと機器温度Maxの大きい方
var maxtemp = d3.max(data, function(d){ return d.temp; });
var maxobjtemp = d3.max(data, function(d){ return d.objectTemp; });
var max_y = maxtemp > maxobjtemp ? maxtemp : maxobjtemp;
y.domain([0, max_y]);
//Y軸(湿度)は0-100固定
y2.domain([0, 100]);
//X軸 描画
svg.append("g")
.attr("class", "x axis")
.attr("transform", "translate(0, " + chartheight + ")")
.call(xAxis);
//Y軸(左) 描画
svg.append("g")
.attr("class", "y axis")
.call(yAxis)
.append("text")
.attr("transform", "translate(60,-20) rotate(0)")
.attr("y", 6)
.attr("dy", ".7em")
.style("text-anchor", "end")
.text("温度(℃)");
//Y軸(右) 描画
svg.append("g")
.attr("class", "y axis")
.attr("transform", "translate(" + chartwidth + " ,0)")
.call(yAxis2)
.append("text")
.attr("transform", "translate(0,-20) rotate(0)")
.attr("y", 6)
.attr("dy", ".7em")
.style("text-anchor", "end")
.text("湿度(%)");
svg.append("path")
.datum(data)
.attr("class", "line")
.attr("d", line);
svg.append("path")
.datum(data)
.attr("class", "line2")
.attr("d", line2);
svg.append("path")
.datum(data)
.attr("class", "line3")
.attr("d", line3);
}
//データ更新時の描画処理
function updateDraw() {
console.log("===== updateDraw =======");
console.log(data);
data.forEach(function(d){
d.timestamp = d.timestamp;
d.temp = +d.temp;
d.objectTemp = +d.objectTemp;
d.humidity = +d.humidity;
});
//ドメイン(入力値の範囲)更新
x.domain(d3.extent(data, function(d){ return d.timestamp; }));
var maxtemp = d3.max(data, function(d){ return d.temp; });
var maxobjtemp = d3.max(data, function(d){ return d.objectTemp; });
var max_y = maxtemp > maxobjtemp ? maxtemp : maxobjtemp;
y.domain([0, max_y]);
y2.domain([0, 100]);
//アニメーション宣言
svg = d3.select("#chartarea").transition();
svg.select(".line")
.duration(750)
.attr("d", line(data));
svg.select(".line2")
.duration(750)
.attr("d", line2(data));
svg.select(".line3")
.duration(750)
.attr("d", line3(data));
svg.select(".x.axis")
.duration(750)
.call(xAxis);
svg.select(".y.axis")
.duration(750)
.call(yAxis);
}
//接続・切断時のメッセージを表示
function disp_msg(str) {
var msgarea = $("#con-msg");
msgarea.text(str);
msgarea.stop().fadeIn(0).fadeOut(2000);
}
//最新データ表示
function disp_info(wsdata){
$("#latestts").text(wsdata.timestamp);
$("#latesttemp").text(wsdata.temp);
$("#latesthum").text(wsdata.humidity);
$("#latestot").text(wsdata.objectTemp);
}
//WebSocket接続
function wsConnect() {
socket = new WebSocket(wsUrl);
disp_msg('接続しました。');
socket.onmessage = function(e) {
var wsData = JSON.parse(e.data);
console.log("timestamp:" + wsData.timestamp + " , temp:" + wsData.temp);
//最新データの情報を表示
disp_info(wsData);
//グラフのデータを更新
//グラフ用のデータが新しい順になっているので、配列の先頭に追加する
data.unshift({
timestamp : parseDate(wsData.timestamp),
temp : wsData.temp,
humidity: wsData.humidity,
objectTemp: wsData.objectTemp
});
//配列の末尾を取り除く
data.pop();
//グラフ描画
updateDraw();
//Predictive Analytics呼び出し
$.ajax({
url: "./predict",
data: {
"param_temp" : wsData.temp,
"param_hum" : wsData.humidity,
"param_objt" : wsData.objectTemp
}
}).done(function(result){
console.log("===== Predictive Analytics Call ======");
console.log(result);
//alert("success!");
$("#predict_failure").text(result[0].data[0][3]);
$("#predict_score").text( (Math.round( result[0].data[0][4] * 1000) /1000) );
}).fail(function(result){
alert("error!");
});
};
};
//WebSocket切断
function wsDisconnect() {
socket.close();
disp_msg('切断しました');
};
</script>
</body>
</html>
以下、コードの追加部分の説明です。
96~98行目 :故障予測の結果を表示する領域です。
323~339行目 :Predictive Analyticsを呼び出す処理です。WebSocketで受け取った最新のデータをHTTPリクエストのパラメーターとしてセットして呼び出しています。
では、確認が終わったらDeployして動作確認します。Webブラウザで、本プリケーションのルートURL(例 http://codezineiotdemo.mybluemix.net/)にアクセスします。画面72のようなグラフが表示された後に「WebSocket接続」ボタンを押して、しばらく待ってグラフが更新され、故障予測結果が表示されれば成功です。
画面72:このような故障予測結果が表示されれば成功
これで今回のアプリケーション構築は完了です。いかがでしたでしょうか? 比較的簡単にクラウド上に保存したIoTセンサーデータを可視化したり、分析したりすることができたと思います。それでは皆さんも、Let's enjoy IoT!!
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)