




































「唯一の“源泉”」を創るデータ統合プロジェクトが必要だった理由とは
損保ジャパンをはじめとする国内損害保険事業のほか、国内生命保険、海外保険、介護・シニア事業など、幅広い領域でさまざまな事業を手がけているSOMPOホールディングス。なかでも斎藤氏が所属する「SOMPO Digital Lab」は、SOMPOグループのDX推進を担うイノベーション部門だ。

SOMPOホールディングス株式会社 デジタル・データ戦略部
シニア・データアーキテクト 兼 シニア・データエンジニア 斎藤 友樹氏
同部門には、デジタルやデータの深い知見を持つ専門人材が多数在籍し、グループ各社の課題解決に向けて伴走しながらプロジェクトを推進している。そのうちのひとつが、今回紹介されたデータ統合プロジェクトである。
なぜこのプロジェクトが立ち上がったのか。まずは保険事業でどのようなデータが扱われているのか、ざっくりと把握しておこう。
保険契約が成立すると、代理店によって、契約者や契約内容などの情報を“収入系”のデータベースに登録する「契約計上」という処理が行われる。一方で、事故が発生して保険金の支払いをする際には、事故の担当者が“出金系”のデータベースに記録する。これらのデータは、入出金や請求などを処理する「清算・収納システム」や、販売実績や営業実績を集計する「成績システム」などの業務処理を担う中間システムを経由し、さらにその一部のデータは経理会計システムにも供給されている。
これらのデータは、部門ごとに保有する個別のシステムを通じて活用されていたが、システムによってデータの定義や集計方法、集計タイミングなどにばらつきが生じ、数値の不整合による混乱を招いていた。また、このような状況からデータのサイロ化が起き、システムやデータに関する知見やノウハウが部門内に閉じてしまっていたことから、組織全体としてのデータ活用が進まない状態に陥っていた。

「この状況を打破するためにやるべきことは、ただひとつ。今まで分断された環境で運用されていた部門ごとのシステムを段階的に統廃合し、共通のロジックで定義されたビューを通じて、誰もが同じ品質・定義のデータにアクセスできる状態を目指すことにした」(斎藤氏)
データの本質を理解するには現場の業務プロセスの理解が不可欠
斎藤氏は、「(1)データ/品質の調査(2)パイプライン作成(3)カタログ作成(4)データマート公開」の4つのステップでプロジェクトを進めていったという。最初の2ステップを詳しく紹介する。
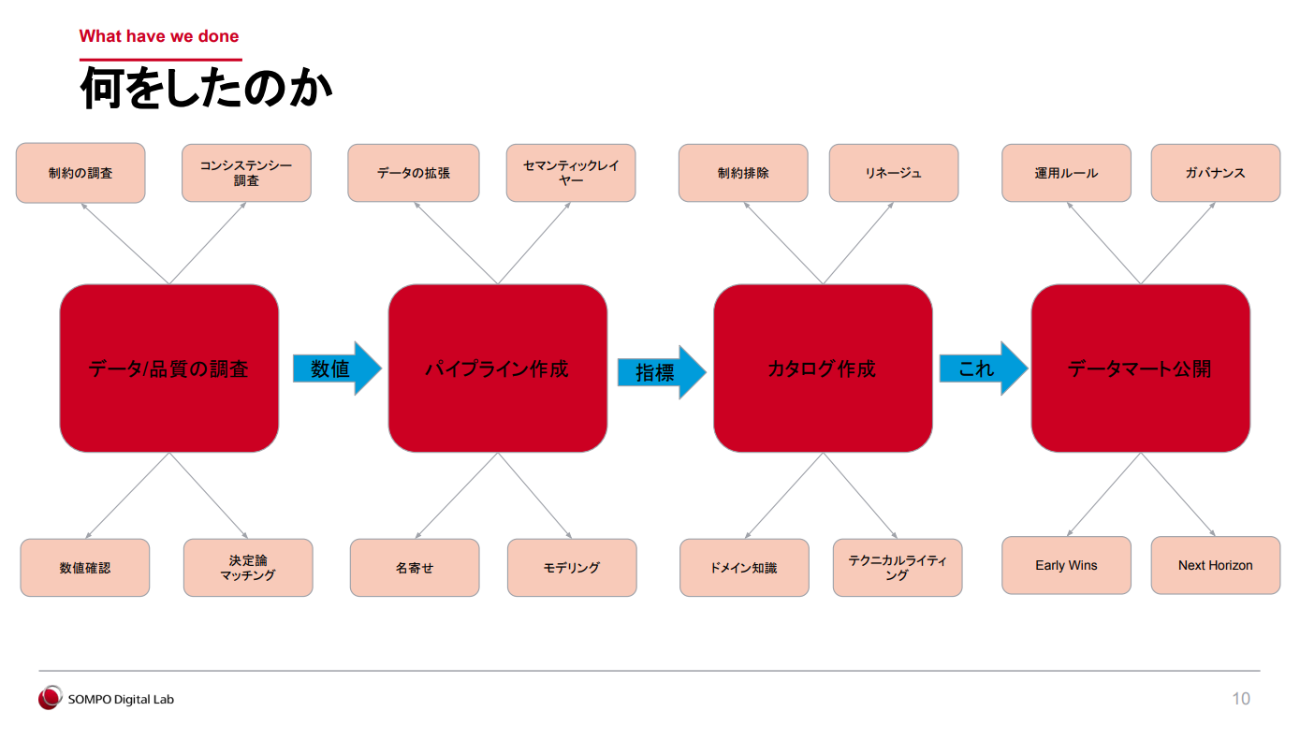
(1)データ/品質の調査
斎藤氏が「プロジェクトの成否を左右する最も大事なステップ」と語るのが、この「データ/品質の調査」だ。これは単なるデータの正誤チェックではなく、各部門で実際に使われているデータの意味や背景(≒ドメイン知識)を深く理解する作業とも言える。
このなかで、斎藤氏がまず取り組んだのが、「外部整合性のチェック」である。たとえばA部門とB部門がそれぞれ保有する火災のデータを突き合わせたところ、700万件中2万件で、親データが存在しない「オーファンレコード」が見つかったという。こうしたケースでは、アスタリスクのような記号の混入や入力ミスの可能性を疑い、各部門の担当者へのヒアリングなどを通じて、原因を解明していく。
ある程度データの整理が進んだら、実際のデータと想定される「期待値」を比較して、ズレがあればその要因を掘り下げていく。処理ロジックの誤りなのか、データの欠落や偏りなのか——地道な原因究明作業が続くのである。
さらには、メタデータの整備も並行して進めながら、決定論的マッチングによるデータの名寄せも行った。「データ分析基盤の『データプロファイリング機能』によってデータの分布や異常値を効率的に把握できたことが、作業効率を大きく高めた」と斎藤氏は振り返る。
こうした作業は、一度で完結するものではない。何度も試行錯誤を重ねながら、地道にデータの“素性”を明らかにしていったという。
(2)パイプライン作成
次のステップである「パイプラインの作成」では、複数のデータソースから取得したデータを、分析や共有が可能な形式に加工していく。ここで斎藤氏が強く意識したのは、「表記のばらつきや特殊なデータ構造といった元データ特有の制約をできるだけ排除して、カタログに記述する内容をできるだけシンプルにすること」だった。
これにより、利用者は元データのクセを意識することなく、直感的にデータにアクセスできるようになるし、カタログやパイプラインの保守性も高まるという。
また、データ基盤の設計では、柔軟性と再現性を重視している。具体的にいうと、同社が利用しているPalantir Foundryには「Ontology」というセマンティックレイヤーがあり、そこからAPI経由で集計を行うことが可能だ。そのため、データに複雑な計算ロジックを持たせず、後段のレイヤーに処理を委ねる方針を採用している。
本来であれば、セマンティックレイヤーを通じてデータを提供するのが望ましいが、今回のプロジェクトでは時間的な制約があったため、暫定的にスタースキーマを用いてデータを正規化し、Silver層で品質チェックをしたうえで、ワイドテーブル形式で提供する形とした。
ストーリーを大切にしたカタログは人にもAIにもやさしい
続いて、残りの2つのステップについても見ていこう。
(3)カタログ作成
ここでいうカタログとは、データの定義や構造、流れを説明する“データの取扱説明書”のようなものである。現場の利用者が迷わずデータを活用するためのガイドとなる。そのため、カタログは誰が見ても理解できるものでなければならない。
そこで斎藤氏はユーザーに公開するテーブル名やカラム名をすべて日本語で記述すると決定した。現場の利用者が普段から慣れ親しんでいる言葉に合わせることで、直感的に理解できるようにするためだ。英語表記にするケースもよくあるが、英語にすることで名前をつける際に表記揺れが生じたり、英語から日本語に解釈するタイミングで誤解が生じたりする危険がある。そうしたリスクを排除する狙いがあった。
もうひとつ工夫したのは、データのリネージュ(生成されてから利用されるまでの流れや依存関係)を追跡して整理するのではなく、実際に現場で使われている申し込み画面を見せてもらったり、紙のPDFからどのようにデータを入力しているのかを見せてもらったりしながら、“データの本質を理解する”ことだ。これらの活動により、複数のシステムを逐一遡って調査するコストが省けるだけでなく、カタログの内容は本質的なものだけが残ることになる。
また、カタログを書く際には、データを点ではなく線で捉え、流れがストーリーとして見えるように意識した。以下が良い例と悪い例である。
× 契約の識別のために付与する番号で、12桁の数値で構成する。
◯ 代理店保険の受付システムに登録後に被保険者向けの保険証券へ付与するユニークな番号。12桁の数値で構成する。
このようなストーリーを重視した書き方は、利用者の理解を高めるだけでなく、生成AIによる文脈理解にも有効であり、応用の幅が広がるのだという。
(4)データマート公開
最後のステップとなる「データマート公開」では、分析目的に応じて整理・整形したデータセットを利用者に提供する。その際、単に提供して終わりではなく、現場に即したガバナンスとガイドラインをしっかりと整備しておくことが重要だ。
たとえば個人情報を含むデータ分析のプロジェクトにおいては、すべての判断を個別のプロジェクトに委ねるのではなく、一定の共通ルールをあらかじめ用意しておく。つまり、ガバナンスという法律の範囲内において、プロジェクトごとに条例のような独自ルールを定めて活用できるようにしている。
加えて、これまで一度作ったらおしまいになりがちだったデータマートの運用にも、リリースサイクルの考え方を導入した。データは素早く変化し続けるものであるからこそ、定期的なリリースサイクルや、変更がある場合の移行期間、移行の方法を明示しておくことで、データエンジニアが「このデータマートの品質は、自分が責任をもって担保し続けるぞ」というオーナーシップを持つきっかけとしたのである。

こうした4つのステップに沿った「唯一の“源泉”」創りを、斎藤氏は「カタログ駆動開発」と呼んでいる。
「今回の取り組みによって、課題の解像度が劇的に向上した。これまで漠然と『なんかダメそうだ』と認識されていた事柄に対して、『ここがこうなっているからダメだ』と具体的な根拠とともに説明できるようになったのは、大きな進歩だった」と振り返る斎藤氏。「今後は、汎用的なデータマートの拡充に加え、確率論的マッチングの導入や、カタログをもとにドメイン知識をグラフとして可視化する取り組みも視野に入れている」と明かし、セッションを締めくくった。
なお、SOMPOホールディングスでは、データ分析基盤の構築からデータガバナンスの確立までを担うデータプロフェッショナルを募集している。興味のある方はぜひ採用サイトまで。

