



































データ分析をめぐる変化に対応できるツールを選ぼう
データ分析をめぐる状況は昨今急速に変化しています。一昔前(といってもそれほど昔のことではありませんが)と比べても、NoSQLに代表されるようなノンスキーマ型DBの一般化や、IoTに代表されるようなストリームデータのリアルタイム処理、機械学習アルゴリズムを用いた分析など、データ分析に求められる領域は拡大する一方です。
一方で、1つのツールに習熟するには膨大な時間と気力を要します。分析ツールを選定する際には、将来的な状況の変化に追随できるかも気にしておきましょう。せっかく勉強したツールが1年後には使い物にならなくなっていた、というのではまったくの徒労です。
本稿ではサンプルケースとして、温度センサーから得た大量のデータの分析を行いますが、分析ツールとして最近話題の「Apache Spark」を使います。Apache Sparkはコミュニティ、ベンダを問わず大勢の開発者が利用を模索しており、データ分析をめぐる変化への対応にも心配はないでしょう。
なお、本稿の最後にコラムとして、データ分析とはそもそも何かを正しく理解していただくためにコラムを載せています。本文で解説するApache Sparkによるデータ分析を体験した後、あるいはその前にお読みいただければ幸いです。
Apache Sparkとは
「Apache Spark」は、昨今のデータ分析の状況を踏まえて開発された最新のデータ分析ツールで、以下の特徴を持っています。
- Javaで動作し、1台のコンピュータでの動作から複数台での並列処理まで対応
- 複数のプログラミング言語(Scala、Python、Java、R)から利用可能
- 各種分析用ライブラリをビルトインで用意
- ストリームデータ処理に対応
Apache Sparkにはデータ分析者が必要とする機能が注意深く、過不足なく実装されています。1台のコンピュータでも動作するので、データ分析者がしばしば苦手とするコンピュータクラスタの構築を不要としてくれます。仮にデータ量が大きくなり1台のコンピュータに収まらなくなったとしても、クラスタ化を行うことで大規模な計算を行うことができます。
また、データ分析者が慣れ親しんできたPythonやRといったプログラミング言語から利用可能であることで、学習コストを大幅に下げています。将来的に、蓄積されたデータだけでなくストリームデータを扱う必要が生じた場合でも、同じツール(Spark)で対応することができます。
IBM BluemixのApache Spark
一般に、Apache Sparkは使い始める前の環境構築が大変だといわれます。そこで、トライアルでApache Sparkを使ってみる場合、自前で環境を構築するのではなく、クラウド上のサービス(PaaS)として提供されているApache Sparkを利用するとよいでしょう。
例えば、IBMが提供するPaaS「IBM Bluemix」(以下、Bluemix)でApache Sparkを利用できます。Bluemix上で利用するサービスにApache Sparkを追加することで、既存のアプリケーションに柔軟な分析機能を追加することができます。
また、Bluemix上のApache Sparkは、JSONデータベース「Cloudant」への接続機能や、コードのライブ実行が可能なエディタ「Jupyter Notebook」を用いたスクリプティング、OpenStackのオブジェクトストレージ「SWIFT」を使った分析用データセットの保管に対応しています。なにより、Bluemix上で開発したアプリケーションであれば、Apache Sparkとのデータの出し入れをシームレスに行うことができます。
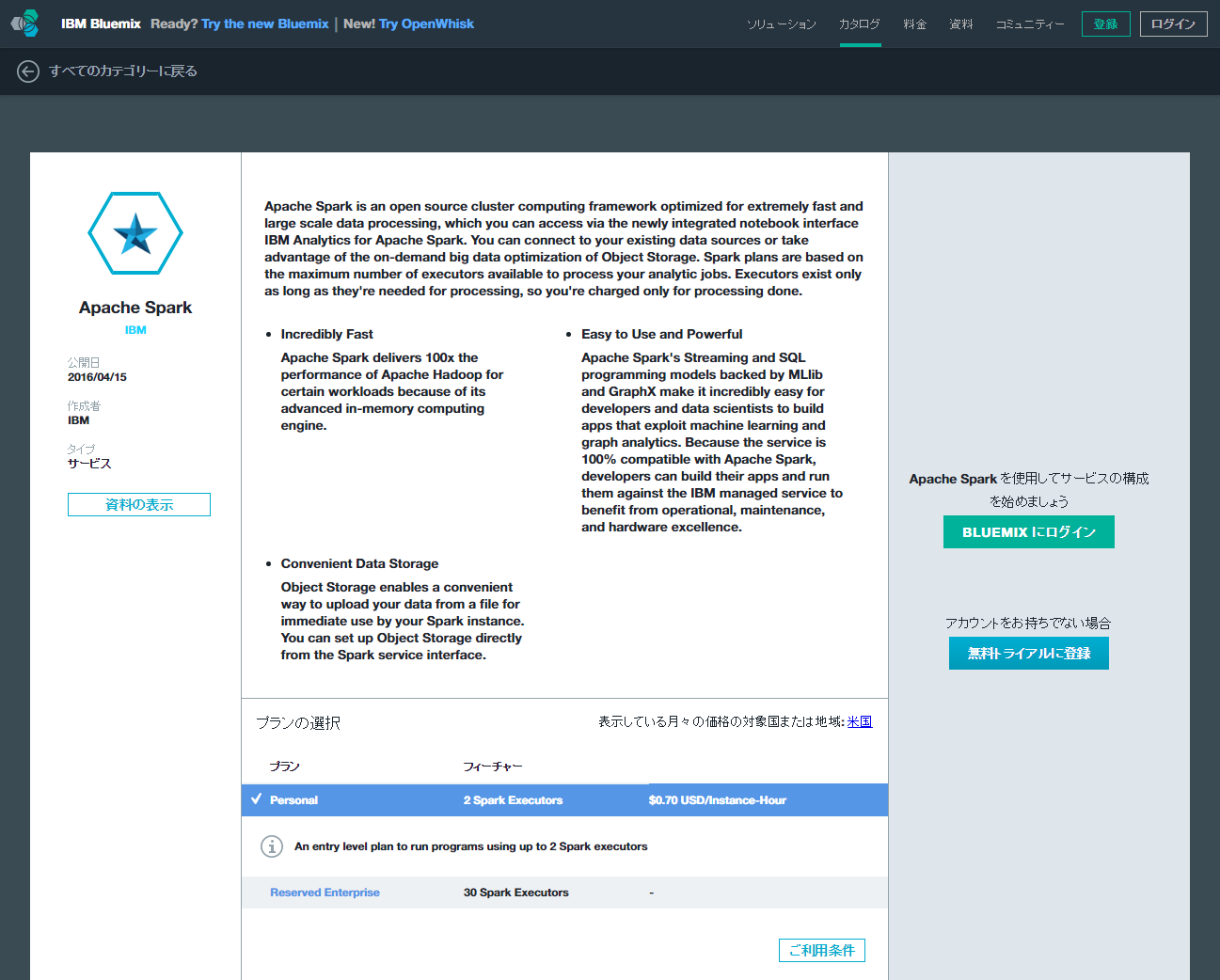
BluemixのApache Sparkのエディション
IBM BluemixのApache Sparkには、「Personalエディション」と「Reserved Enterprise Interactiveエディション」という2つのエディションがあります。
Personalエディションでは、Jupyter Notebookと2台のExecutor[1]が提供され、簡便なスクリプティングや、初歩的な並列処理を行うことが可能です。利用料金は1時間あたり74円(2016年3月現在)に設定されています。
Reserved Enterprise Interactiveエディションでは30台のExecutorが提供され、より大規模な並列処理が可能です。Reserved Enterprise Interactiveエディションは企業での利用が想定されているため、価格は都度見積りになっています。
注
[1]: Apache Sparkでデータの計算や読み書きなどを行うプロセスのこと。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)

