


































データ分析をめぐる変化に対応できるツールを選ぼう
データ分析をめぐる状況は昨今急速に変化しています。一昔前(といってもそれほど昔のことではありませんが)と比べても、NoSQLに代表されるようなノンスキーマ型DBの一般化や、IoTに代表されるようなストリームデータのリアルタイム処理、機械学習アルゴリズムを用いた分析など、データ分析に求められる領域は拡大する一方です。
一方で、1つのツールに習熟するには膨大な時間と気力を要します。分析ツールを選定する際には、将来的な状況の変化に追随できるかも気にしておきましょう。せっかく勉強したツールが1年後には使い物にならなくなっていた、というのではまったくの徒労です。
本稿ではサンプルケースとして、温度センサーから得た大量のデータの分析を行いますが、分析ツールとして最近話題の「Apache Spark」を使います。Apache Sparkはコミュニティ、ベンダを問わず大勢の開発者が利用を模索しており、データ分析をめぐる変化への対応にも心配はないでしょう。
なお、本稿の最後にコラムとして、データ分析とはそもそも何かを正しく理解していただくためにコラムを載せています。本文で解説するApache Sparkによるデータ分析を体験した後、あるいはその前にお読みいただければ幸いです。
Apache Sparkとは
「Apache Spark」は、昨今のデータ分析の状況を踏まえて開発された最新のデータ分析ツールで、以下の特徴を持っています。
- Javaで動作し、1台のコンピュータでの動作から複数台での並列処理まで対応
- 複数のプログラミング言語(Scala、Python、Java、R)から利用可能
- 各種分析用ライブラリをビルトインで用意
- ストリームデータ処理に対応
Apache Sparkにはデータ分析者が必要とする機能が注意深く、過不足なく実装されています。1台のコンピュータでも動作するので、データ分析者がしばしば苦手とするコンピュータクラスタの構築を不要としてくれます。仮にデータ量が大きくなり1台のコンピュータに収まらなくなったとしても、クラスタ化を行うことで大規模な計算を行うことができます。
また、データ分析者が慣れ親しんできたPythonやRといったプログラミング言語から利用可能であることで、学習コストを大幅に下げています。将来的に、蓄積されたデータだけでなくストリームデータを扱う必要が生じた場合でも、同じツール(Spark)で対応することができます。
IBM BluemixのApache Spark
一般に、Apache Sparkは使い始める前の環境構築が大変だといわれます。そこで、トライアルでApache Sparkを使ってみる場合、自前で環境を構築するのではなく、クラウド上のサービス(PaaS)として提供されているApache Sparkを利用するとよいでしょう。
例えば、IBMが提供するPaaS「IBM Bluemix」(以下、Bluemix)でApache Sparkを利用できます。Bluemix上で利用するサービスにApache Sparkを追加することで、既存のアプリケーションに柔軟な分析機能を追加することができます。
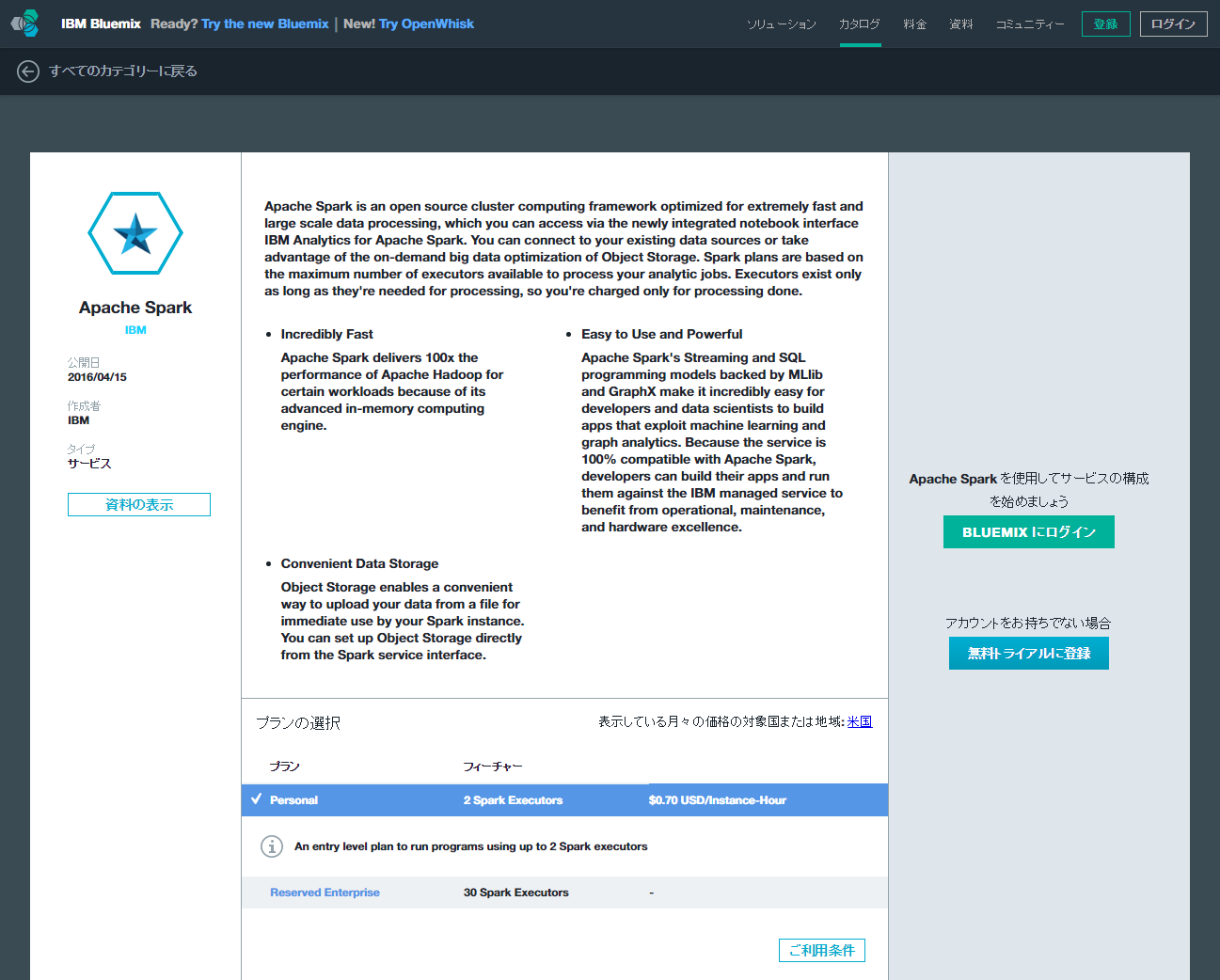
また、Bluemix上のApache Sparkは、JSONデータベース「Cloudant」への接続機能や、コードのライブ実行が可能なエディタ「Jupyter Notebook」を用いたスクリプティング、OpenStackのオブジェクトストレージ「SWIFT」を使った分析用データセットの保管に対応しています。なにより、Bluemix上で開発したアプリケーションであれば、Apache Sparkとのデータの出し入れをシームレスに行うことができます。
BluemixのApache Sparkのエディション
IBM BluemixのApache Sparkには、「Personalエディション」と「Reserved Enterprise Interactiveエディション」という2つのエディションがあります。
Personalエディションでは、Jupyter Notebookと2台のExecutor[1]が提供され、簡便なスクリプティングや、初歩的な並列処理を行うことが可能です。利用料金は1時間あたり74円(2016年3月現在)に設定されています。
Reserved Enterprise Interactiveエディションでは30台のExecutorが提供され、より大規模な並列処理が可能です。Reserved Enterprise Interactiveエディションは企業での利用が想定されているため、価格は都度見積りになっています。
注
[1]: Apache Sparkでデータの計算や読み書きなどを行うプロセスのこと。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
Apache Sparkで分析するサンプルデータの作成
ここからは、BluemixのApache Sparkを使ってデータ分析を行う方法を紹介します。分析の目標は「室内に設置した8つの温度センサーのうち、故障が疑われるのものを見つける」ことにしました。温度や湿度のセンサーデータを出力してくれるWebアプリケーション「IoTセンサーシミュレーター」を8つ動かして温度データを作成し、それをApache Sparkで分析して、8つのうち故障が疑われるものを特定します。
なお、ここで使用するIoTセンサーシミュレーターやCloudant、「Node-RED」といったツールの使い方、およびそれらを提供しているBluemixの利用開始方法は、本連載の第2回、第3回で詳しく説明しています。そのため、本稿では説明を最小限にとどめていますので、初めて触れる方はそれらの記事を参照してください。
IoTでデータを生成し保管するアプリの作成
Bluemixにログインし、ダッシュボードからアプリケーションを作成します。右上のメニューから[カタログ]を選択し、ボイラープレートから「Internet of Things Platform Starter」を選択します。
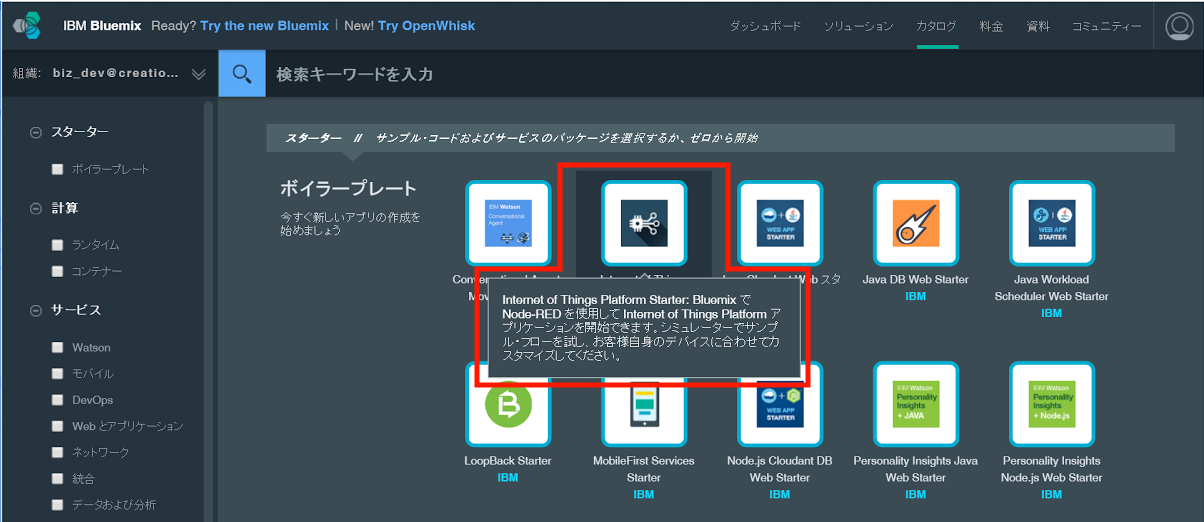
「Internet of Things Platform Starter」ボイラープレートが表示されたら、アプリの「名前」と「ホスト名」を入力して[作成]ボタンをクリックします。
![アプリの「名前」と「ホスト名」を入力して[作成]ボタンをクリック](http://cz-cdn.shoeisha.jp/static/images/article/9391/scr02a.png)
ステージング(アプリケーションの作成)には3~5分ほどかかります。ステージングが完了すると、「https://<ホスト名>.mybluemix.net」をWebブラウザで開くことで、Node-REDアプリケーションにログインできるようになります。
ログインしたら、画面右側にある「Go to your Node-RED flow editor」ボタンをクリックして、Node-REDの「フローエディタ」を開きます。デフォルトの状態では次のようなフローがセットされています。
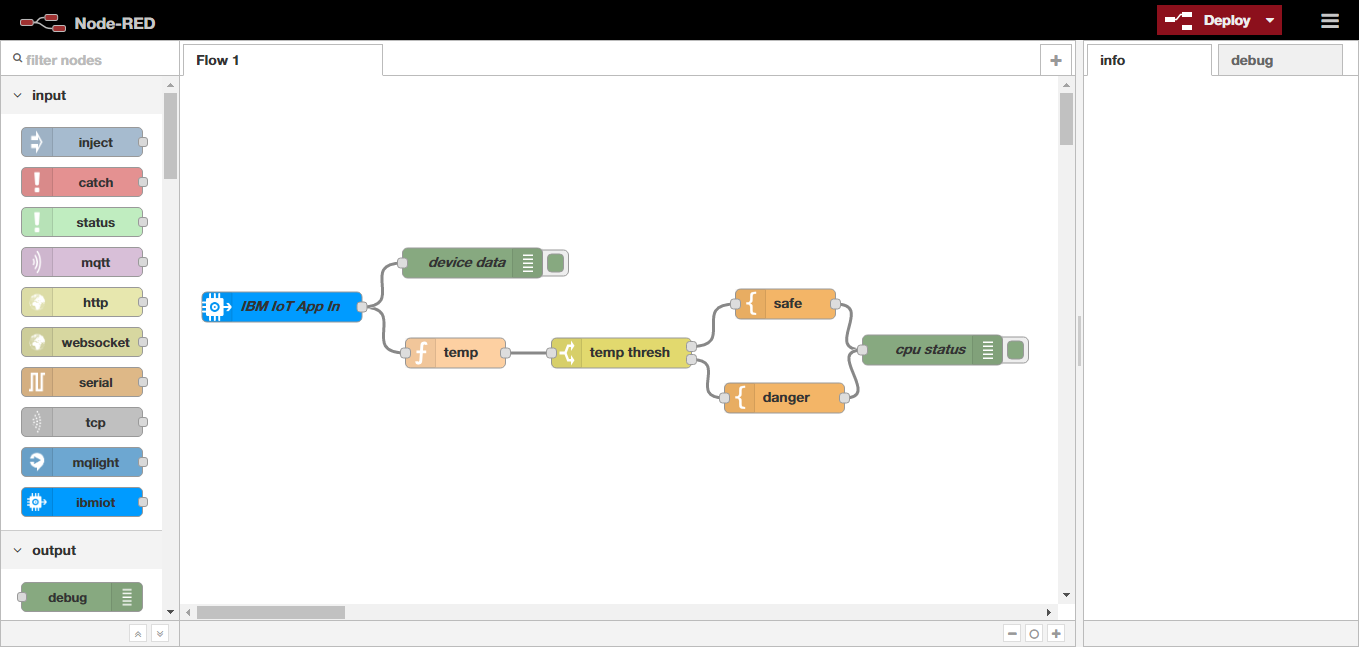
一番左側がセンサーの入力です。ダブルクリックすると詳細画面が開きます。初期状態では「Device Id」が空欄になっています。
「Device Id」欄には、IoTセンサーシミュレーターのMACアドレスを入力します。IoTセンサーシミュレーター(http://quickstart.internetofthings.ibmcloud.com/iotsensor)をWebブラウザで開くと、画面右上にIoTセンサーシミュレーターのMACアドレスが表示されています。
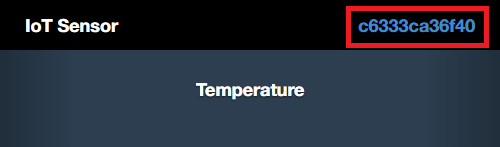
これをフローエディタの「センサーの入力」の詳細画面にある「Device Id」欄と「Name」欄に転記して[Deploy]ボタンを押します。すると、画面右の「Debug」ペインに次のようなメッセージが出力されるので、それを確認します。
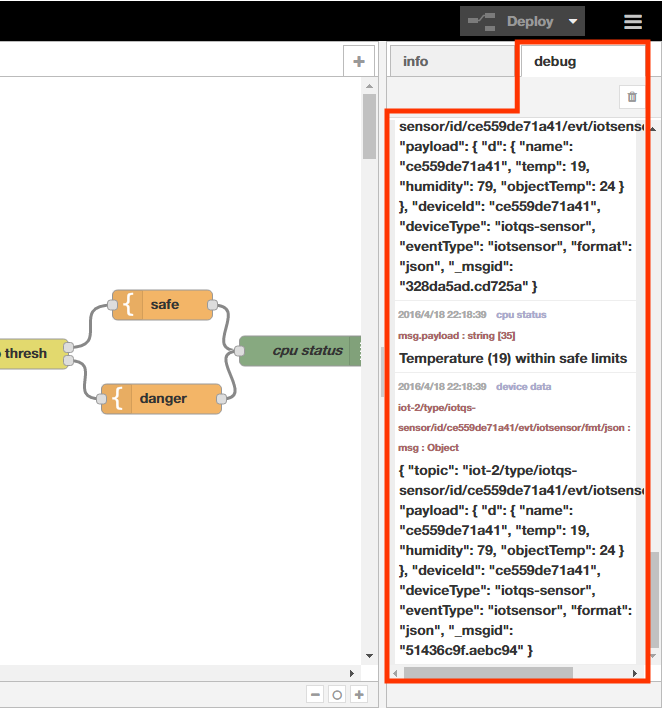
同様に、IoTセンサーシミュレーターをWebブラウザで7つ開き、左側のペインから「ibmiot」インプットノードを7つセットして、それぞれの詳細画面で7つIoTセンサーシミュレーターのMACアドレスを1つずつDevice Id欄へ入力します。
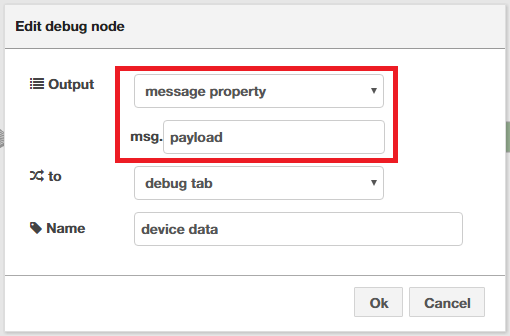
また、「device data」Debugノードを「temp」Functionノードへつなぎ替え(既存のノードを削除し新規に追加し)ておきましょう。詳細画面で「Output」欄を「message property」にし、すぐ下をmsg.payloadにします。これで8つのIoTセンサーシミュレーターからの出力が「Debug」ペインに表示されます。
続いて、IoTセンサーシミュレーターから出力されたデータに記録したタイムスタンプを追加するなど、少し加工を施します。「temp」Functionノードをダブルクリックして詳細画面を開き、「Function」欄を次のコードに書き換えます。
msg.payload = { "d":
{
"name": msg.payload.d.name,
"temp": msg.payload.d.temp,
"humidity": msg.payload.d.humidity,
"objectTemp": msg.payload.d.objectTemp,
"date": Math.floor((new Date()).getTime()/1000)
}
};
return msg;
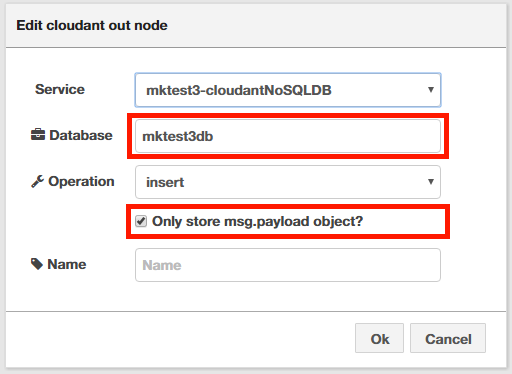
最後に、8つのIoTセンサーシミュレーターが出力したデータをCloudantデータベースへ格納させるノードを追加します。左側のノード一覧からStorageカテゴリーにある「Cloudant」ノードをフローの中にセットし、「temp」Functionノードへつなぎます。「Cloudant」ノードをダブルクリックして詳細設定を開いて、「Database」に任意のデータベース名を入力し、Operationの「Only store msg.payload object?」にチェックを入れます。
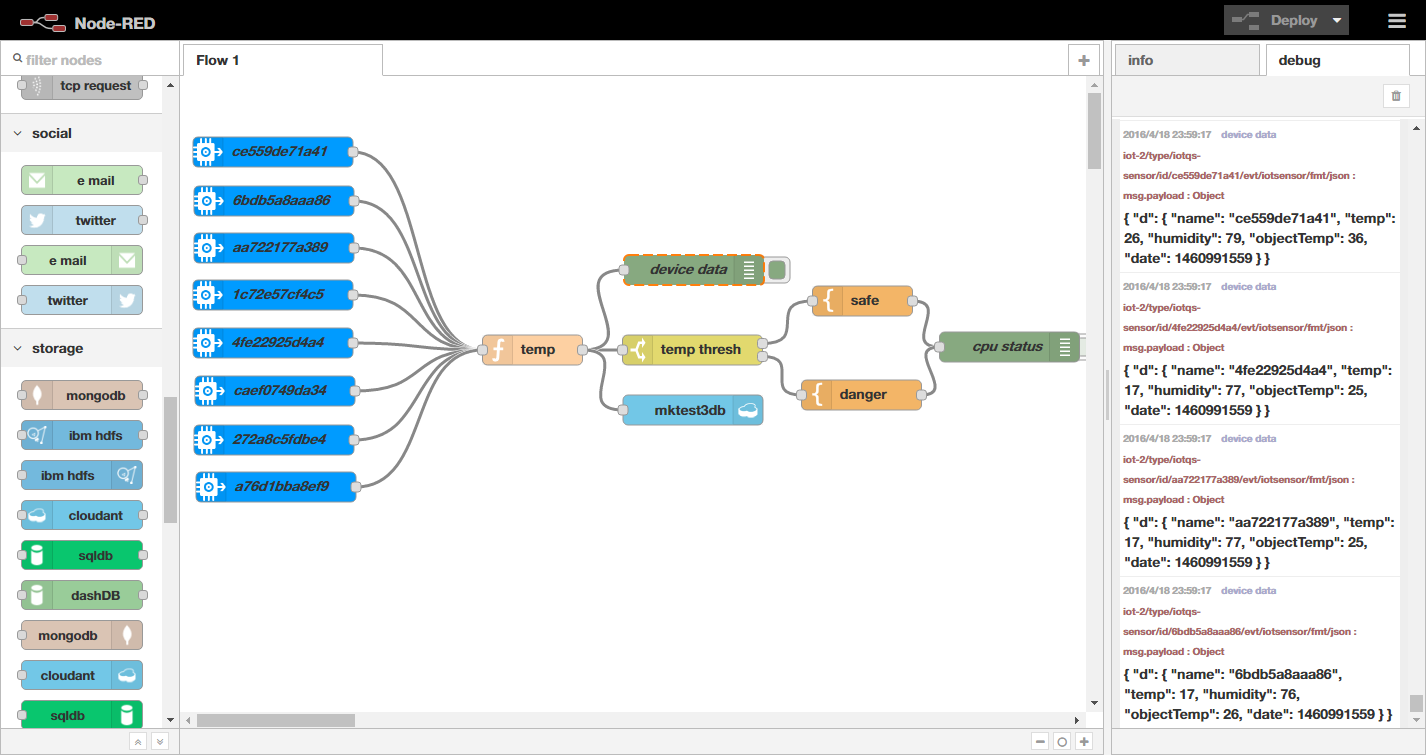
ここまでの作業で、次のようなフローが作成できました。センサー8個が定期的に生成するデータが、Cloudantデータベースに格納されていきます。
IoTセンサーシミュレーターに異常値を出力させる
IoTセンサーシミュレーターは、定常的に温度16℃~18℃、湿度75%~79%を示します。これは「湿度の高い室内」といえるでしょう。データ分析ではこのように、センサーが示す値からデータをめぐる状況を推測することが重要です。また、データの生成元はシミュレーターですので、全てのデータがほぼ同じ値を示します。当然ではあるのですが、あえてこのデータが示す状況を想像すると、8つのIoTセンサーは全て同一環境下のほぼ近しい場所にあると考えることができます。
もし、そのうちの1つのセンサーだけ異常な温度を示しているのであれば、それは環境の変化による要因であるとは考えにくく、例えば「センサーの故障」であると想定できます。したがって、「センサー群のうち他のセンサーと明らかに異なる値を示すセンサーは故障している」という仮説を立てることができます。
今回はApache Sparkを使って、分析の目標である「室内に設置した8つの温度センサーのうち、故障が疑われるのものを見つける」ため、IoTセンサーシミュレーターの1つを操作して定常値からはずれるデータを出力させ、意図的に故障しているセンサーを作り出すことにしました。
分析用データとして十分な量を用意するために、筆者はこのアプリケーションを10時間稼働させてCloudantデータベースにデータを蓄えました。集まったデータ量は約14万件(44MB)です。ただし、Device Idが「ce559de71a41」のIoTセンサーシミュレーターは、10時間のデータ蓄積時間のうち1時間だけ、設定を定常値から10℃高くした「Temparature: 26℃、Object Temparature: 36℃」にしてデータを出力させました、つまり、故障が疑われるセンサーはDevice Idが「ce559de71a41」のものになります。
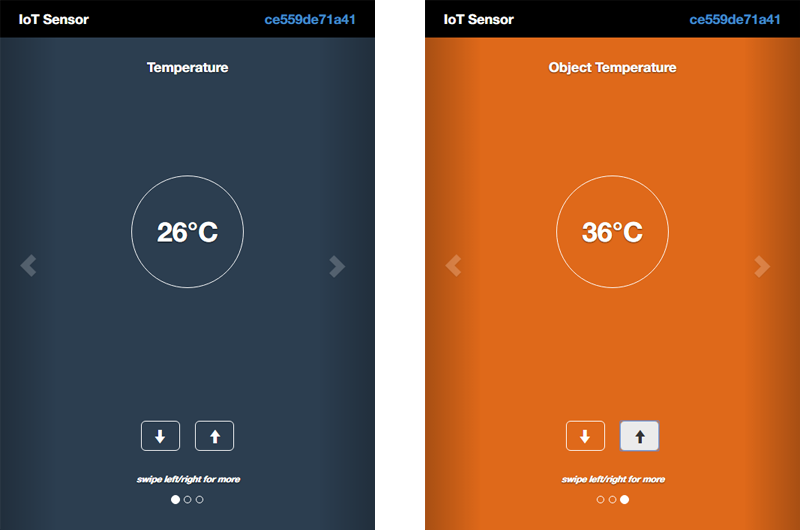
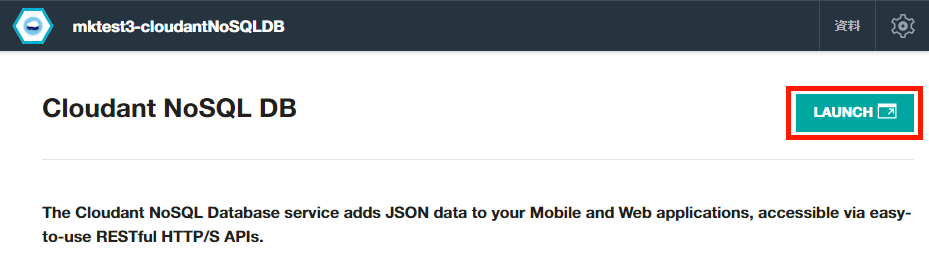
Cloudantデータベースに蓄積されたデータは、Cloudantの管理インターフェイスで見ることができます。Cloudantの管理インターフェイスは、Bluemixダッシュボードの左ペインにある「サービス」の「Cloudant NoSQL DB」をクリックし、開いたCloudant NoSQL DB画面の左上にある「Launch」ボタンをクリックすると現れます。
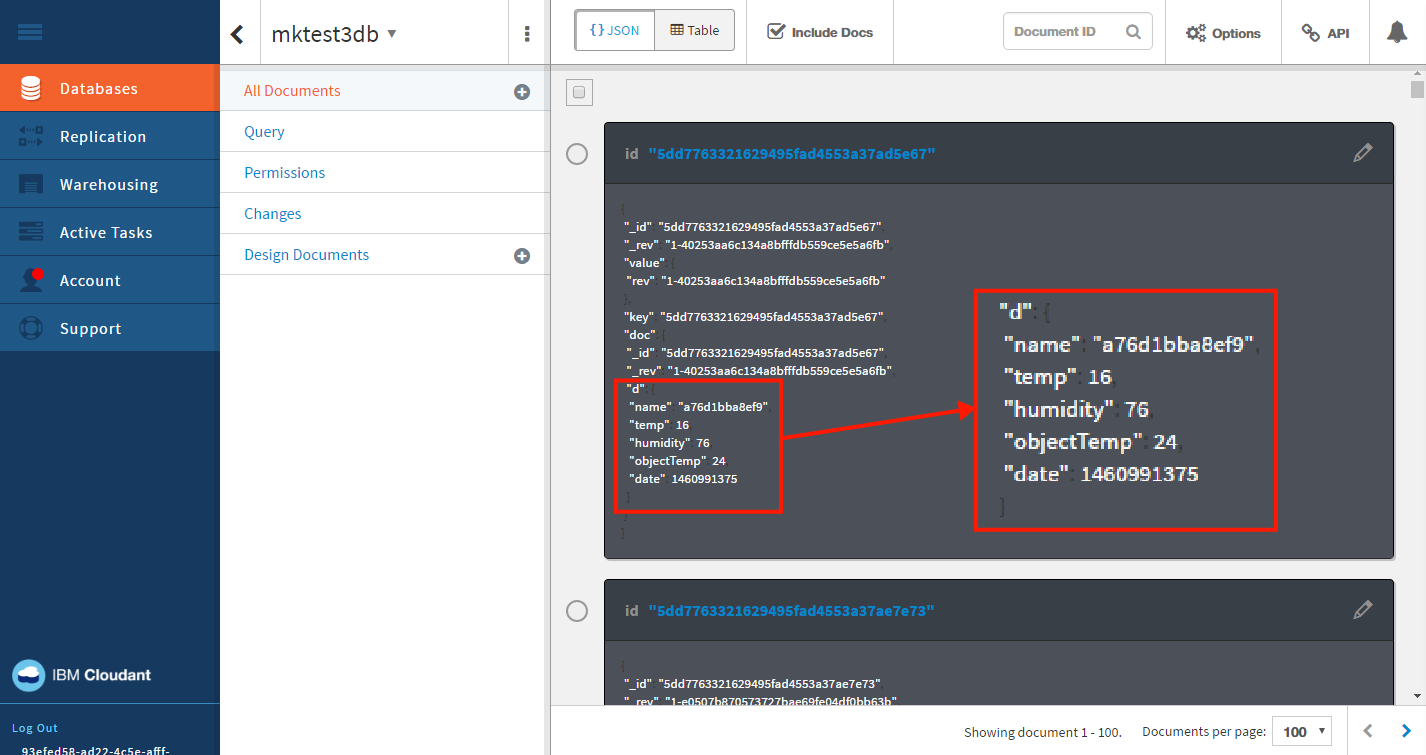
1つのIoTセンサーシミュレーターが出力したデータ1件につき、JSONレコードが1つ生成されています。実際の値は“d”以下のものになります(次図赤枠部分)。つまり、この値を見て正常か異常かを判断できれば、「センサー群のうち他のセンサーと明らかに異なる値を示すセンサーは故障している」という仮説を検証できることになります。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
Apache Sparkによるデータ分析
それではいよいよ、Bluemix上のApache Sparkを使ってデータ分析を行う手順とそのプログラムの説明に入ります。その前に、仮説の検証方法を確認しておきます。
仮説の検証方法
センサーデータの中から異常値を見つける場合、センサーデータの取りうる値がある一定の範囲内であれば、その範囲をはずれたかどうかを見れば判断がつくので、単純な範囲判定で異常値かどうか識別することができます。
しかし、様々な環境が想定される場合、異常値の検出は単純な計算ではできなくなってきます。例えば、ある1機種の室内センサーで世界中をサポートしようとする場合、当然国や季節によって「通常」と思われる温度、湿度は異なります。それではどうすればよいでしょうか。
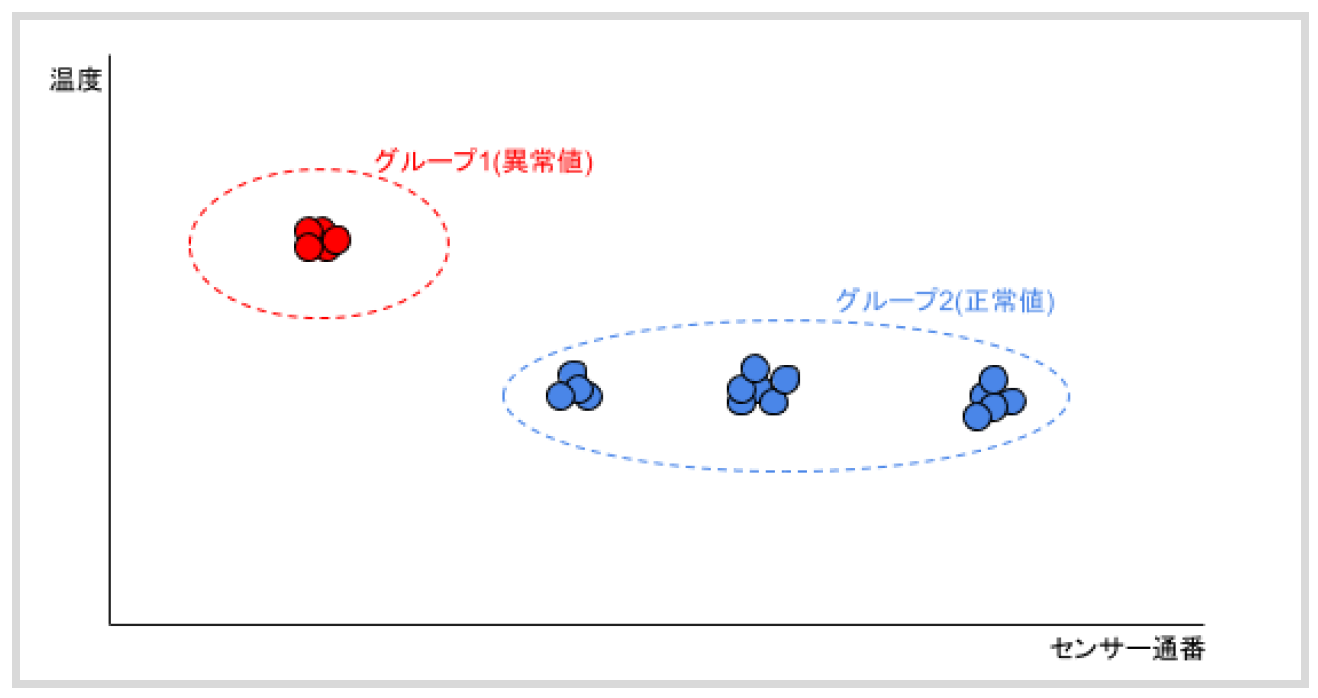
今回は、機械学習アルゴリズムの一つである「K平均法(K-Means法)」[2]を使って、IoTセンサーシミュレーターから取得したデータ14万個を、最も近い値同士4つのグループに分割します。K平均法は与えられた値の群をそれぞれ近似するグループに分割する統計アルゴリズムです。つまり、K平均法を使ってグループ化した後に、レコードの一部に通常の値と異なる一群がある場合、それは「故障が疑われる」センサーであるといえるはずです。
注
Apache Sparkの立ち上げ
それでは実際にApache Sparkのプログラムを作成していきます。まずはBluemixダッシュボードからApache Sparkをデプロイします。ダッシュボード右上にあるトップメニューから[カタログ]を選択し、カテゴリ「データおよび分析」の中から「Apache Spark」をクリックします。
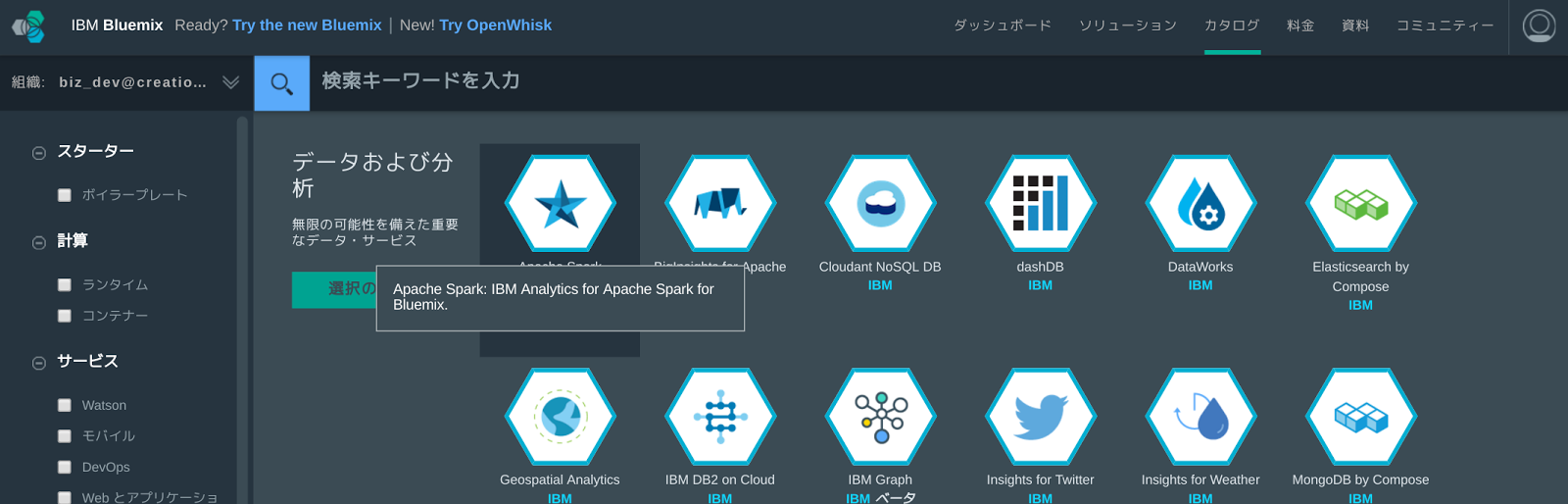
Apache Sparkデプロイ画面で、バインドするBluemix IoTアプリケーションを選択し、[作成]ボタンを押すとデプロイが開始されます。
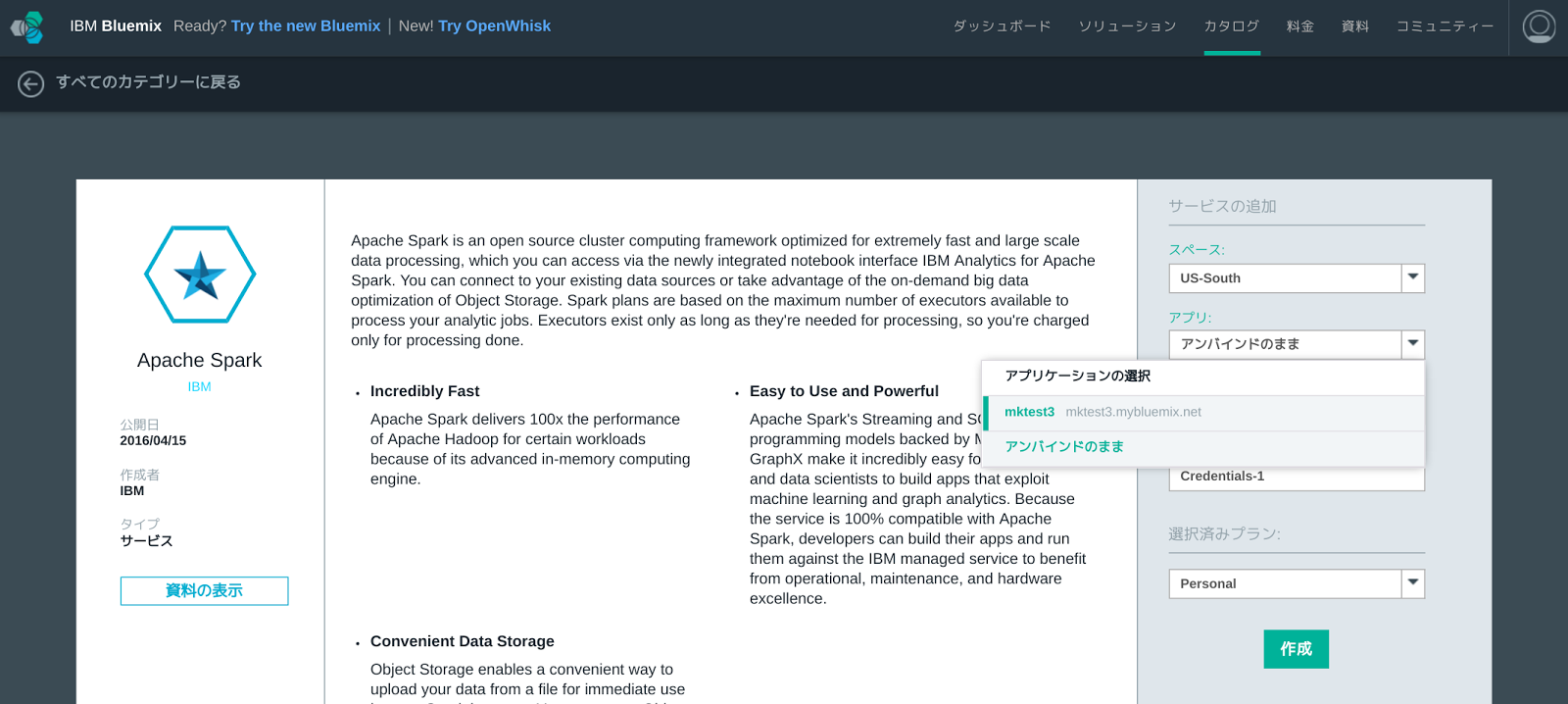
ただし、Bluemixの制約で、Bluemix IoTアプリケーションを再ステージする必要があり、その旨のダイアログボックスが表示されます。[再ステージ]ボタンを押して、デプロイを続行します。デプロイには3〜5分程度時間がかかります。
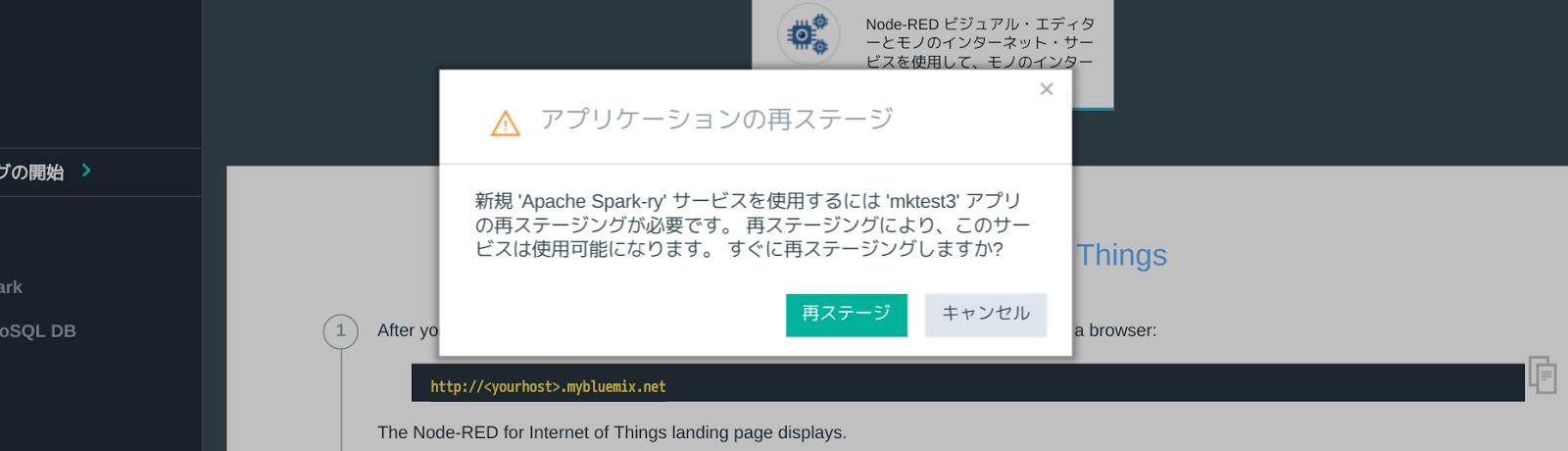
次のような画面が表示されたら、アプリケーションの再ステージとApache Sparkのデプロイが完了しています。
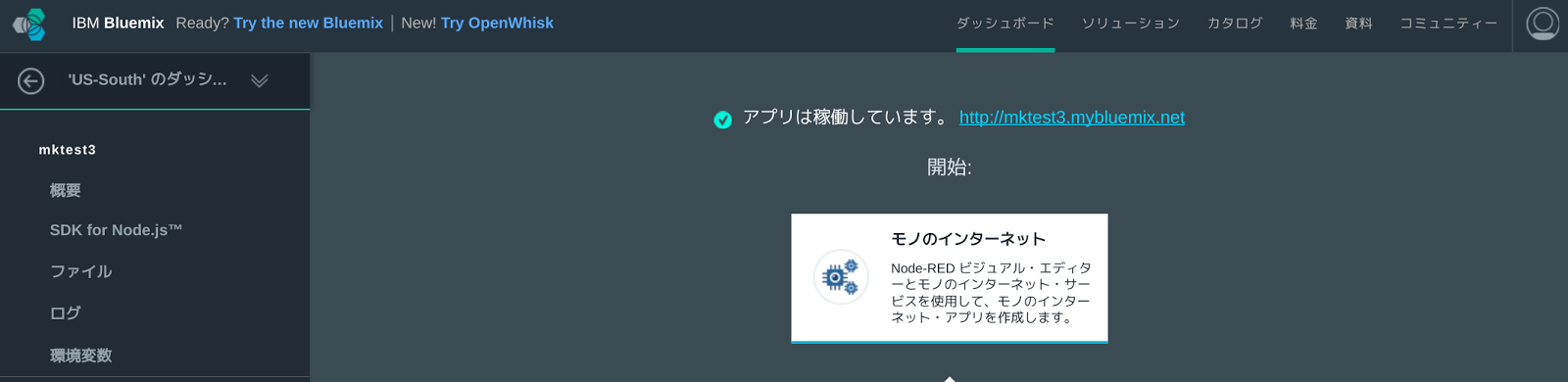
ダッシュボードに戻り、作成したApache Sparkアプリケーションを選択します。
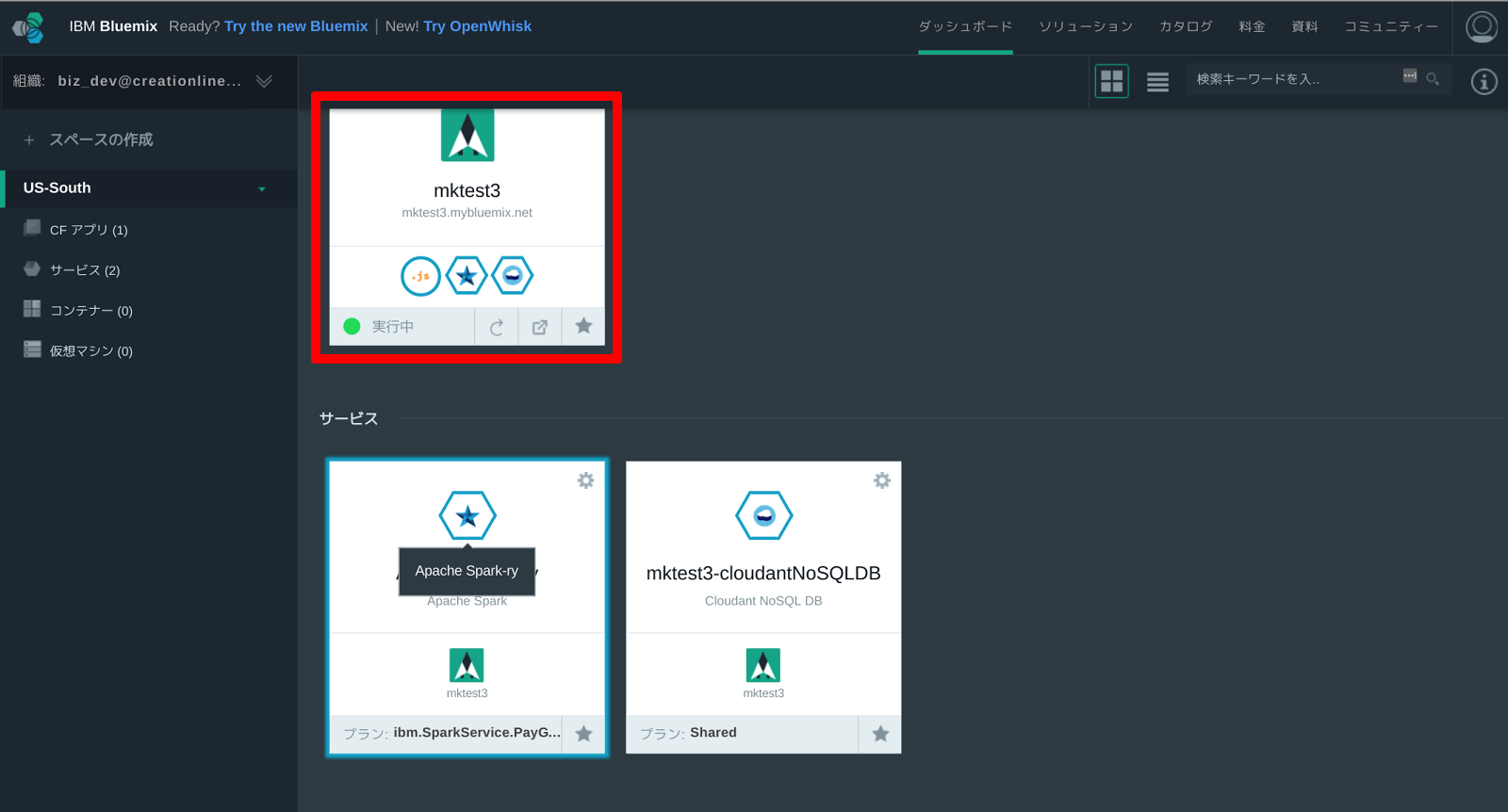
分析プログラムを作成し実行する方法
次に示す画面が、Bluemix上のApache Sparkの初期画面です。今回の分析プログラムは、BluemixのApache Sparkがデフォルトで提供している「Jupyter Notebook」で作成します。Jupyter Notebookは対話的にPythonコードを実行できる(書き込んだコードを随時実行し、結果を出力してくれる)ツールです。
まず、初期画面で[NOTEBOOKS]ボタンをクリックし、Notebookの管理画面に遷移します。
![[NOTEBOOKS]ボタンをクリックしてNotebookの管理画面へ遷移](http://cz-cdn.shoeisha.jp/static/images/article/9391/scr20.png)
管理画面に移ったら、[NEW NOTEBOOK]ボタンをクリックして新規作成画面に移ります。
![[NEW NOTEBOOK]ボタンをクリックして新規作成画面に移る](http://cz-cdn.shoeisha.jp/static/images/article/9391/scr21.png)
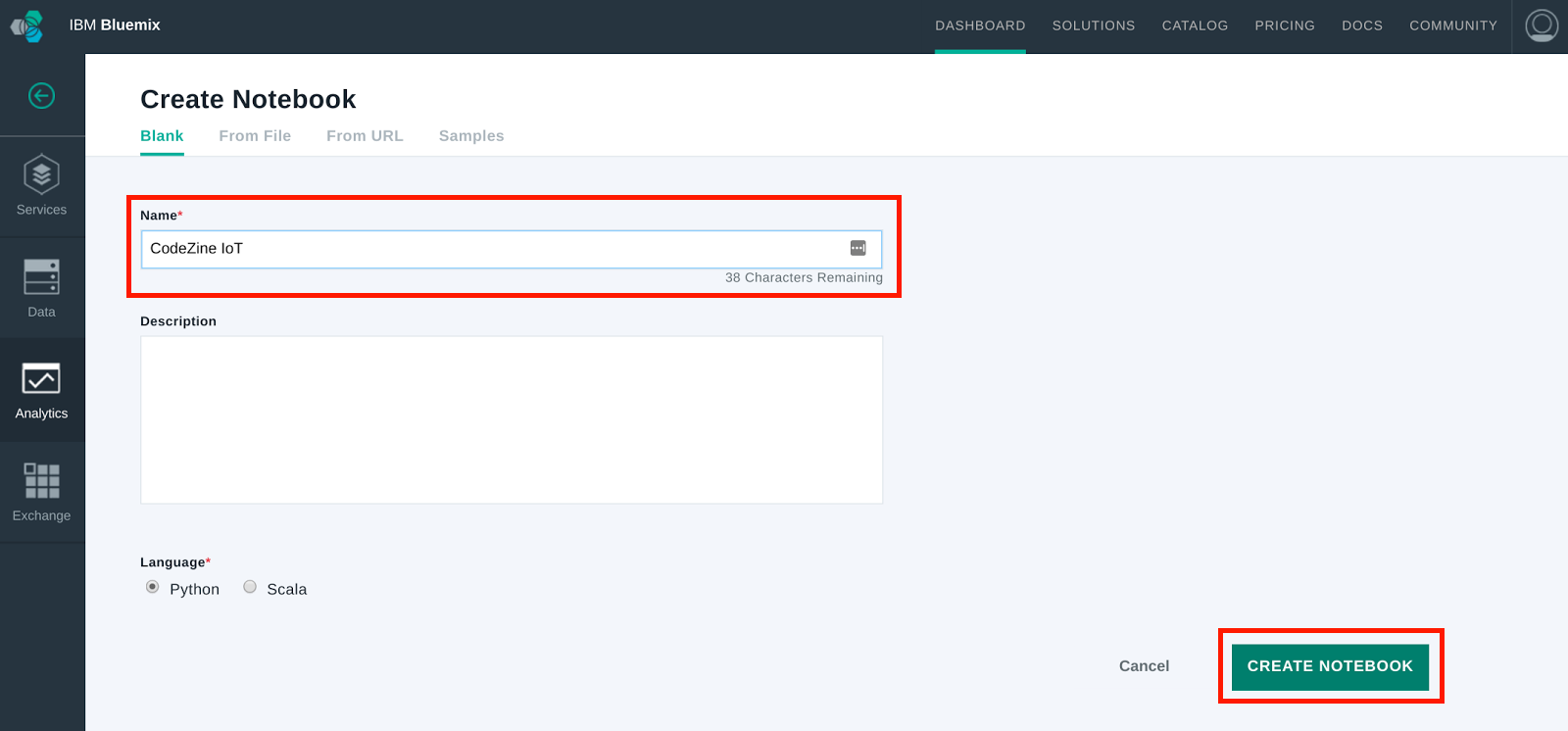
新規作成画面ではノートのタイトルを「Name」欄に入力します。今回は「Codezine IoT」としました。タイトルを入力したら、[CREATE NOTEBOOK]ボタンをクリックして、ノートを作成します。
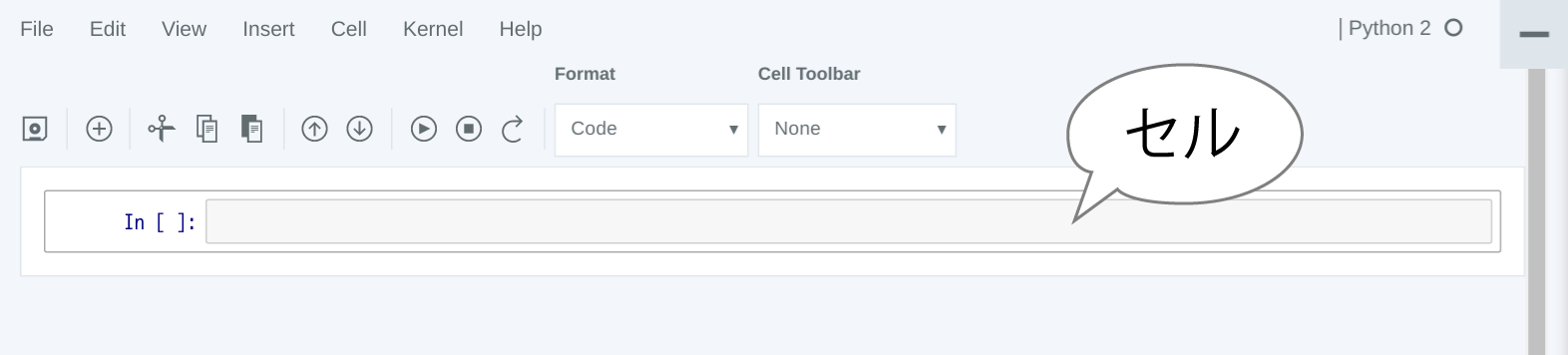
作成直後のノートは、次の画面のようになっています。「In []:」と表示されている右にある欄を「セル」といいます。Jupyter NotebookではこのセルにPythonコードを入力していきます。コードはセルごとに実行できます。
セルのコードを実行するには、対象のセルにフォーカスがある状態で、次のいずれかの操作を行います。
- メニューバーで[Cell]→[Run]を選択する
-
ツールバーの
 ボタンをクリックする
ボタンをクリックする
- [Shift]+[Enter]キーを押す
 ボタンをクリックする
ボタンをクリックする
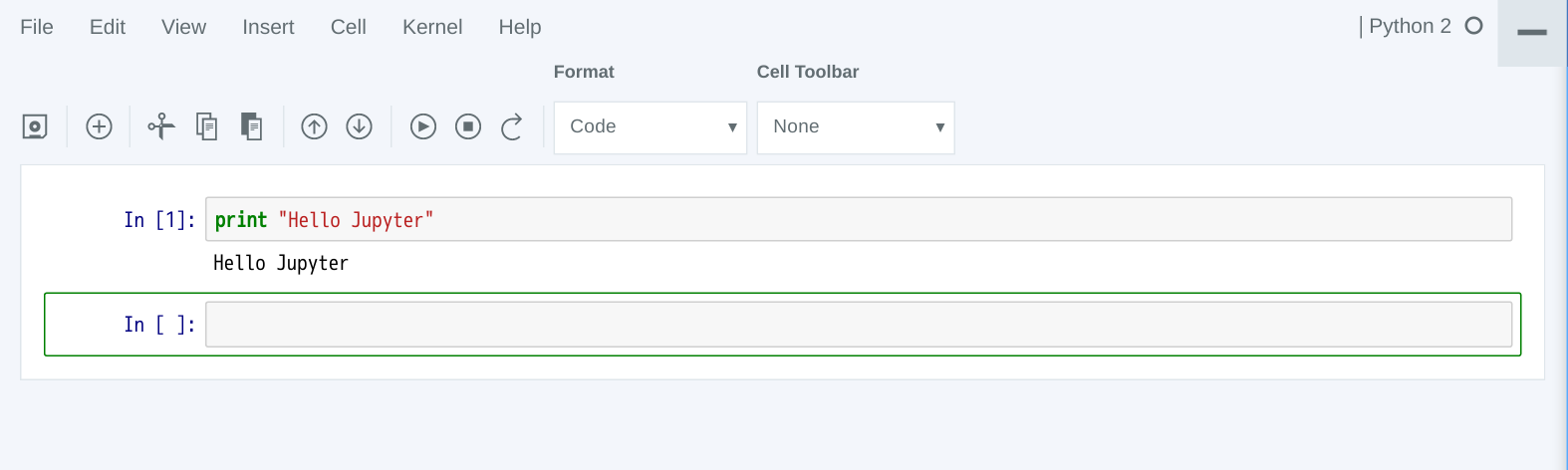
例えば、セルに「print “Hello Jupyter”」と入力して実行すると、次のように表示されます。
また、セルにフォーカスがある状態で、上部の「Format」から「Markdown」を選択することで、コメントをMarkdown形式で記述できます。例えば、セルに「## これは実行されない」と入力し、実行すると次のように表示されます。Formatを「Code」にしたまま、セルに「#」からコードを入力すると、Pythonコードのコメントとして認識されます。
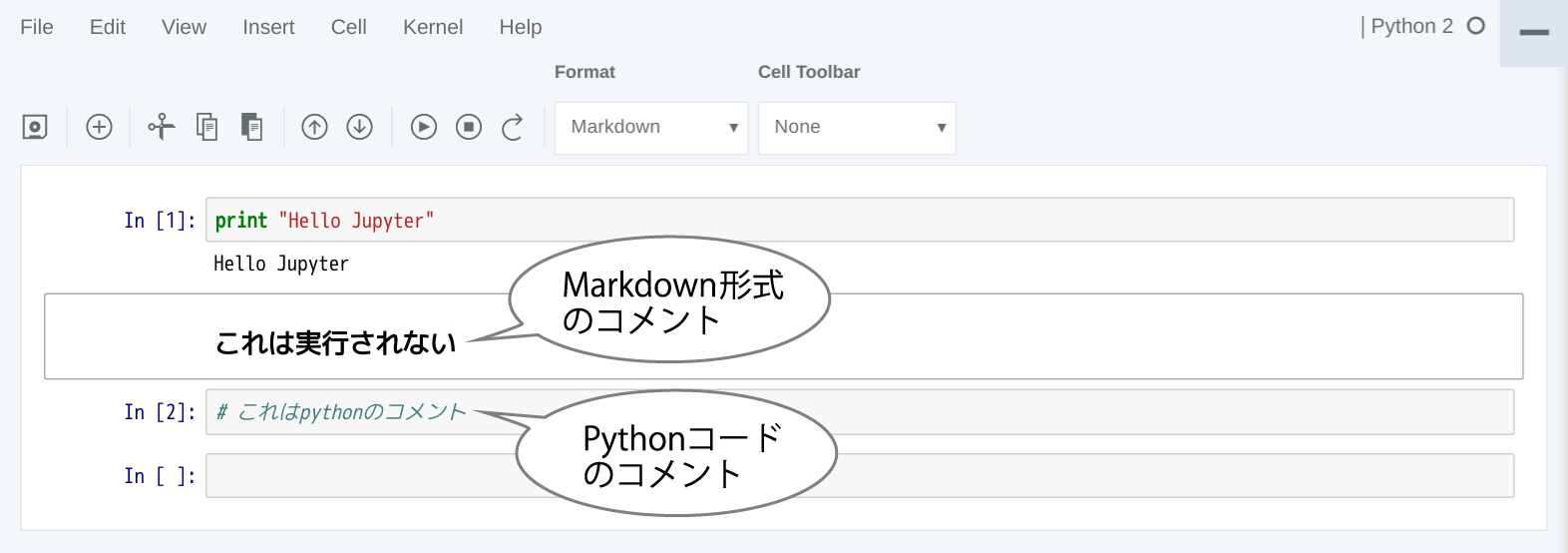
Jupyter Notebookの詳細については多くの方が情報を発信していますので、インターネットを検索して勉強してみましょう。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
分析プログラムを入力し実行する
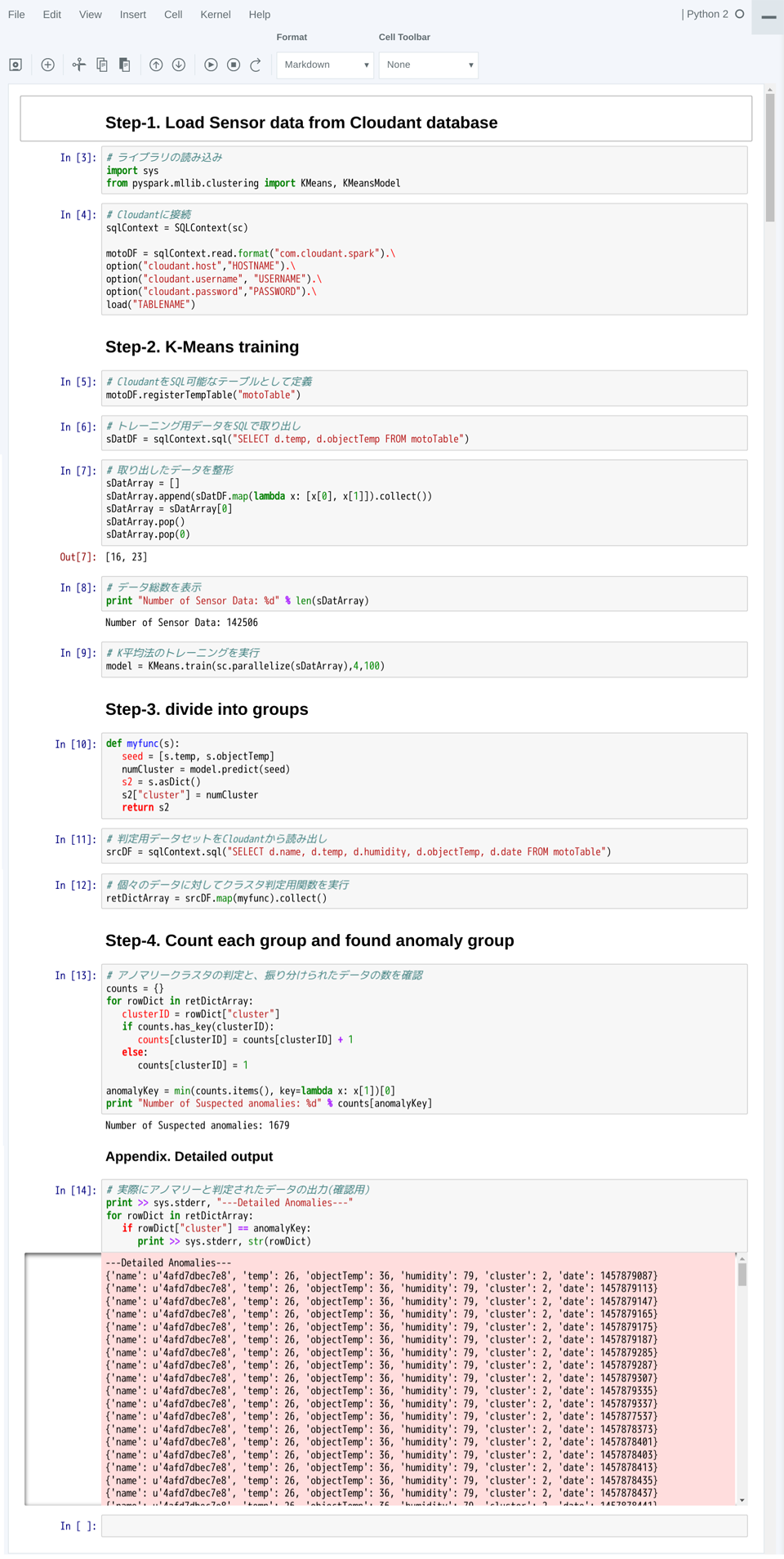
Jupyter Notebookの操作に慣れたところで、今回の分析プログラムをJupyter Notebook上に記述していきましょう。下表に記したプログラムを1セルずつ入力し、都度実行してください。表のFormat列は、セルのFormatを「Code」にして入力するか「Markdown」にして入力するかを表しています。
| Format | セルへの入力 |
|---|---|
| Markdown |
## Step1. Load Sensor data from Cloudant database |
| Code |
# Spark機械学習ライブラリの読み込み import sys from pyspark.mllib.clustering import KMeans, KMeansModel |
| Code |
# Cloudantに接続
sqlContext = SQLContext(sc)
motoDF = sqlContext.read.format("com.cloudant.spark").\
option("cloudant.host","HOSTNAME").\
option("cloudant.username", "USERNAME").\
option("cloudant.password","PASSWORD").\
load("TABLENAME")
|
| Markdown |
## Step2. KMeans training |
| Code |
# CloudantをSQL可能なテーブルとして定義
motoDF.registerTempTable("motoTable")
|
| Code |
# トレーニング用データをSQLで取り出し
sDatDF = sqlContext.sql("SELECT d.temp, d.objectTemp FROM motoTable")
|
| Code |
# 取り出したデータを整形 sDatArray = [] sDatArray.append(sDatDF.map(lambda x: [x[0], x[1]]).collect()) sDatArray = sDatArray[0] sDatArray.pop() sDatArray.pop(0) |
| Code |
# データ総数を表示 print "Number of Sensor Data: %d" % len(sDatArray) |
| Code |
# K平均法のトレーニングを実行 model = KMeans.train(sc.parallelize(sDatArray),4,100) |
| Markdown |
## Step3. divide into groups |
| Code |
# クラスタ判定用関数を定義 def myfunc(s): seed = [s.temp, s.objectTemp] numCluster = model.predict(seed) s2 = s.asDict() s2["cluster"] = numCluster return s2 |
| Code |
# 判定用データセットをCloudantから読み出し
srcDF = sqlContext.sql("SELECT d.name, d.temp, d.humidity, d.objectTemp, d.date FROM motoTable")
|
| Code |
# 個々のデータに対してクラスタ判定用関数を実行 retDictArray = srcDF.map(myfunc).collect() |
| Markdown |
## Step4. Count each group and found anomaly group |
| Code |
# アノマリークラスタの判定と、振り分けられたデータの数を確認
counts = {}
for rowDict in retDictArray:
clusterID = rowDict["cluster"]
if counts.has_key(clusterID):
counts[clusterID] = counts[clusterID] + 1
else:
counts[clusterID] = 1
anomalyKey = min(counts.items(), key=lambda x: x[1])[0]
print "Number of Suspected anomalies: %d" % counts[anomalyKey]
|
| Markdown |
### Appendix. Detailed output |
| Code |
# 実際にアノマリーと判定されたデータの出力(確認用) print >> sys.stderr, "Detailed Anomalies" for rowDict in retDictArray: if rowDict["cluster"] == anomalyKey: print >> sys.stderr, str(rowDict) |
セルを1つずつ実行していく様子は、次のようになります。
最後の分析結果だけをクローズアップして見てみましょう。
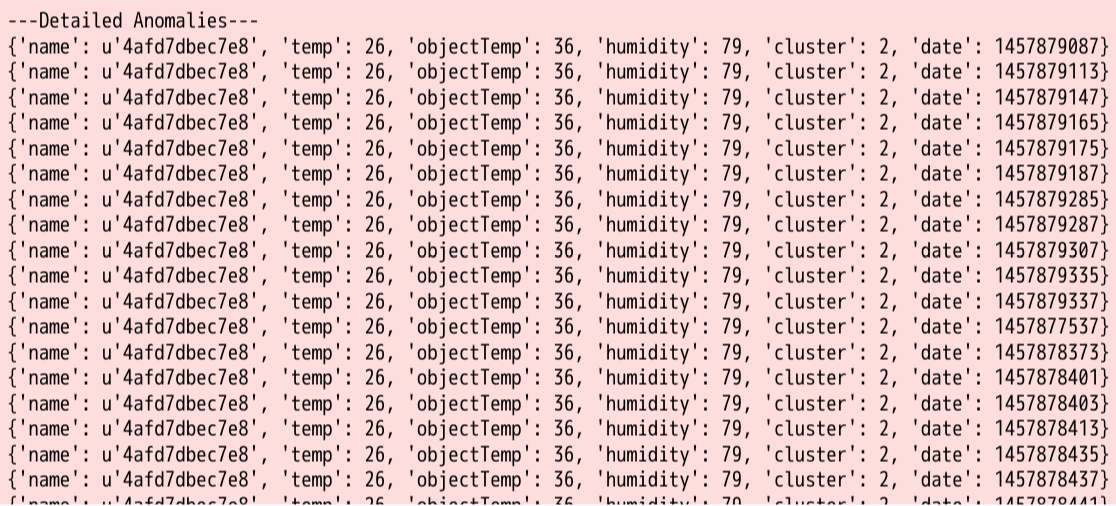
うまく「temp=26」を異なるグループに選り分けることができました。つまり約14万件のデータのうち1679個のデータを異常値であると考えることができます。
おわりに
IBM Bluemixで使用できるApache Sparkを活用した簡単なデータ分析例を紹介しました。Apache Sparkには今回使用したK平均法の他にも、様々な統計分析アルゴリズムが搭載されています。ただし、使用にあたっては今回述べたとおり、分析元のデータが何を示しているのか、何を見つければ正解であるのかを吟味して使用するようにしましょう。
また、IBM DeveloperWorks日本語版にはBluemixおよびApache Sparkに関する様々な活用例が紹介されていますので、ぜひ活用してください。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)
コラム:データ分析を正しく理解しよう
今回はBluemixで提供されているApache Sparkを利用して、例外的なデータ群を抽出しました。Apache Sparkは「機械学習」をキーワードに、昨年から急速に話題を集めていますが、基本はあくまで並列処理のためのツールです。ここではツールに振り回されることのないよう、そもそもデータ分析とはどういうものかを、簡単ですが説明しておきたいと思います。
センサーデータはビッグデータ
IoTでは膨大な量のセンサーデータが生み出されます。収集されたデータはまさに「ビッグデータ」と呼べるでしょう。ビッグデータを分析できることは、クラウドを活用した分散コンピューティングの真骨頂ともいえ、技術者にとっては取り組み甲斐のある課題の一つでしょう。
しかし、ここに大きな落とし穴があります。大量のデータを前にして、行き当たりばったりの分析や考察を行っても、いたずらに時間を浪費することになりますし、適切なツールを使わなければ、そもそもデータ群の傾向を見ることすらできません。
ただし、ほとんどのデータに価値はない
まず前提として、「センサーの出力するデータはただのデータ」であって、それ自体に何か意味があるわけではありません。データに意味を持たせるのはあくまで人間の役割です。返して言えば、いくら大量のデータがあったとしても、意図する結果を想定していなければ、データから何かを見出すことはとても困難です。
「弊社で蓄積したデータを解析して新たな知見を見出してほしい」とデータ分析を依頼してきた人に、どんな知見を見つけたいかとたずねても「とにかく“何か”を探してくれ」としか答えない、なんて笑い話もあります。分析の目的や目標がなければ、考慮すべき範囲があまりに大きくなりすぎ、対応に苦慮することが少なくありません。
実際のところ、現在ビッグデータと呼ばれているもののほとんどは、実質的には意味のない、不必要なデータであるといわれています。その中に含まれる価値や重要なデータを抽出するためには、残りのほとんどのデータを捨てることが必要になってきます。では、データを捨てるか、捨てないかはどのように決めればよいのでしょうか。
「データの意図」と「ツール」を考えよう
分析の方針や、分析の結果説明は、基本的に分析者自身が行う必要があります。ただし、あまりに突拍子もない分析を行ったり、現実からあまりに離れすぎて他の人が想像することが難しい分析結果を導いたりしても、共感を得ることは難しいでしょう。価値のある分析結果を導くには、データから見出せる事実から、データの周辺の環境や状況、依頼された背景などさまざまな要素を積み上げて1つのストーリーを作り上げる力が必要です。昨今、機械学習がブームになっていますが、無思慮にデータを機械学習アルゴリズムに通しただけでは分析を行ったとはいえませんし、分析結果を受け取る側は注意してその内容を理解する必要があります。
データ分析の進め方
それでは、分析はどのように進めていけばよいでしょうか。どのようなデータを扱うかによって変化するものもありますが、大きくは以下の3つになります。
- データをめぐる状況の理解
- データとデータを扱うツールの理解
- 仮説の構築と検証
データをめぐる状況の理解
データはそのままでは意味をなさなくとも、データが取得された意図や状況を考慮することで、その意味を肉付けすることができます。センサーデータであれば、そのセンサーがどのような場所にどの程度の密度で設置されているのか、どの程度の頻度でデータを取得しているか、精度はどの程度か、といったことを調べましょう。分析を依頼してきた担当者にヒアリングすることで、これらの情報やヒントを得られるかもしれません。
次に示すのは、温度センサーデータを得た3つの状況です。それぞれの温度(センサーデータ)が表す意味は全く異なります。
- センサーはエンジン内の燃焼室のなかにあり、4ミリ秒ごとに温度を計測している。おおよそ40ミリ秒ごとに温度は上昇したり、下降したりする
- センサーはデータセンターのラックの背面にあり、1分ごとに温度を計測している。24時間ほぼ定常的に一定の温度が計測される。ただし、機器の入れ替えや作業などによって変動が発生する場合がある
- センサーは配送センターの冷蔵保管庫の中に設置されており、5分ごとに温度を計測している。24時間ほぼ定常的に一定の温度が計測されるが、保管庫内の人の立入や、保管物の入れ替えなどによって変動が発生する場合がある
こうした取得したデータの周辺状況を理解することも、分析の作業の一つです。データの変動だけを見ていても、それが人為的なものなのか、何かしらの異常を示すものなのかを判断することができません。
また、周辺状況を調べることで、期待される分析目的が見えてきます。目的が見えてくれば、分析の成果についての目標達成基準を定めたり、分析作業のスケジュールを組み立てたりすることができるでしょう。データの分析と実際の成果が具体的に結び付くイメージを描けなければ、分析プロジェクトは進みません。
データとデータを扱うツールの理解
IoTと一口でいっても、実際には様々なデータ形式が存在します。古くはCSV形式が一般的でしたが、現在ではJSONやデータベースのダンプファイルなどが元データになるかもしれません。データベースのような構造化データ、JSONのような半構造化データの場合にはテーブルの数、データ型などを把握する必要があるでしょう。
データの種類によってツールを検討することも重要です。データの量も考慮すべきポイントです。Excelはとても便利なツールですが、現在ではExcelで扱うことができないデータ量になることが少なくありませんし[3]、1台のコンピュータのメモリ量に収まらないことすらしばしばあります。
世の中にはデータ分析機能をうたうツールが各種ありますが、最初のうちは大仰なツールを使わないことをお勧めします。カタログの上では非常に魅力的な機能を多数持っているツールでも、データをロードするために大量のドキュメントを読む必要があったり、ある状況には対応しないことが後で判明したりすることが往々にしてあります。重要なのはツールを使うことではなく、ツールを使いこなしてデータを分析することであることは意識しておきましょう。
仮説の構築と検証
分析目的、状況、ツールに見通しがついたら、目的を達成するための仮説を構築します。例えば、分析目的が「センサーの不良を発見する」というものであれば、「100個のセンサーのうち、数個が正しくない値を出力しているかもしれない」などが仮説になります。
仮説を作ったら検証を行います。ここが実際の分析作業になります。検証の結果、仮説が正しいこともありますし、仮説どおりの結果が出ないこともあります。検証の内容を注意深く調査し、検証方法が間違っているのか、仮説が間違っているのか、もしくは仮説を構築する前提が間違っているのかを探っていきます。
注意したいのは、データ分析(検証)の結果が完全に理論どおりの値を示すとは限らない点です。データが示す現実は、多様な外乱要因を反映してつねに揺らいだ値を示します。机上のシミュレーションでは、こうした外乱要因は入り込む余地がありません。検証で実際に得られた値が、想定された範囲にどの程度入ってくるかも併せて確認しておきましょう。
注
[3]: 筆者は「ビッグデータとはExcelで開けないデータのことだ」と同僚と冗談を言い合うことがしばしばあります。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)

