



































分析プログラムを入力し実行する
Jupyter Notebookの操作に慣れたところで、今回の分析プログラムをJupyter Notebook上に記述していきましょう。下表に記したプログラムを1セルずつ入力し、都度実行してください。表のFormat列は、セルのFormatを「Code」にして入力するか「Markdown」にして入力するかを表しています。
| Format | セルへの入力 |
|---|---|
| Markdown |
## Step1. Load Sensor data from Cloudant database |
| Code |
# Spark機械学習ライブラリの読み込み import sys from pyspark.mllib.clustering import KMeans, KMeansModel |
| Code |
# Cloudantに接続
sqlContext = SQLContext(sc)
motoDF = sqlContext.read.format("com.cloudant.spark").\
option("cloudant.host","HOSTNAME").\
option("cloudant.username", "USERNAME").\
option("cloudant.password","PASSWORD").\
load("TABLENAME")
|
| Markdown |
## Step2. KMeans training |
| Code |
# CloudantをSQL可能なテーブルとして定義
motoDF.registerTempTable("motoTable")
|
| Code |
# トレーニング用データをSQLで取り出し
sDatDF = sqlContext.sql("SELECT d.temp, d.objectTemp FROM motoTable")
|
| Code |
# 取り出したデータを整形 sDatArray = [] sDatArray.append(sDatDF.map(lambda x: [x[0], x[1]]).collect()) sDatArray = sDatArray[0] sDatArray.pop() sDatArray.pop(0) |
| Code |
# データ総数を表示 print "Number of Sensor Data: %d" % len(sDatArray) |
| Code |
# K平均法のトレーニングを実行 model = KMeans.train(sc.parallelize(sDatArray),4,100) |
| Markdown |
## Step3. divide into groups |
| Code |
# クラスタ判定用関数を定義 def myfunc(s): seed = [s.temp, s.objectTemp] numCluster = model.predict(seed) s2 = s.asDict() s2["cluster"] = numCluster return s2 |
| Code |
# 判定用データセットをCloudantから読み出し
srcDF = sqlContext.sql("SELECT d.name, d.temp, d.humidity, d.objectTemp, d.date FROM motoTable")
|
| Code |
# 個々のデータに対してクラスタ判定用関数を実行 retDictArray = srcDF.map(myfunc).collect() |
| Markdown |
## Step4. Count each group and found anomaly group |
| Code |
# アノマリークラスタの判定と、振り分けられたデータの数を確認
counts = {}
for rowDict in retDictArray:
clusterID = rowDict["cluster"]
if counts.has_key(clusterID):
counts[clusterID] = counts[clusterID] + 1
else:
counts[clusterID] = 1
anomalyKey = min(counts.items(), key=lambda x: x[1])[0]
print "Number of Suspected anomalies: %d" % counts[anomalyKey]
|
| Markdown |
### Appendix. Detailed output |
| Code |
# 実際にアノマリーと判定されたデータの出力(確認用) print >> sys.stderr, "Detailed Anomalies" for rowDict in retDictArray: if rowDict["cluster"] == anomalyKey: print >> sys.stderr, str(rowDict) |
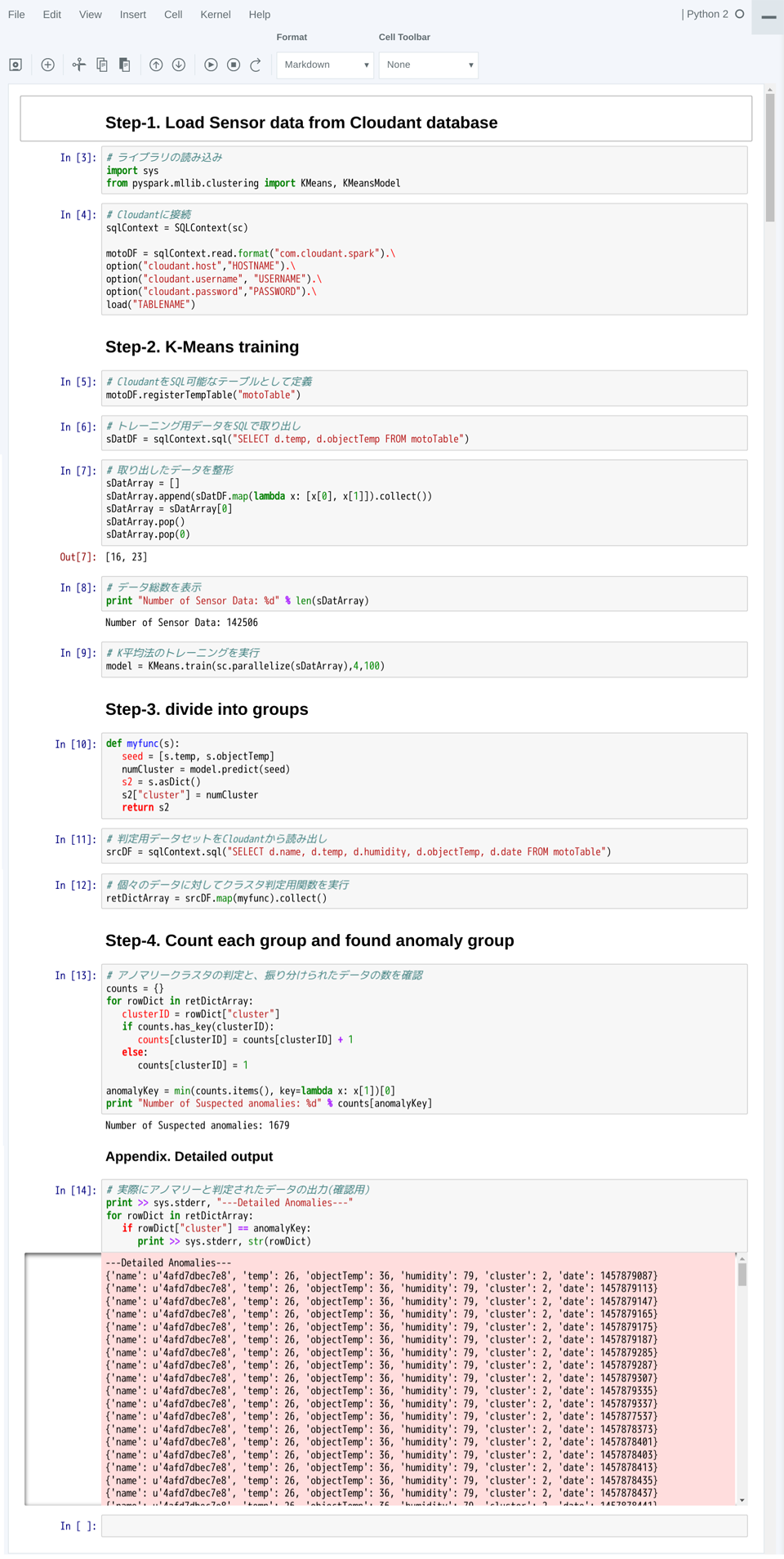
セルを1つずつ実行していく様子は、次のようになります。
最後の分析結果だけをクローズアップして見てみましょう。
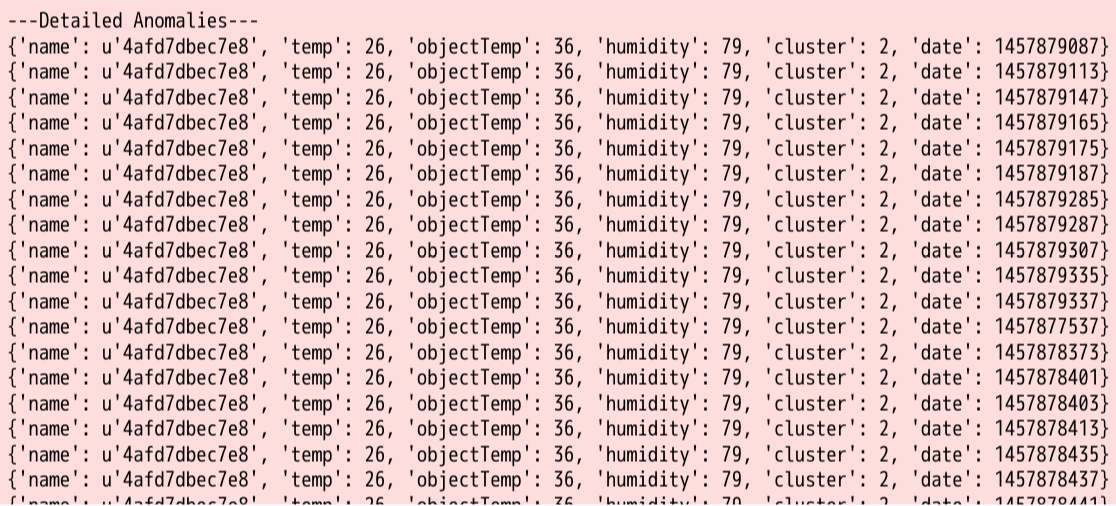
うまく「temp=26」を異なるグループに選り分けることができました。つまり約14万件のデータのうち1679個のデータを異常値であると考えることができます。
おわりに
IBM Bluemixで使用できるApache Sparkを活用した簡単なデータ分析例を紹介しました。Apache Sparkには今回使用したK平均法の他にも、様々な統計分析アルゴリズムが搭載されています。ただし、使用にあたっては今回述べたとおり、分析元のデータが何を示しているのか、何を見つければ正解であるのかを吟味して使用するようにしましょう。
また、IBM DeveloperWorks日本語版にはBluemixおよびApache Sparkに関する様々な活用例が紹介されていますので、ぜひ活用してください。
IoT成功のカギを握る:データ管理・分析クラウドサービスのご紹介
現象をデータ化するセンサーやデバイスに注目が集まりがちなIoTですが、価値を生むのはデータ化したその後の処理です。
「多数のセンサー、デバイスからインターネット経由で送信されてくるJSONデータを効率よく保管する」
「保管した大量のデータから未知のパターンを割り出し、ビジネスを成長させる知見を提供する」
こうしたIoTが価値を生むためのサービス・製品がIBMにあります。ぜひ、下記の資料をご覧ください。(編集部)


