「トラシュー」ほどエンジニアが学べる場はない
運用をしていると、いろいろなことが起きる。問題は自分のコードとは限らない。ミドルウェアの問題や一時的なシステム負荷など、原因はさまざまだ。問題が発生したら、トラブルシューティング(以下、トラシュー)を行う必要がある。
PagerDuty プロダクトエバンジェリスト 草間一人氏は「トラシューはいいですよ。トラシューアニマルになりましょう」と呼びかける。アニマルというのは草間氏にとって称賛だ。トラシューが好きになり、喜びすら感じるようなエンジニアになってほしいという願いがこめられている。

実際、草間氏自身も「トラシューを糧に生きてきました。これほど学べる場はない」と力説する。多くが緊迫して頭脳はフル回転、集中力が高まるので知識は定着するし、新たな知見を得られる場でもある。複雑にコンポーネントが絡み合うなかから原因を探るので、システム全体の解像度が上がり、切り分けをしながら論理的思考能力も高まる。トラシューからしか得られない「栄養」がある。
「だからこそ、自分が開発したものは自分で運用しましょう。開発者もオンコールのローテーションに入りましょう」と草間氏は提言する。組織が大きくなると開発と運用を分けるように組織が役割分担しがちだが、それは本当に正しいだろうか。
約20年前にAmazonが提唱した「You build it, you run it」に象徴されるように、開発した人自らが運用に責任を持つようになってきた。Netflixでは「フルサイクルデベロッパー」、PagerDutyでは「フルサービスオーナーシップ」と呼んでいるように「そのテクノロジーに最も精通した人が製品開発ライフサイクル全体の責任を引き受けるような運用モデルにしよう」という考えだ。
知っておくべきは「障害のほとんどはデプロイによって引き起こされる」ということだ。Will Larson著『エレガントパズル』でも指摘されている。そのためトラシューするなら、サービスを最もよく知る人物、つまり開発者がやるのが最も早くて効率的と言える。

開発者が運用やトラシューすることの意義もある。まずサービス品質が上がる。トラブルが起きたら自分の身に返ってくるため、開発者は問題を起こさないことに(当然考えているだろうが、さらに)意識を高め、結果として品質が向上する。また障害対応が迅速化する。開発者は経緯も含めてシステムを熟知しているため、原因特定や復旧が素早くできる。
開発者が普段から運用に関与すると、ユーザーのフィードバックや本番環境での稼働状況も目にしやすいため、それを開発に反映しやすくなる。さらに運用担当に集中しがちだった深夜対応などの負荷が開発にも分散されて、組織全体で信頼性向上に取り組む体制や姿勢が育まれる。
ここで運用が手を焼いてしまうようなアンチパターンを挙げてみよう。例えばアプリケーションから必要なログが出力されていない、またはログが不明瞭だと、運用側はエスパーのような超能力を発揮して原因究明しなくてはならない。逆にログが多すぎると、今度は運用側は「目grep力」を高めて情報を探すことになる。ログの出力方法が不適切ですぐに見つからない、監視用のフックが存在しないなんてこともある。
これらは明確なアンチパターンだが、運用していくなかで「ああすればもっと良くなる」と気づくポイントは多くある。運用に関与するとこうしたアンチパターンに早く気づき、修正しようという意欲につながる。
開発と運用が分かれていると、やるべき改善に気づいたとしても自分のタスクになかなか入れにくく、改善が遅くなってしまう。そのため開発と運用が一緒だと、開発する、障害が起きる、トラシューする、改善するといったサイクルを早く回しやすくなる。
サービスの安定性より優先されるベロシティに意味はない
開発者が運用をするだけではなく、緊急事態発生時に対応できるように待機するオンコールまで担うとなるとなかなかハードルが高い。なお、この呼び出しに使われるのがPagerDutyだ。もし開発者がオンコールのローテーションに入るとなると、いくつかの課題・疑問が生じる。
開発者がオンコールに入ればベロシティが悪化するのでは
この答えは「確かに、悪化する」。タスクが増えるのだから、当然といえば当然だ。草間氏は「ベロシティはあくまで目安であり、目標にしてはいけません。ベロシティを上げるために運用には携わらないとなると本末転倒です。サービスの安定性よりも優先されてしまうようなベロシティには意味はありません」と言う。
問題は特定の人に負荷が集中してしまうことだ。草間氏によると、組織規模にもよるが月に3〜4日程度が理想とされる。適切にスケジュールを組み、担当をばらしていくことが大事だ。
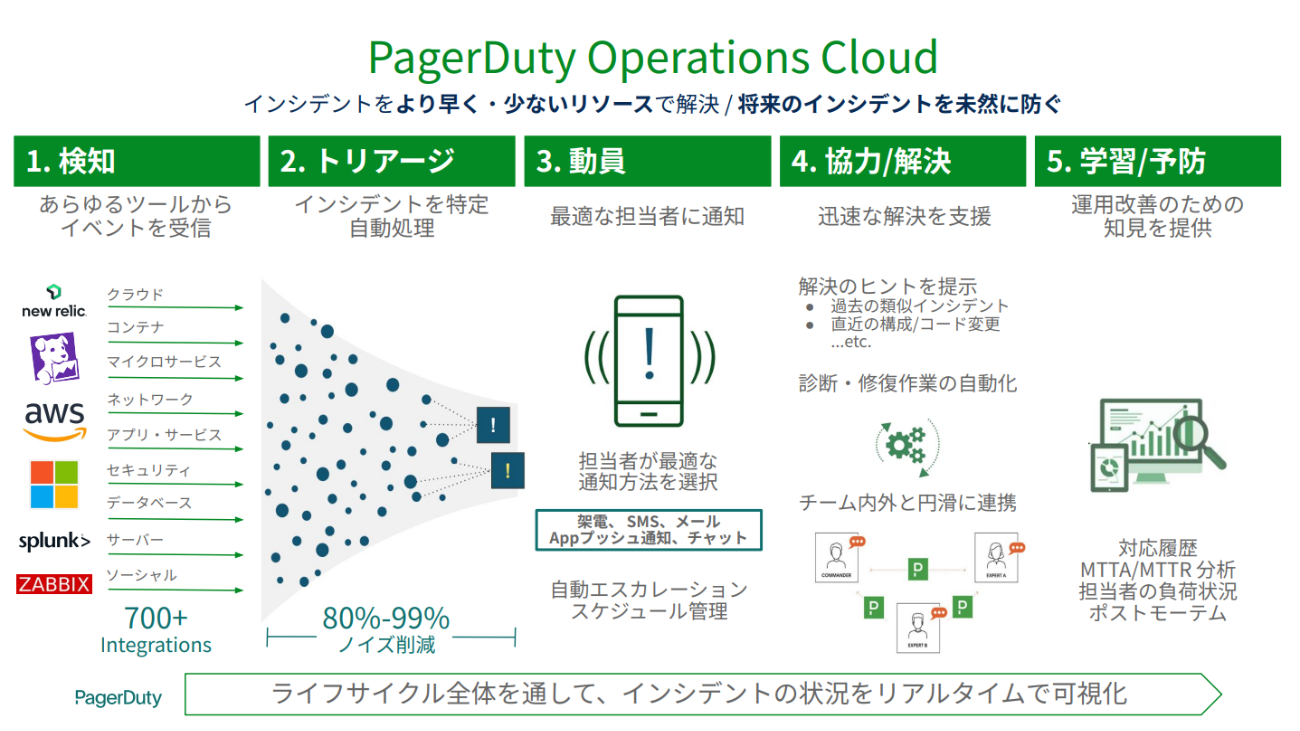
なおPagerDutyでは過剰に通知しなくてすむように、各種サービスから必要なアラートだけ絞り込み、本当に大事なインシデントの時だけ担当者を呼び出す。通知方法は電話やSMS、プッシュ通知、Slackなど選べる。また一次対応者が応答しない場合、二次対応者に通知するといったようにエスカレーションを設定することができる。こうした工夫により関係者に一斉通知することなく、負荷を最小限にすることができる。

オンコールはSREだけでやるべきでは?
この質問に対して草間氏は「ノー。SREは信頼性を高めるエンジニアリングの専門家であり、オンコール専任ではない」と答える。もちろんオンコールのローテーションには入ってもらう。企業によってはプロダクトに関するインシデントはプロダクトチーム、プロダクトをまたぐインシデントはSREチームというように、分担しているところもある。
草間氏は「大事なことは『開発者に運用もやらせる』のではなく、『ライフサイクル全体に責任を持たせる』という考え方です」と強調する。改善を続けることで、呼び出しの頻度を減らすことができる。

改善については開発者のコードだけではなく、SREが適切なSLI/SLOの設定や自動化なども行いながら協力して進めていくのが理想だろう。
心理的安全性の高いオンコール実現のための工夫
オンコールに入ると、心理的な負担が大きいのでは
呼び出しの頻度が減れば、先述したようなベロシティへの影響は少なく抑えられると予想できるものの、やはりスタンバイしているだけでも心理的な負担はあるだろう。ここは配慮が必要な重要なポイントだ。負担が積もると「燃え尽き」が起きてしまいかねない。
対策としては無理のないローテーションにする、深夜対応の翌日は半休や休日にするなどのルールを整備していくといいだろう。何よりも「職場の雰囲気作りが大事」と草間氏は言う。何かあれば相談しやすい雰囲気、心理的安全性が保てることが重要だ。
あとオンコールでも監視画面をずっと凝視する必要はない。呼ばれたら対処すればいい。いざとなったら見る監視画面もできるだけ不要なノイズを除去できるものがいい。そうすれば不要な呼び出しを減らすことにもつながる。
家庭の事情で深夜・休日のオンコールに入るのは厳しい
子どもが生まれたばかりや、親の介護などでオンコールに入るのが難しいメンバーもいるだろう。可能な限り対応したいものの、免除し過ぎると逆に不公平感を生んでしまい、士気や連帯感を損なってしまう。例えば一定期間だけ日中だけ担当、あるいはセカンダリ対応という分担にすることもできる。
あるいは「インシデント対応ではなく、ポストインシデントレビュー(ポストモーテム)のファシリテーターを担当してもらうのはどうでしょう」と草間氏は提案する。インシデントがなぜ起きたか振り返る場合、インシデント対応していない人のほうが客観的に分析ができる。改善のフィードバックでは大事な役割になるので、オンコールに入れないメンバーの選択肢の1つとして考慮しておきたい。
ポストモーテムでは、インシデントで起きたことを時系列に並べて分析したり、オペレーションミスがあったら関係者に事情を聞いたりする。ここで責めるように問いただしてはいけない。自動ではなく手動で作業しなくてはならなかったところに改善の余地があるからだ。例えば「マニュアルはあるけど、ボリュームがありすぎて該当箇所を探せず、記憶に頼って作業したら違うコマンドを打ってしまいました」なんてこともあるかもしれない。それならオペミスした人を責めるのではなく、やるべきはドキュメント整備ではないだろうか。
最後に草間氏は「インシデントを減らし、価値を生み続けるソフトウェア開発にはライフサイクルすべての責任を持つフルサービスオーナーシップが重要です。敬遠されがちなオンコールを開発者も担うことで、開発から運用まで含めてライフサイクルの改善につなげることができます。この一連のサイクルを実現するためにPagerDutyも貢献しています。ぜひトラシューアニマルになり、一緒にやっていきましょう」と呼びかけた。