





































AI時代において重要な「探索フェーズ」を阻むもの
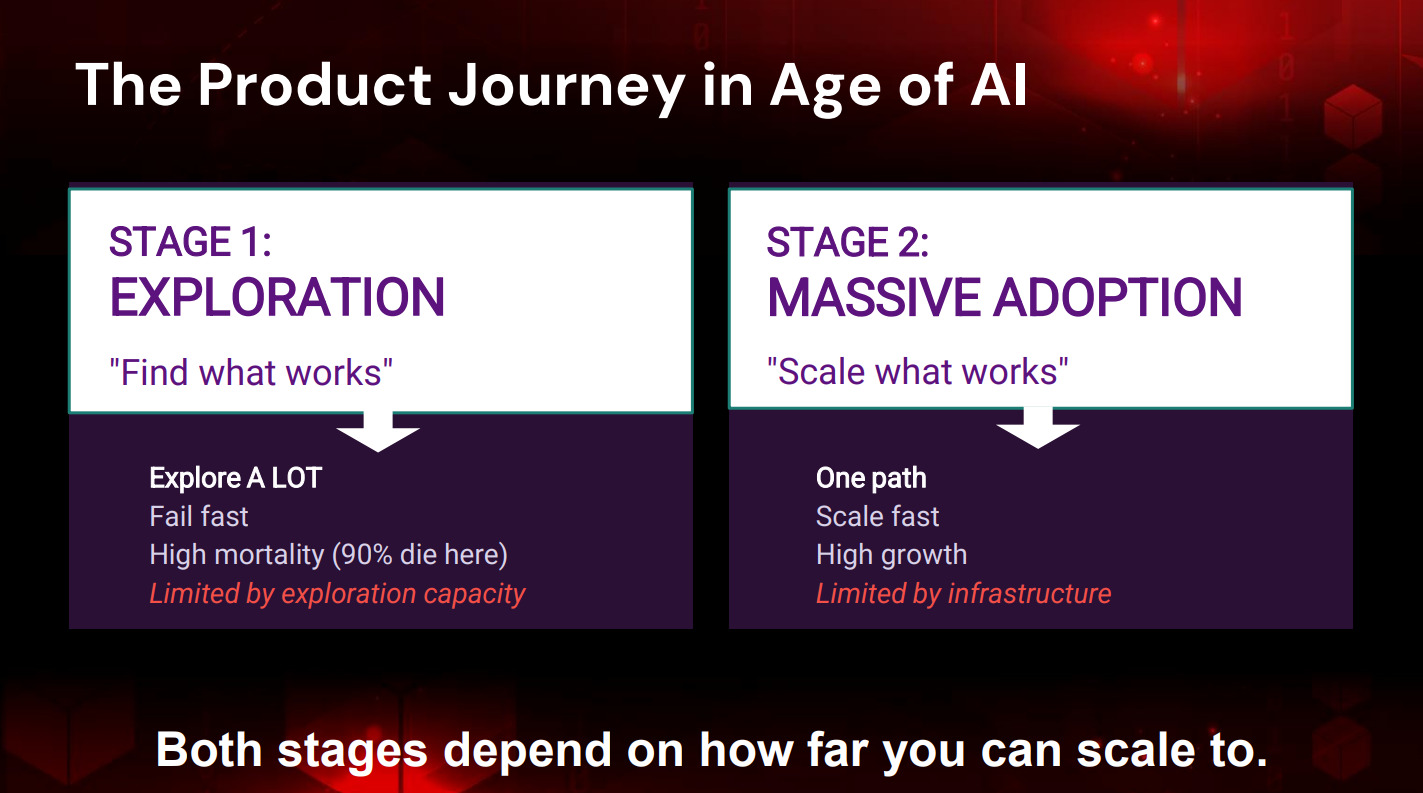
製品開発には2つの決定的な段階が存在する。第1段階は「Exploration(探索)」であり、複数のアイデアやプロトタイプを試し、市場で機能するものを見極める段階だ。この段階では「Fail Fast(早く失敗する)」の原則に従い、失敗した選択肢を素早く排除することが求められる。第2段階は「Massive Adoption(大規模採用)」であり、成功した製品が多くのユーザーに採用され、データが急速に増加し、インフラの限界と戦う段階である。
リュー氏自身も現役の開発者として、AI支援開発ツールを日常的に使用している。この新しい開発手法は「Vibe Coding(バイブコーディング)」と呼ばれており、リュー氏は会場の参加者にも経験者を挙手で募った。多くの手が上がる中、リュー氏は次のように語った。
「率直に言って、Claude CodeやCursorなどのバイブコーディングツールを使っていると、アイデアから製品に至るまでに必要な時間が大きく変わったと感じました」
この変化は単なる効率化ではない。AIエージェントの活用により、開発者は複数の可能性を並行して探索できるようになった。しかし、ここに根本的な課題がある。人間は一つのことに集中すれば高い成果を出せるが、同時に10個のことを高い品質でこなすことは困難だ。一方、AIエージェントはこの制約に縛られない。

リュー氏は、開発者がGitを使ってコードのブランチを作成し、新機能やバグ修正を並行して進めるように、「コードだけでなく、データ、コンテキスト、メモリに関しても、エージェントの観点からGitのようなものがあればどうでしょう」と問いかけた。そして、こう続けた。
「プロセスを10倍速く、もしかしたら100倍速くすることができたらどうでしょう。それは可能でしょうか? 答えは、自動化を次のレベルに引き上げる必要がある、ということです」
探索フェーズでの制約は、十分なリソースや、資金、エンジニアがいないことである。この制約のもとで成功率を高めるには、より多くの可能性を試す必要がある。しかし、従来のデータベースアーキテクチャでは、この高速かつ大量の試行錯誤を支えることができない。リュー氏は「常に制約に制限されてきました。もしその制約を取り除くことができれば、はるかに速く動き、成功率を大幅に向上させることができます」と述べた。
次世代データベースによって制約を解消する
分散型NewSQLデータベース「TiDB」はこれまで、一つのクラスターでペタバイト級のデータ処理や数百万のクエリ毎秒(QPS)やトランザクション毎秒(TPS)の処理を実現してきた。しかし、AI時代の探索フェーズを加速させるには、アーキテクチャの根本的な再設計が必要だった。PingCAPが導入したコア技術は、オブジェクトストレージを活用したコンピューティングとストレージの完全分離、そしてワークロード適応型の自動スケーリングである。
オブジェクトストレージを「新しいネットワーク」として活用する
従来のデータベースでは、スケールアウト時に既存のストレージノードからデータを複製する必要があり、この処理が既存トランザクションのパフォーマンスに影響を与えていた。TiDBの新アーキテクチャは、この問題を根本から解決している。リュー氏は次のように説明した。
「オブジェクトストレージ、S3は新しいネットワークです。この設計により、既存のストレージノードからデータをコピーすることなく、クラスターをスケールアウトできます」
各ストレージノードはデータをAmazon S3などのオブジェクトストレージに書き込む。クラスターを拡張する際は、新しいノードがS3から直接データを読み込むため、既存ノードへの負荷がない。さらに、各ノードにキャッシュ層を設けることで、S3からのデータ取得を高速化し、低遅延でのデータアクセスを実現している。この設計により、スケーリングプロセスが速くなり、既存のオンライン処理への影響を最小限に抑えられる。

ワークロードの分離による効率的なリソースの活用
もう一つの重要な革新が、ワークロードの徹底的な分離だ。従来のデータベースでは、軽量なオンライントランザクション処理(OLTP)と重いバッチ処理や分析処理(OLAP)が同じリソースを奪い合うというリソース競合が発生していた。TiDBは、これらを異なる種類のサーバーで処理する。
リュー氏は「コンピューティングとストレージを分離しました。これは、軽量なトランザクション処理と、重いバッチ処理(ETL、データのインポート・エクスポート、集計処理など)を分離することを意味します」と述べた。
この分離により、軽量なトランザクション処理専用のノードは、スパイクワークロード(負荷が急増する処理)に備えた過剰なリソース確保(オーバープロビジョニング)が不要になる。なぜなら、重い処理は別のノード群が担当するからだ。各ノードのCPU利用率を向上させつつ、無駄なコストを排除できる。
リュー氏はこれを「超スケーラブルに提供し、スケーリングプロセスを非常に速くし、オーバープロビジョニングに支払う必要がないため、コスト効率が高くなる」と説明した。

AIワークロードへの対応とマルチテナント機能
AI時代のデータベースに求められる要件は多岐にわたる。TiDBは以下の能力を一つのデータベースで実現している。
まず、数百万のテーブルを一つのクラスターで処理できる能力だ。リュー氏は「一つのデータベースで、これほどの数のスキーマとテーブルを処理できるのはTiDBだけ」と強調した。そして、この数百万のスキーマやテーブルの処理能力に加えて、昨年TiDBは、数百万規模のテナント(100万以上のテーブル)を処理できるようになった。テナントにクラスターを割り当てたり、複数のクラスターをテナントに割り当てたりすることができ、TiDBはそれらすべてのデータワークロードを同時に処理できる。
データ型の多様性も重要だ。リレーショナルデータやJSONといった構造化データに加え、ベクトルデータの保存とフルテキスト検索もサポートする。これにより、AIアプリケーションが必要とする多様なデータ形式を一つのデータベース基盤で扱える。
さらに、AI SDKの提供や主要な大規模言語モデル(LLM)フレームワークとの統合により、開発者は簡単にTiDBをAIエコシステムに統合して利用できる。リュー氏はこの新しいアーキテクチャを「Workload Adaptive Database」と呼び、workload-aware scale(ワークロード対応型スケーリングモデル)を採用した次世代データベースを提供していくという。

