




































データの本質を理解するには現場の業務プロセスの理解が不可欠
斎藤氏は、「(1)データ/品質の調査(2)パイプライン作成(3)カタログ作成(4)データマート公開」の4つのステップでプロジェクトを進めていったという。最初の2ステップを詳しく紹介する。
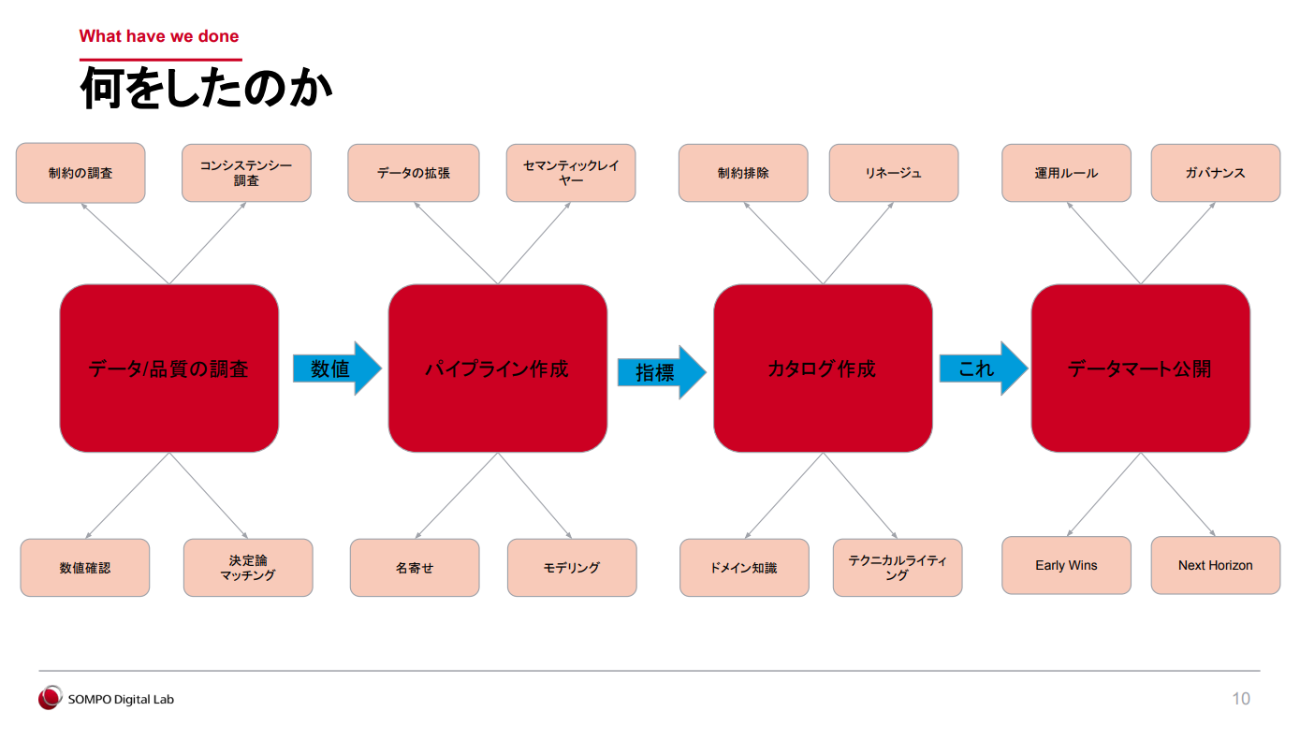
(1)データ/品質の調査
斎藤氏が「プロジェクトの成否を左右する最も大事なステップ」と語るのが、この「データ/品質の調査」だ。これは単なるデータの正誤チェックではなく、各部門で実際に使われているデータの意味や背景(≒ドメイン知識)を深く理解する作業とも言える。
このなかで、斎藤氏がまず取り組んだのが、「外部整合性のチェック」である。たとえばA部門とB部門がそれぞれ保有する火災のデータを突き合わせたところ、700万件中2万件で、親データが存在しない「オーファンレコード」が見つかったという。こうしたケースでは、アスタリスクのような記号の混入や入力ミスの可能性を疑い、各部門の担当者へのヒアリングなどを通じて、原因を解明していく。
ある程度データの整理が進んだら、実際のデータと想定される「期待値」を比較して、ズレがあればその要因を掘り下げていく。処理ロジックの誤りなのか、データの欠落や偏りなのか——地道な原因究明作業が続くのである。
さらには、メタデータの整備も並行して進めながら、決定論的マッチングによるデータの名寄せも行った。「データ分析基盤の『データプロファイリング機能』によってデータの分布や異常値を効率的に把握できたことが、作業効率を大きく高めた」と斎藤氏は振り返る。
こうした作業は、一度で完結するものではない。何度も試行錯誤を重ねながら、地道にデータの“素性”を明らかにしていったという。
(2)パイプライン作成
次のステップである「パイプラインの作成」では、複数のデータソースから取得したデータを、分析や共有が可能な形式に加工していく。ここで斎藤氏が強く意識したのは、「表記のばらつきや特殊なデータ構造といった元データ特有の制約をできるだけ排除して、カタログに記述する内容をできるだけシンプルにすること」だった。
これにより、利用者は元データのクセを意識することなく、直感的にデータにアクセスできるようになるし、カタログやパイプラインの保守性も高まるという。
また、データ基盤の設計では、柔軟性と再現性を重視している。具体的にいうと、同社が利用しているPalantir Foundryには「Ontology」というセマンティックレイヤーがあり、そこからAPI経由で集計を行うことが可能だ。そのため、データに複雑な計算ロジックを持たせず、後段のレイヤーに処理を委ねる方針を採用している。
本来であれば、セマンティックレイヤーを通じてデータを提供するのが望ましいが、今回のプロジェクトでは時間的な制約があったため、暫定的にスタースキーマを用いてデータを正規化し、Silver層で品質チェックをしたうえで、ワイドテーブル形式で提供する形とした。



