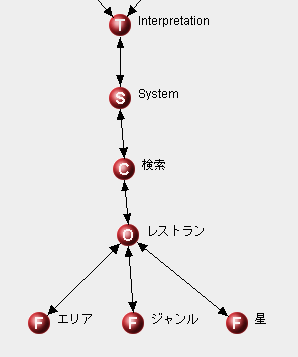
エージェントのパラメータ設定
エージェントの役割が決まったら各エージェントの振る舞いを決めるためのパラメータを設定します。主なパラメータとしては以下にあげたものがあります。他にもたくさんのパラメータがありますが、連載の中で徐々に解説していきたいと思います。
語彙
エージェントがクレームをするための語彙です。例えばエリアを表す語彙として「エリア」「場所」「地区」などが考えられます。これらのうち代表の語彙をキーワード、その同義語をシノニムと呼びます。先の例ではキーワードを「エリア」、同義語が「場所」「地区」となります。
属性値
Fieldの役割を持つエージェントには属性値が定義できます。値の例としてはエリアなら「赤坂」「銀座」、ジャンルなら「寿司」「フレンチ」などになります。
文法規則
文章解析のための文法規則を調整します。調整の例としては、入力にキーワードがあればクレームする、属性値があればクレームをする、または両方入力されたときのみクレームをするなどがあります。
未知語認識の有効/無効
未知語に対してエージェントとがクレームをするか、どのような規則で未知語とみなすかを設定します。ただし日本語の環境では使用を控えたほうがよいため無効に設定します。
文脈追跡の調整
文脈追跡の動作を調整します。
ここでは「エリア」「ジャンル」「星」のそれぞれのエージェントについて検索条件となる属性値を設定することにします。「エリア」エージェントには地名を属性値として指定します。このエージェントをダブルクリックし知識設定画面である「Agent Editor」を開きます。たくさんの設定項目がありますが、ほとんどは初期値が設定されているため、設定するべき箇所はそれほどありません。例えば、「Keyword」については役割を割り当てた際にエージェント名が自動で設定されます。
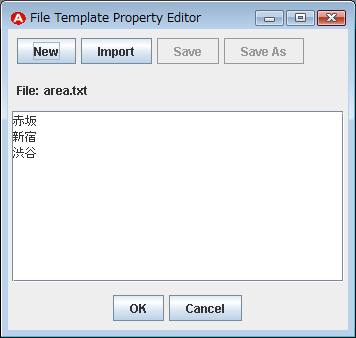
属性値を設定する方法はいくつかありますが、一番簡単なテキストファイルに値を格納する方法で行いたいと思います。 [File]ボタンを押し「File Template Property Editor」を開きます。エディタ上に値を1行づつ記述し[Save]を押してファイルに保存をします。保存したら[OK]を押し、さらに「Agent Editor」の[OK]を押して変更をエージェントに反映させます。「ジャンル」「星」の各エージェントにも同様に表2に示す属性値の設定を行います。
| エージェント | 値 | 保存するファイル |
| エリア | 赤坂 新宿 渋谷 |
area.txt |
| ジャンル | 中華 イタリアン 寿司 |
genre.txt |
| 星 | 1 2 3 |
stars.txt |
エージェント「エリア」「ジャンル」「星」の文法規則と、未知語認識のパラメータにも変更を加えます。文法規則のパラメータ[Maybe Explicit Match]にチェックを入れ、未知語認識のパラメータ[Support Left Guess][Support Right Guess][Support Middle Guess]はチェックをはずします(図11)。文法規則の設定ではキーワードと属性値の両方が入力に含まれることを許可し、未知語認識の設定ではこの機能を無効にしています。なぜこの設定をするかという詳細な説明は省略しますが、エージェントが日本語の環境で自然に文章解析をするための定石だと覚えてください。

トークン分割辞書ファイルの作成
エージェント・ネットワークは文章解析の際に、トークンという単位で語彙を認識しクレームをします。解析対象が英語であれば語と語の間に空白があるためそれをトークン区切りとして使用します。しかし、日本語の場合には空白を語の区切りとして利用することができません。そこで、Answers Anywhereでは、ひらがな、カタカナ、漢字等の文字種の変化部分を区切りとしてみなします。ただし、このような機械的なやり方では対応できない入力もあるためトークン分割辞書というものを使用し、そこに登録されている語をトークンとして区切りを行います(図12)。

トークン分割辞書ファイルはAnswers AnywhereのSDKでは作成できないので、別途テキストエディタで作成し、エージェント・ネットワークのプロジェクト・フォルダに「single.txt」という名前で配置します。このファイルには分割の単位としたい語を1行づつ記載します。どのような語を選んだらよいかですが、ひとつの基準として各エージェントに設定されている日本語のキーワードと同義語の一覧があげられます。今回の例では「検索」「レストラン」「エリア」「ジャンル」「星」がその語彙となります。ファイルを記述し保存したら、エージェント・ネットワークに読み込ませるため、作成中のエージェント・ネットワークをいったん保存し再度開きなおします。

エージェント間の関係構築
最後にエージェント間の関係を構築します。作り方はリスト3に示すような機械的なルールとなります。
リスト3 エージェント間の関係ルール
- 親System → 子Command
- 親Command → 子Object
- 親Object → 子Field
親となるエージェントの上にマウスカーソルを持っていき右ボタンを押します。そのまま子の上までカーソルをドラッグしてボタンを離すことで作成できます。

リスト3のルールに従い、すべてのエージェントの間に関係をつけたものを図15に示します。