





































1. はじめに
「Answers Anywhere」は、自然言語で入力されたユーザーの指示から意図を汲み取り、対話をしながら機器操作やデータ検索するシステム構築のためのミドルウェアです。連載第1回では概要やインストール方法、第2回ではどのように動くのかについて紹介してきました。今回はこのAnswers Anywhereを使い、日本語の質問で対話的にデータベースを検索するシステムを開発してみましょう。
データベースにはレストランのデータが格納されており「赤坂の3つ星イタリアンは?」というような質問で検索をします。また、図1のイメージに示すように自由に条件の追加や変更ができます。まるでコンシェルジュに相談しながらレストランを探しているような、未来的な感じのアプリケーションです。

2. アプリケーション仕様
レストランのデータはデータベース上の表1に示すスキーマのテーブルに格納されています。実際のアプリケーションではエリアやジャンルは別テーブルに格納されるような設計が普通かと思いますが、今回は単純化のために1つのテーブルにすべての値を格納することにします。
| カラム名 | 型 | データ内容 |
| rid | integer | レストランのID(連番) |
| rname | varchar(50) | レストラン名 |
| area | varchar(16) | エリア名 |
| genre | varchar(16) | ジャンル名 |
| stars | integer | 評価(なし(NULL)、1、2、3) |

今回作成する検索アプリケーションの仕様は次のとおりです。
リスト1 検索アプリケーション仕様
- 文章で検索条件を入力し、表1に示すテーブルからレストランのデータを検索する
- 検索条件はエリア名、ジャンル名、評価を検索条件とする
- 検索条件は、順不同または一括での指定、置き換えができることとする
3. データベースの準備
今回作成するアプリケーションでは、Answers Anywhereと同じアイエニウェア・ソリューションズが開発・販売しているデータベースSQL Anywhere 11を使用します。商用データベースではありますが、開発用途またはデータベースとWebサーバーが同一PCに載るような小規模なWebシステムであれば無料で使用できます。システムに組み込んで使用でき、管理の手間がほとんどかからないことが特長のデータベースです。
SQL Anywhere は別途PCへのインストールが必要となります。お持ちでない方は弊社ダウンロードページからSQL Anywhere Developer Edition開発者版を入手してください。インストール方法は難しくありませんが、管理ツールの簡単な説明も含め「SQL Anywhereのインストールと概要」に解説がありますのでご覧ください。
インストールが完了したらサンプルのデータベースファイル「RestaurantSearch_database.zip」をダウンロードしてください。zipを展開し同梱のodbc_setup.batを実行するとデータベースファイルrestaurant.dbがODBCデータソースrestaurantに登録されます。
Answers Anywhere はデータベースにアクセスする手段としてJDBCを使用しますので、他にもJDBCに対応しているデータベースであれば問題なく使用できます。今回は設定を簡単にするためにサン・マイクロシステムズ社のJavaに標準で付属しているJDBC-ODBCブリッジを使用してSQL Anywhereに接続します。
4. エージェント・ネットワークの設計
Answers Anywhereではデータを構成する要素を概念モデルで記述しますが、そのモデルをエージェント・ネットワークと呼んでいます。エージェント・ネットワークの働きや構造については前回の記事で解説しました。
これを基に今回想定したアプリケーションの仕様にあてはめてみましょう。
まずアプリケーションの範囲ですが、「レストラン全体の中から条件に合致したものを検索」となります。範囲が決まったらそれらを処理の最小単位に分割します。このときは操作の内容(Command)、操作の対象(Object)、対象の持つ属性(Field)という区分で考えます。この区分で考えた分割結果をリスト2に示します。
リスト2 アプリケーション範囲の分割
- 操作の内容(Command)
- 検索
- 操作する対象(Object)
- レストラン
- 対象の持つ属性(Field)=条件とするレストランの属性
- エリア名、ジャンル名、星(評価)
5. エージェント・ネットワークの構築
新規プロジェクト作成
それではエージェント・ネットワークの構築を始めます。Windowsの[スタート]メニュー-[すべてのプログラム]-[Answers Anywhere Platform 5.2.0]-[Agent Network Development Environment]の順に選択し、Answers Anywhereの開発環境であるANDEを起動します。
まず新規のプロジェクトを作成します。メニューの[File]-[New]-[Project]の順に選択すると「New Project」ダイアログが表示されます(図3)。
以下の項目を入力し[OK]を押すと指定したフォルダ以下にプロジェクト名と同名のフォルダが作成され、そこにエージェント・ネットワークのファイルが保存されます。
- Project Name:RestaurantSearch
- Project Folder:任意の保存先フォルダ
ANDEの画面上には図4の初期エージェント・ネットワークが表示されます。
次にエージェント・ネットワークで日本語が使えるようにする設定をします(注1)。メニューから [Edit]-[Set Locale]を選択すると「Set Network Locale」ダイアログが表示されます(図5)。Default Locale を ja_JP に変更し[OK]を押します。この設定により、単語最小長、文字コード範囲、単語分割モードなどが日本語処理に適した値に調節されます。ここまではエージェント・ネットワークを初期構築する場合の共通手順となります。
バージョン5.2の場合、New Project ダイアログで選んだロケールが効かないという問題があるのでこの設定が必要です。
エージェントの配置
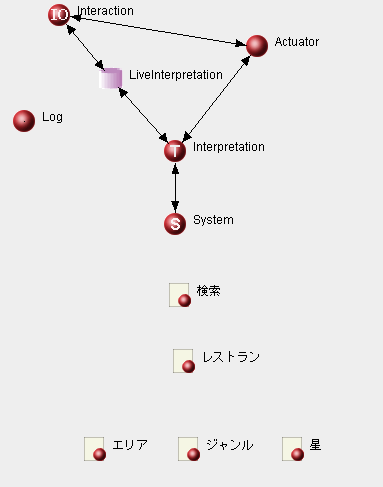
エージェント・ネットワークの編集画面の上で右クリックし[New agent]を選択すると新規エージェント作成のダイアログが表示されます。「Name」にエージェント名を指定して[OK]を押すとエージェントが配置されます。

この手順を繰り返し、リスト2で決めた処理の最小単位をすべてエージェントとして配置します。配置後のエージェント・ネットワークを図7に示します。
エージェントの役割を決める
配置したエージェントは何も定義を持たない空のエージェントです。次のステップではこれらに役割を与えます。リスト2ではCommandやObjectなどの区分を決めて分割しましたが、この区分が役割に相当します。「検索」エージェントを右クリックしてサブメニューを出し、[Apply Template]を選択してください。「開く」ダイアログが開くので、command.templateを選択し[開く]を押します。最後に「Template Editor」ダイアログが開くので[了解]を押すと「検索」エージェントにCommandという役割が与えられ、 というアイコンで表示されます。
というアイコンで表示されます。

同様に、「レストラン」エージェントにはobject.templateを選択してObjectの役割、「エリア」「ジャンル」「星」にはfield.templateを選択してFieldの役割を与えます。それぞれアイコンは と
と になります。どのエージェントがどの役割を持っているのか視覚的に分かりやすいですね。
になります。どのエージェントがどの役割を持っているのか視覚的に分かりやすいですね。
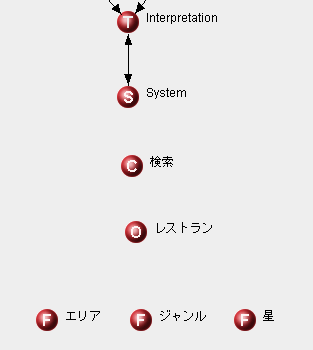
エージェントのパラメータ設定
エージェントの役割が決まったら各エージェントの振る舞いを決めるためのパラメータを設定します。主なパラメータとしては以下にあげたものがあります。他にもたくさんのパラメータがありますが、連載の中で徐々に解説していきたいと思います。
語彙
エージェントがクレームをするための語彙です。例えばエリアを表す語彙として「エリア」「場所」「地区」などが考えられます。これらのうち代表の語彙をキーワード、その同義語をシノニムと呼びます。先の例ではキーワードを「エリア」、同義語が「場所」「地区」となります。
属性値
Fieldの役割を持つエージェントには属性値が定義できます。値の例としてはエリアなら「赤坂」「銀座」、ジャンルなら「寿司」「フレンチ」などになります。
文法規則
文章解析のための文法規則を調整します。調整の例としては、入力にキーワードがあればクレームする、属性値があればクレームをする、または両方入力されたときのみクレームをするなどがあります。
未知語認識の有効/無効
未知語に対してエージェントとがクレームをするか、どのような規則で未知語とみなすかを設定します。ただし日本語の環境では使用を控えたほうがよいため無効に設定します。
文脈追跡の調整
文脈追跡の動作を調整します。
ここでは「エリア」「ジャンル」「星」のそれぞれのエージェントについて検索条件となる属性値を設定することにします。「エリア」エージェントには地名を属性値として指定します。このエージェントをダブルクリックし知識設定画面である「Agent Editor」を開きます。たくさんの設定項目がありますが、ほとんどは初期値が設定されているため、設定するべき箇所はそれほどありません。例えば、「Keyword」については役割を割り当てた際にエージェント名が自動で設定されます。
属性値を設定する方法はいくつかありますが、一番簡単なテキストファイルに値を格納する方法で行いたいと思います。 [File]ボタンを押し「File Template Property Editor」を開きます。エディタ上に値を1行づつ記述し[Save]を押してファイルに保存をします。保存したら[OK]を押し、さらに「Agent Editor」の[OK]を押して変更をエージェントに反映させます。「ジャンル」「星」の各エージェントにも同様に表2に示す属性値の設定を行います。
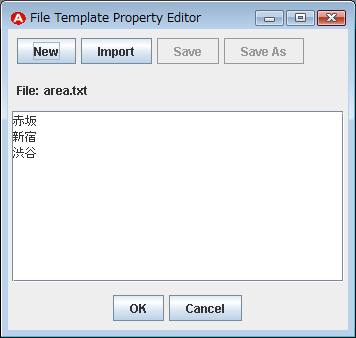
| エージェント | 値 | 保存するファイル |
| エリア | 赤坂 新宿 渋谷 |
area.txt |
| ジャンル | 中華 イタリアン 寿司 |
genre.txt |
| 星 | 1 2 3 |
stars.txt |
エージェント「エリア」「ジャンル」「星」の文法規則と、未知語認識のパラメータにも変更を加えます。文法規則のパラメータ[Maybe Explicit Match]にチェックを入れ、未知語認識のパラメータ[Support Left Guess][Support Right Guess][Support Middle Guess]はチェックをはずします(図11)。文法規則の設定ではキーワードと属性値の両方が入力に含まれることを許可し、未知語認識の設定ではこの機能を無効にしています。なぜこの設定をするかという詳細な説明は省略しますが、エージェントが日本語の環境で自然に文章解析をするための定石だと覚えてください。

トークン分割辞書ファイルの作成
エージェント・ネットワークは文章解析の際に、トークンという単位で語彙を認識しクレームをします。解析対象が英語であれば語と語の間に空白があるためそれをトークン区切りとして使用します。しかし、日本語の場合には空白を語の区切りとして利用することができません。そこで、Answers Anywhereでは、ひらがな、カタカナ、漢字等の文字種の変化部分を区切りとしてみなします。ただし、このような機械的なやり方では対応できない入力もあるためトークン分割辞書というものを使用し、そこに登録されている語をトークンとして区切りを行います(図12)。

トークン分割辞書ファイルはAnswers AnywhereのSDKでは作成できないので、別途テキストエディタで作成し、エージェント・ネットワークのプロジェクト・フォルダに「single.txt」という名前で配置します。このファイルには分割の単位としたい語を1行づつ記載します。どのような語を選んだらよいかですが、ひとつの基準として各エージェントに設定されている日本語のキーワードと同義語の一覧があげられます。今回の例では「検索」「レストラン」「エリア」「ジャンル」「星」がその語彙となります。ファイルを記述し保存したら、エージェント・ネットワークに読み込ませるため、作成中のエージェント・ネットワークをいったん保存し再度開きなおします。

エージェント間の関係構築
最後にエージェント間の関係を構築します。作り方はリスト3に示すような機械的なルールとなります。
リスト3 エージェント間の関係ルール
- 親System → 子Command
- 親Command → 子Object
- 親Object → 子Field
親となるエージェントの上にマウスカーソルを持っていき右ボタンを押します。そのまま子の上までカーソルをドラッグしてボタンを離すことで作成できます。

リスト3のルールに従い、すべてのエージェントの間に関係をつけたものを図15に示します。
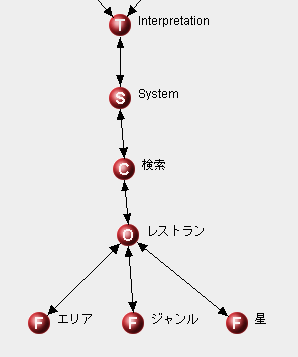
6. 意味解析のテスト
ここまでの作業でエージェント・ネットワークが日本語の質問から意図を抽出してくれるようになりました。意味解析の動作を試すには「Interaction Console」を使います。[Ctrl]+[I]を押して「Interaction Console」を表示し、「User Input」フィールドに質問を入力し[Apply]を押します。質問から意図が抽出され解析結果XMLに変換されます。例えば「赤坂のイタリアン」と入力すると、それは「検索」という操作(Command)で、対象(Object)は「レストラン」、その条件(Field)が「エリア=赤坂」「ジャンル=イタリアン」と認識されます。認識の結果はエージェント名をタグとしたXMLで出力されます。

7. 検索処理の実行
解析結果XMLだけでは結果が得られないので、これをSQLに変換しデータベースへの検索処理が実行されるようにします。この処理はエージェント・ネットワークの上方にあるActuatorエージェントに登録されるサービスプロバイダというモジュール(Service Provider)で行われます。サービスプロバイダは複数登録でき、それぞれにXPathに似た式(以降XPath式と略記)を持ちます。このXPath式で解析結果XMLを評価し、合致したサービスプロバイダが呼び出されます。
サービスプロバイダを登録するには、Actuatorエージェントをダブルクリックします。「Actuator Agent Editor」という設定ダイアログが表示されます。サービスプロバイダを登録するには[New]を押します。この画面ではサービスプロバイダを起動するためのXPath式をXPath expressionに設定します。検索コマンドが実行されたときにサービスプロバイダを起動したいのですが、この場合はXMLに<検索>というタグが含まれるで「//検索」と記述します。タグ名の前に/を2つ重ねてつけるとルートのXMLノードとすべての子孫ノードに対してタグの存在をチェックします。次に起動するサービスプロバイダのJavaクラス名を設定します。[Change]ボタンを押すとJavaクラスを選ぶダイアログが表示されるので、com.dejima.serviceProvider.DatabaseServiceProvider をプルダウンより選択します。このサービスプロバイダは、解析結果XMLをselect文のSQLに変換してデータベースからデータを検索する機能を持ちます。

Javaクラスを選んだ後[OK]を押すとDatabaseServiceProviderの設定画面が開きます(図18)。ここでは表3に示す項目を設定します。また今回のアプリケーションでは使用しませんが他に表4に示すような設定項目があります。

| 項目名 | 内容 | 設定する値 |
| Sql Configuration | SQL変換ルールを記述した設定ファイル | 後述 |
| Datasource | JDBC URLサブネームの文字列 | restaurant |
| Driver | JDBCドライバのクラス名 | sun.jdbc.odbc.JdbcOdbcDriver |
| Url | JDBC URLサブプロトコルまでの文字列 | jdbc:odbc: |
| 項目名 | 内容 |
| Username | JDBCログインユーザー名 |
| Password | JDBCログインパスワード |
| Execute SQL | SQLを実行するかどうか。チェックをはずすとSQLの生成のみを実施 |
| Max Results | 検索する最大行数 |
Sql Configurationには解析結果XMLからSQLへの変換ルールを記述したXML設定ファイルを記述します。[Sql Configuration]ボタンを押すとエディタが開きます(図19)。

手ですべて記述してもよいのですが、編集画面にある[Generate]ボタンを押すとエージェント・ネットワークの構造を解析し雛形を自動生成してくれます(リスト4)。
<SqlProperties>
<TableProperties>
<Table name="レストラン" agent="レストラン.com.dejima.templates.TemplatizedAgent@x"
tag="レストラン" primaryKey="ID">
<Column name="エリア" datatype="STRING" useQuotes="true" path="エリア" />
<Column name="ジャンル" datatype="STRING" useQuotes="true" path="ジャンル" />
<Column name="星" datatype="STRING" useQuotes="true" path="星" />
</Table>
</TableProperties>
</SqlProperties>
自動生成された設定を実際に使用するテーブルに合わせ、テーブル名、列名、列の型を修正します(リスト5:太字部分)。修正が終わったら[Save As]を押し設定ファイルを保存します。ファイル名は何でもよいですがデフォルトのファイル名「sql.xml」で保存します。
<SqlProperties>
<TableProperties>
<Table name="restaurant" agent="レストラン.com.dejima.templates.TemplatizedAgent@x"
tag="レストラン" primaryKey="rid">
<Column name="area" datatype="STRING" useQuotes="true" path="エリア" />
<Column name="genre" datatype="STRING" useQuotes="true" path="ジャンル" />
<Column name="stars" datatype="INTEGER" useQuotes="true" path="星" />
</Table>
</TableProperties>
</SqlProperties>
設定できたら[Ok]を押して変更を反映させます。サービスプロバイダは設定ダイアログの階層が深いのですべてのダイアログで[Ok]を忘れないように注意してください。
8. 動作確認
Interaction Consoleを開き「赤坂のイタリアン」と入力してみましょう。入力から要素が抽出され解析結果XMLが生成されるところまでは先ほどと同じですが、そこからSQLが生成されデータベースからレストランのデータが検索されます。SQLと検索されたデータは解析結果XMLに付加されて出力されます(リスト6)。

文脈を使用した対話的検索も試してみましょう。エージェント・ネットワークのデフォルトの設定では入力に「..」(ドット2つ)を付加することで質問を継続できます。「..新宿では」と入れると条件「赤坂」が「新宿」に置き換えられ「エリア=新宿 かつ ジャンル=イタリアン」のレストランが2件検索されます。「..3つ星」のところと入れると今度は条件が付加されて「エリア=新宿 かつ ジャンル=イタリアン かつ 星=3」という条件でデータを絞り込みます。
9. おわりに
Answers Anywhereを使うと日本語で対話的にデータベースを検索するシステムが、簡単に構築できることが理解していただけたのではないかと思います。1つのテキスト入力により各フィールドを横断的に検索した結果がXMLで出力されますので、クラウドにおくことでフリーワード検索を持ったWebサービスにも利用できるかと思います。
次回はこのサンプルを拡張して、Webで扱いやすいように出力をHTMLに変換する方法や、また別の対話機能として必須項目を入力するようユーザーに通知する方法などを解説をしたいと思います。

