





































リアルタイム分析とオブザーバビリティの進化
松本氏はClickHouseのシニアサポートエンジニアであり、大規模検索エンジンの開発・運用を経験した後、外資系ベンダーでプロフェッショナルサービスに従事した。ClickHouseの日本人社員第1号として入社し、現在は導入支援や技術サポートを担当している。

セッションは、リアルタイム分析データベースの進化から始まった。松本氏は、2024年のStack Overflow開発者調査を引用し、SQLが2番目に人気のあるプログラミング言語であることを紹介。SQLは約50年前にオラクル社が発表し、その25年後にOLAP(オンライン分析処理)技術が登場。Oracle Hyperion EssbaseやMicrosoft SSASといったBI向け高速解析ツールが開発されたが、高価で利用が限られていた。
約10年前にはSnowflakeをはじめとするクラウドデータウェアハウスが登場し、データ解析の民主化が進んだ。しかし、データ量の増加によるコストの高騰やリアルタイム処理の難しさが課題となり、リアルタイムOLAPへの需要が高まった。こうした背景から、ClickHouseをはじめとするオープンソースOLAP製品が注目されている。
オブザーバビリティの概念もSQLと同様に約50年前に登場したものだ。約25年前にはUNIXやLinux環境でSyslogが導入され、サーバーログの統合が進んだ。約10年前にはElastic Stackをはじめとするログ管理ツールが普及し、リアルタイムのシステム監視が可能になった。現在ではDatadogやSplunkなどのSaaS型ツールが広く利用され、システム運用の中心を担っている。
しかし、オブザーバビリティツールはデータ量の増加に伴い、他の製品へ移行しにくいベンダーロックインの問題を抱えている。この課題に対応するため、オープンソースによる標準化の動きが進んでおり、その代表例がOpenTelemetryだ。Linux Foundationの主要プロジェクトとして、標準的なテレメトリーデータの収集・管理を実現。さらに、可視化ツールとしてGrafanaが広く活用され、オープンソースを活用した柔軟な運用が進んでいる。
松本氏は「SQLベースのオブザーバビリティが近年注目を集めている」と語る。その背景には、大量データの管理という課題がある。オブザーバビリティでは長期間データを保持したいニーズがあるが、コストやパフォーマンスの制約により、実際には1カ月、短い場合は1週間程度しか保存できないことが多い。

SQLベースのオブザーバビリティは、大規模データを扱う企業にとって有利な選択肢となる。この手法ではコストを10分の1から20分の1に抑えられるため、移行が加速しているという。
「DeepSeekパニック」でも話題になったClickHouseとは
オブザーバビリティのアーキテクチャは「データ収集」「ストレージ」「可視化・アラート」の3層で構成され、SQLを活用することで効率化が進む。ClickHouseはこのうちストレージ領域を担い、コスト削減とパフォーマンス向上を実現する。
ClickHouseは2009年に開発が始まり、2016年にオープンソース化された。列指向の構造により高圧縮・高速解析を実現し、分散処理に対応することで大規模データの管理が容易になる。OLAPデータベースとして、大規模なデータ解析に適している。なお、MySQLやPostgreSQLなどはOLTP(オンライン・トランザクション処理)データベースとされ、トランザクション管理に特化している。

「ClickHouseはトランザクションではなく、データ分析向けのデータベース。トランザクション処理が必要なら従来のデータベースを、大規模なデータ解析にはClickHouseが適している」と松本氏は説明した。法人としてのClickHouse, Inc.は2021年に米国で設立され、Google Cloud、AWS、Azureでマネージドサービスを提供している。
オープンソースの分野での影響力も大きく、2016年のオープンソース化以降、多くのプルリクエストを受け、2023年にはApache Sparkに次ぐ2番手の位置を占めた。ClickHouseの利用方法には、セルフマネージドとマネージドサービスの2つがあり、自社運用が可能なほか、Amazon S3やApache Kafkaとの統合機能を備えたマネージドサービスも提供されている。
ClickHouseはさまざまな分野で活用でき、特に「ログ・イベント・トレース」「リアルタイム分析」「BI」「機械学習・生成AI」の4領域に強みを持つ。リアルタイム分析では、異常検知やWebトラフィック解析などに利用され、BIの分野ではSnowflakeの代替として活用される。さらに、機械学習や生成AIにおいては、大規模な学習データの保存・検索に適している。
松本氏は「DeepSeekが話題になった際、大量のデータを保持するためにClickHouseが使用されていることが明らかになり、その情報が広まったことでClickHouseも注目された」と話した。
ClickHouseの活用事例:Uberと自社での導入
続いて松本氏は「ログ、イベント、トレース」分野におけるClickHouseの活用事例を2つ紹介した。1つ目はUberのケースだ。UberはもともとElasticsearchを使用していたが、約4年前にデータストレージをClickHouseに移行。これにより、高速なデータ取り込みとコスト削減が実現した。Elasticsearchはインデックス作成により書き込みが遅くなるが、ClickHouseはプライマリーキーを活用し、処理速度を向上させている。さらに、インデックスオプティマイザーが過去のデータを分析し、必要なカラムにセカンダリインデックスを自動追加することで、さらなるパフォーマンス向上を実現している。
2つ目のケースはDatadogからの移行だ。ClickHouse社では、マネージドサービスの開発時にオブザーバビリティツールを用意する時間がなく、手軽に導入できるDatadogを採用。しかし、コストの関係で1〜2週間分のデータしか保持できず、長期間のデータ分析が難しいという課題が浮上した。社内調査で半年分のデータを保持するニーズがあると判明したものの、Datadogでは月額40億円以上のコストがかかることが判明。そこで、自社でClickHouseを活用するプロジェクトが始動した。
開発には毎月1.5人のリソースを投入し、約1年でマイグレーションを完了。OpenTelemetryを活用し、各ポストからデータを収集、ゲートウェイ経由でClickHouseに格納し、可視化にはGrafanaを採用した。扱うデータ量は19ペタバイトながら圧縮処理により1.13ペタバイトまで削減し、圧縮率17%を実現。コストを試算するとDatadogと比べ200倍安価になった。
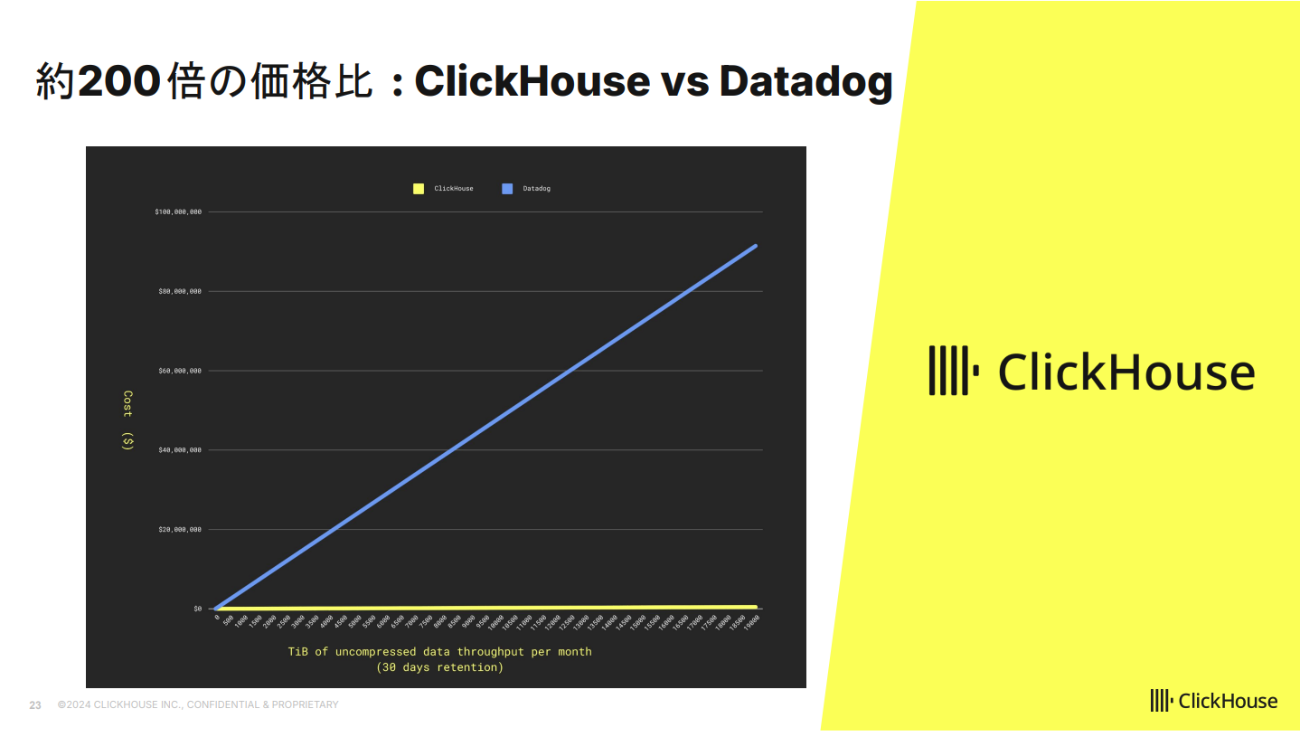
松本氏は「1テラバイト程度ではコスト効果はあまり出ないが、5テラバイト以上ほどデータが溜まっているなら、ClickHouseにマイグレーションするというのは非常に効果的な選択肢の一つ」と話した。
柔軟なスキーマ対応と圧倒的な処理性能
続いて松本氏は、ClickHouseの柔軟なスキーマ対応について説明した。マイクロアーキテクチャの普及により、マイクロサービスごとにログのフォーマットが異なり、新機能の追加やツールの変更で形式が変わることも多い。こうした課題に対応するため、多くのシステムでJSONが標準的に採用されており、ClickHouseも最近JSONタイプを正式にサポートした。
ClickHouseは、カラム内のデータ構造を自動解析し、適切なスキーマを生成する。異なる型のデータが混在しても、自動的に最適なカラムに振り分けるため、運用者がスキーマ調整を意識する必要がない。また、カラム単位でデータを管理することで、高圧縮かつ高速なデータ処理を実現している。
松本氏は、2024年に話題となった「10億ドキュメントチャレンジ」にClickHouseでも参加したことを話した。このチャレンジは、データベースやプログラミング言語の性能を測るため、10億件のドキュメントを解析し、どれだけ効率的に処理できるかを競うものだ。松本氏は、分散型SNS「Bluesky」の投稿者情報や「いいね」履歴をClickHouseに格納し、他のデータベースと比較するプロジェクトを実施した。
その結果、元データの482GBをClickHouseでは99GBまで縮小。他のデータベースと比較すると、MongoDBは158GB、Elasticsearchは360GB、DuckDBは472GB、PostgreSQLは622GBと、ClickHouseの圧縮効率が際立った。

さらに、パフォーマンス検証では「いいね」の回数を集計し、多い順に並べるクエリを実行。ClickHouseは404msで処理を完了し、MongoDBの16分、Elasticsearchの5秒、DuckDBやPostgreSQLの1時間と比較して、圧倒的な高速性を証明した。その他のパフォーマンスでもClickHouseが他を上回った。

最後に松本氏は、ClickHouseのマネージドサービスが無料で試用できるとし「日本ではAWSを利用してClickHouseの検証が可能。30日間、300ドル分まで無料で利用でき、多くのデータを扱うことができる。数テラバイト規模のデータ解析も可能なため、ぜひアカウントを作成し、実際にデータを取り込んで解析を試してみてほしい」と呼びかけた。

