



































以前の記事
はじめに
本稿ではAzure上に構築されたアプリケーションに、帳票生成機能を提供することを想定します。このアプリケーションはWebアプリケーションでもいいですし、Windowsアプリケーションとして実装された業務アプリケーションでもいいでしょう。
ただ共通する想定として「ビジネスロジックはAzure上のWeb APIとして実装される」こととします。そういった環境でDioDocsを利用し、どのように帳票生成サービスを構築するか? 本稿では底を掘り下げて検討し、実装例を紹介したいと思います。
本稿で作成した帳票生成処理は、再利用可能な形で実装しNuGet上に公開しています。DioDocs自体もNuGetに公開されているので、気軽に試すことができます。ぜひご自身で利用してみてください。
なお本稿は、DioDocsもAzure Functionsも全く利用したことがない方向けに記載しています。
さあ、それではあらためてDioDocsの世界へ足を踏み入れてみましょう!
本稿の構成
本稿は次の4項目で構成されています。
- 全体アーキテクチャの考察
- Azure Functions上での実現検証
- 帳票生成ライブラリの実現検証
- 帳票生成サービスの実装
まずは帳票生成サービスをAzure上でどのように実装すべきか(そもそも「Azure Functionsを利用すべきか?」も含め)検討します。その後、想定通りAzure Functions上で実装可能か検証し、帳票生成部分の実装を検証します。
それらの検証がすべて終わったのち、具体的な実装を紹介します。
環境
- DioDocs for Excel 2.2.1+
- Visual Studio 2019 16.2.3
- Azure Functions 2.0
- .NET Core 2.2
- Microsoft.Azure.WebJobs.Extensions.Storage 3.0.7
全体アーキテクチャの考察
それではアーキテクチャの検討から始めましょう。まず以下の前提があるものとします。
- アプリケーションのビジネスロジックはAzure上でWeb APIとして構築する
- 帳票生成も同様にAzure上で実施する
- 生成された帳票はエビデンスの意味も含め一定期間Azure上に保管する
ありがちなケースではないでしょうか?
この場合、Web APIは実際にはAzure上のApp ServiceやAzure Functionsを基盤として、REST APIなどで実装されることでしょう。また生成された帳票をAzure上に保管する関係から、帳票生成もAzure上で実装されるはずです。
「帳票はPresentationの一部なのでは? 仮にそうであったとして、PresentationがWebやクライアントアプリケーションとしてクライアントで実行されるのであれば帳票生成もクライアントで実装すべきではないか?」
こうした議論はあるかと思います。
しかし今回は、エビデンスの意味も含めて帳票はAzure上で保管します。クライアントサイドで実装すると、最悪ユーザーのみが所持してサーバー側には保管されないといったことが起こる可能性があります。サーバー側にエビデンスとして必ず保管するのであれば、帳票の生成はサーバーサイドで実施し、サーバーで保管までされた場合のみユーザーに提供すべきでしょう。
帳票の生成は、一般的なWeb APIと比較すると相対的に重く、リソースもそれなりに必要とします。また帳票生成量には波があることも多いでしょう。業務アプリケーションであれば1日の中でピークがあるでしょうし、公開サービスであっても例えば月末は利用量が多いといったことが想定されるでしょう。帳票の種別によっても利用量には偏りがあります。
以上を考慮して全体の構造を検討すると、下図が考えられるのではないでしょうか?
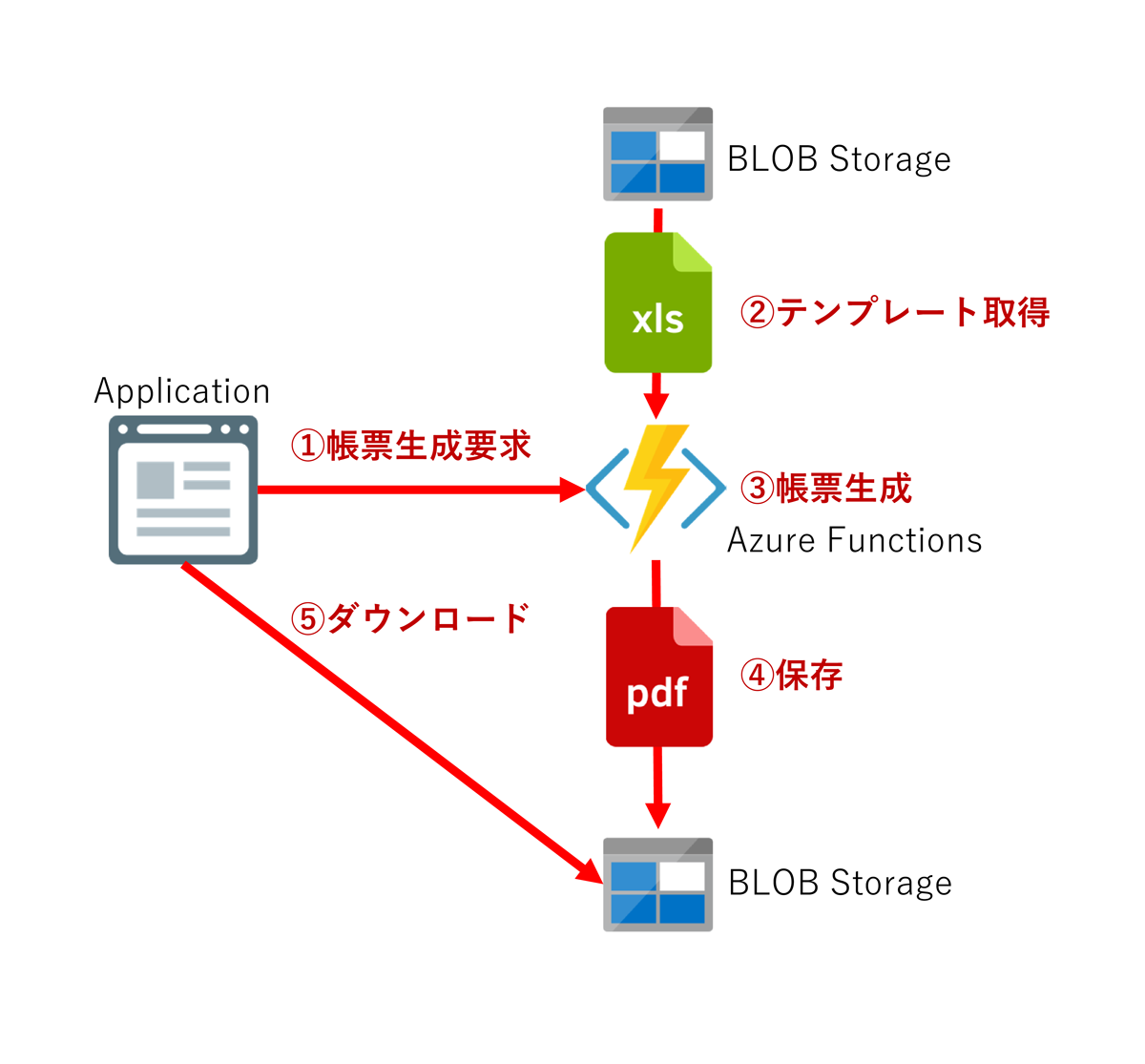
まず帳票生成サービスはAzure Functionsで作成します。
帳票生成はピークに偏りがありますし、帳票別に利用頻度も異なります。またビジネスロジックに変化がなくても帳票のレイアウトは変化することは、ままあります。
そのため、スケールイン・スケールアウトが容易で、アプリケーションと切り離して改修・配備可能であるマイクロサービスは最適な選択肢のひとつではないでしょうか?
帳票の生成にはDioDocsを利用します。DioDocsは次の特徴を持っています。
- ExcelからPDF生成をサポートしている
- 実行環境にMicrosoft Officeのインストールは必要ない
- ライブラリは.NET Standardとして提供される
帳票の生成というのは一般的に特殊な知識が求められます。帳票生成ライブラリの製品ごとに一定レベルの知識が求められ、また必ずしも理解しやすいとも限りません。
それに対してDioDocsはExcelと.NETの基本的な知識があれば利用することが可能です。レイアウトはExcelでデザイン可能ですし、ページングやヘッダーフッター、値のフォーマットといったあたりまでExcelで指定が可能です。
これは学習コストを考慮した場合、驚異的な生産性を発揮するでしょう。
ただしエンタープライズ環境における一括大量印刷系には向きません。その場合には、それに合った製品を選ぶべきで本稿の対象の範囲外となります。
逆に「少量多品種である」「レイアウトの変更が頻繁にある」「特定の帳票製品に習熟したエンジニアを継続的に確保することが困難である」などの要件がある場合、DioDocsは恐ろしいまでの効果を発揮するでしょう。
さてDioDocsを利用する場合、テンプレートとなるExcel(もしくはPDF)が必要です。テンプレートの取得方法は、大きく分けて次の3つが考えられます。
- Azure Functionsのアセンブリにリソースとして埋め込む
- Azure BLOBサービスに保管して取得する
- 帳票生成の際にデータとセットでPOSTする
3.の場合、Azure内外との通信量が増えてしまいますし、通信速度にも制限を受けます。基本的には1.もしくは2.となるでしょう。
- 今回は帳票生成のロジックに変更がなくても、テンプレートだけ変更することがありえる
- 非エンジニアが帳票のレイアウトのみを変更することがありえる
こうした想定のもと、2.の方式を選択することとしました。特に後者にとっては大きなメリットです。これはExcelからPDF生成が可能なDioDocsならではの強みです。
具体的な保管・取得先としてAzure BLOB Storageを利用します。
帳票生成時に動的に変動するデータはサービスの利用者(といってもソフトウェアですが)からJSON形式でPOSTしてもらい、帳票のテンプレートはBLOBサービスから取得します。それらをもとにExcelに値を設定したのちにPDFを生成し、いったん生成されたPDFはBLOBサービスに保管します。利用者には保管したアドレスを返し、別途BLOBサービスから取得してもらうことを想定します。
Azure Functions上での実現検証
では実現性の検証に入りましょう。ここでは次の順で検証していきます。
- Hello, Azure Functions!
- BLOBサービスからExcelテンプレートの読み込み
- BLOBサービスへの書き出し
- POSTデータの利用
- Azure Functionsのプラン選択
Hello, Azure Functions!
さて、ここから先を実施するには事前にVisual Studio上でAzure開発のサポートが導入されている必要があります。インストーラーから[変更]を選択して「Azureの開発」がインストールされていることを確認してください。
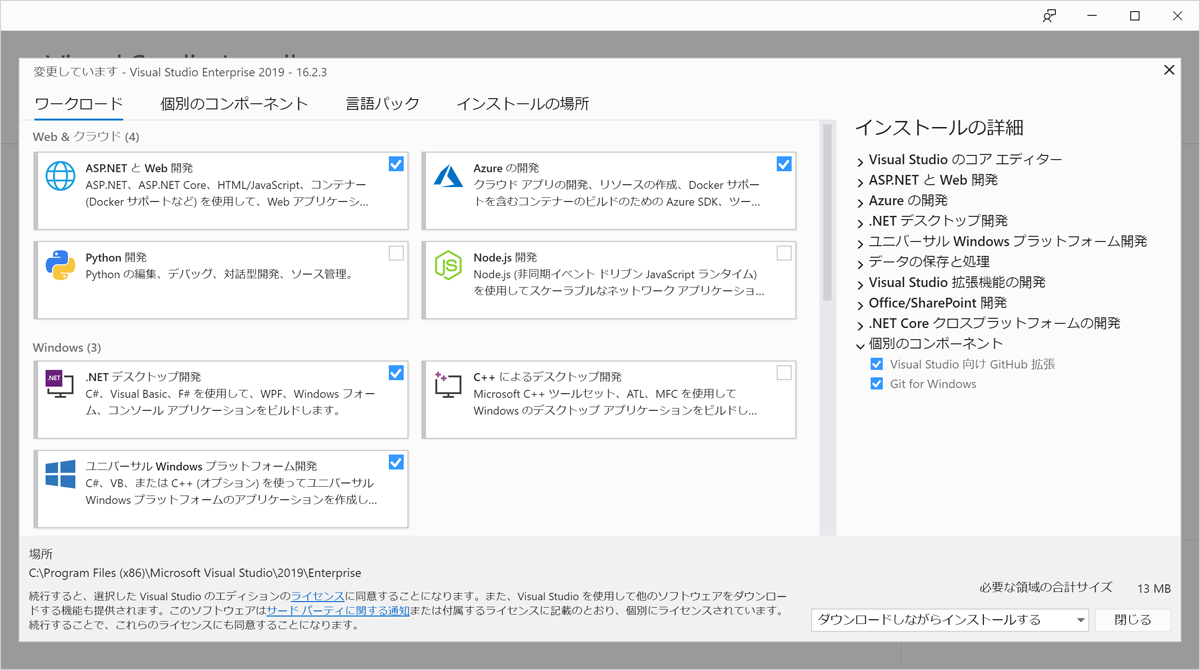
正しくインストールされていれば、Visual Studioから新しいプロジェクトを作成する際、下図のようにAzure Functionsのプロジェクトテンプレートが選択できるはずです。ここから新しいプロジェクトを作成しましょう。
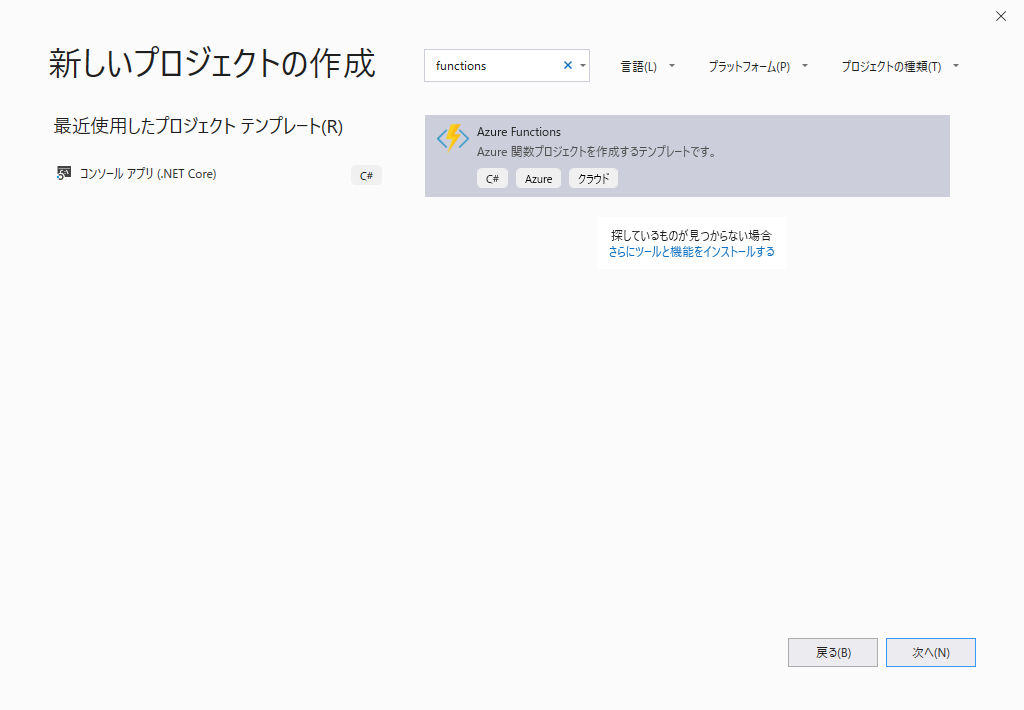
ここでは「InvoiceFunction」という名前のプロジェクトを新たに作成します。
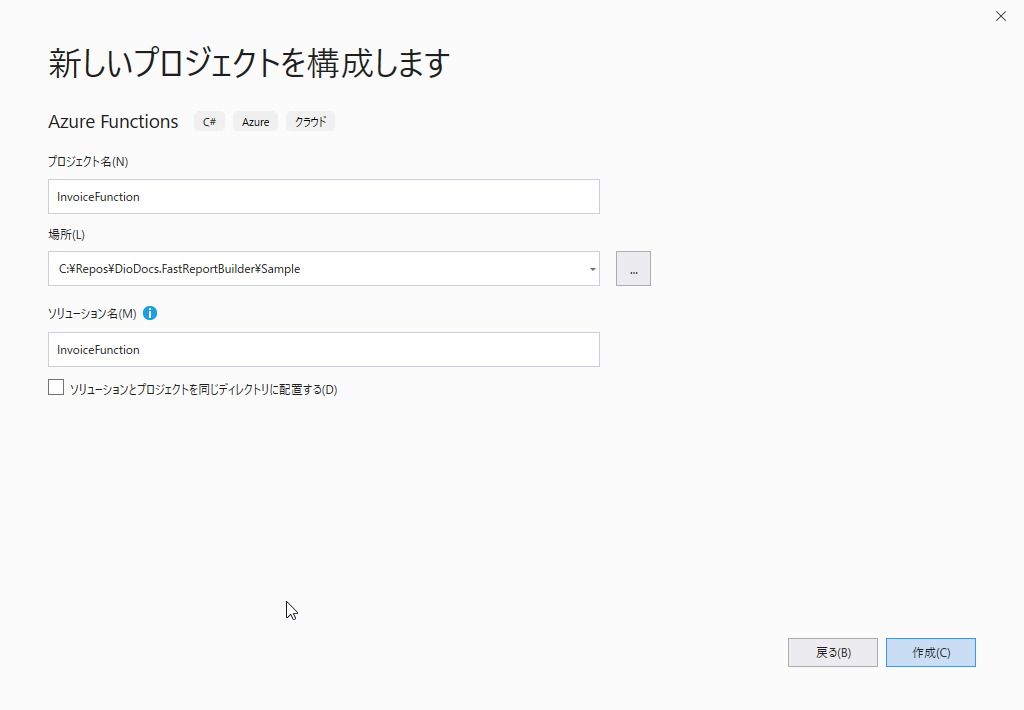
するとトリガーの選択が求められます。何を「トリガー」にFunctionを実行するか決定します。ここではHTTPのリクエストを想定しているので「Http trigger」を選択し[作成]を押下しましょう。
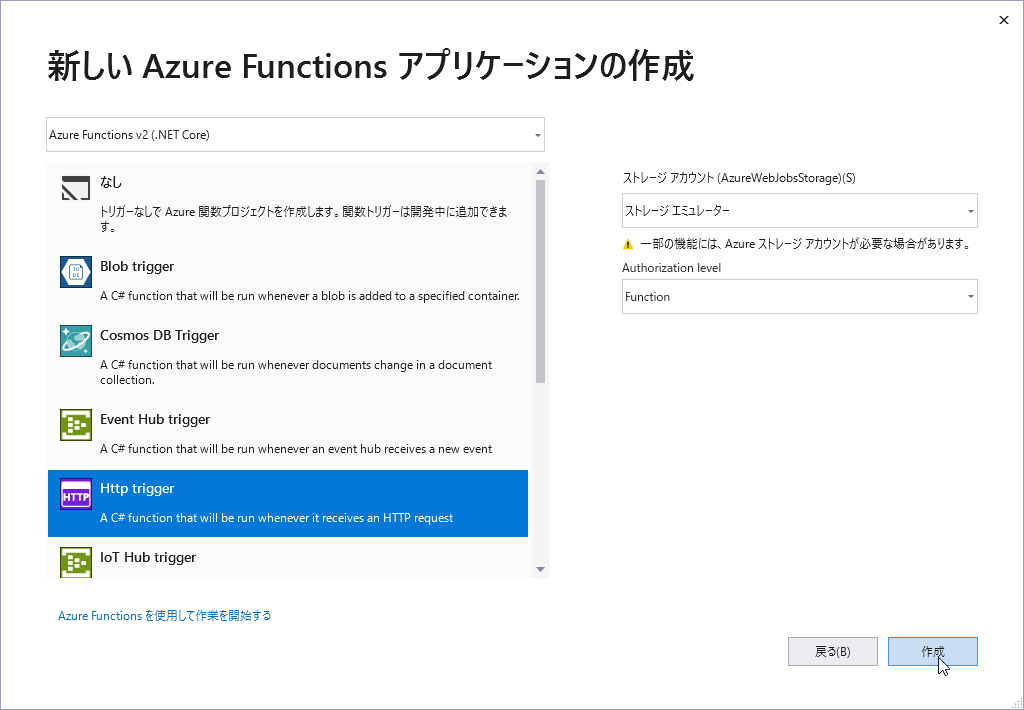
プロジェクトが作成されたら早速ローカルで実行してみましょう。実行してしばらくするとコンソールで次のように表示されるはずです。
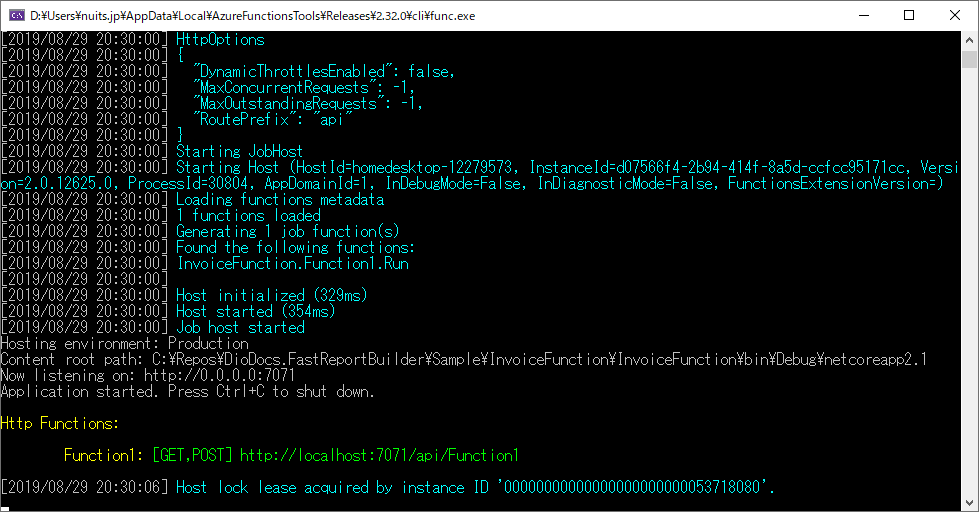
Function1という関数が表示されているのが見て取れます。そのアドレスをブラウザに入力してみましょう。
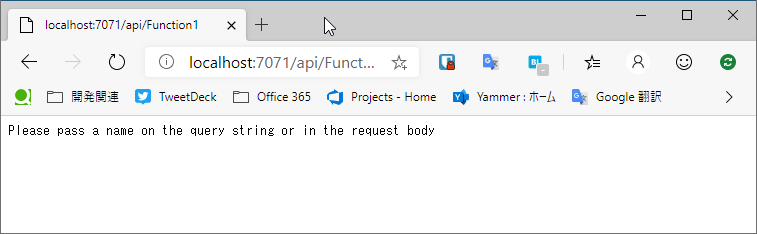
Please pass a name on the query string or in the request body
と表示されています。どういうことでしょうか? Functions1.csのコードを見てみましょう。
[FunctionName("Function1")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
return name != null
? (ActionResult)new OkObjectResult($"Hello, {name}")
: new BadRequestObjectResult("Please pass a name on the query string or in the request body");
}
デフォルトの実装ではクエリ文字列かPOSTのBodyにnameというパラメーターがあればそれを表示し、なければエラーにしているようですね。
という訳で先ほどのURLに?name=Worldを付与して実行してみましょう。
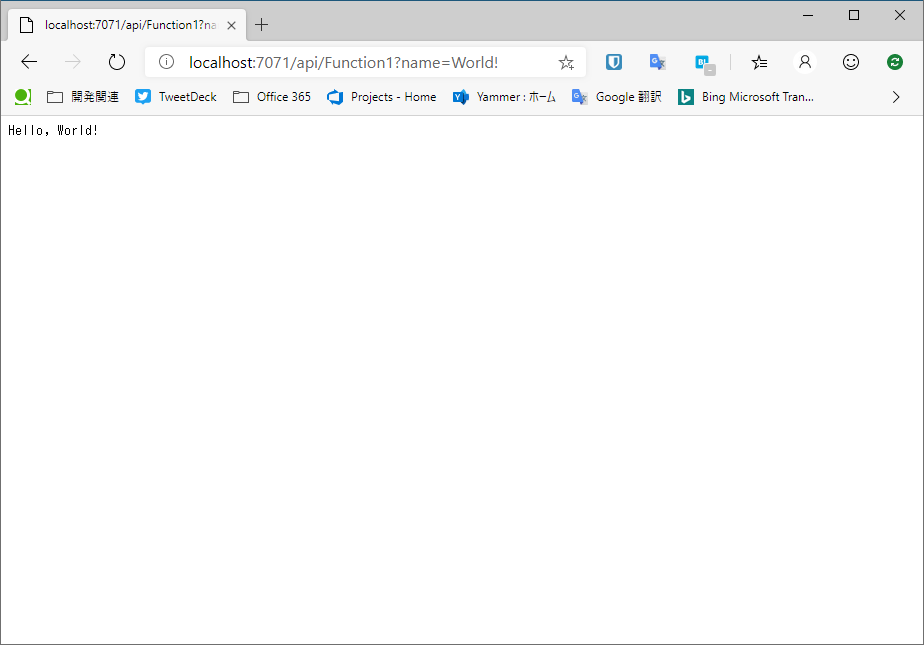
無事実行されたようです。ではこれを実際にAzure上で実行してみましょう。「InvoiceFunction」プロジェクトを右クリックし[発行]を押下しましょう。
![[発行]を押下](http://cz-cdn.shoeisha.jp/static/images/article/11704/11704_008.png)
まずAzure Functionsを実行するプランを選択します。ここでは「Azure App Serviceプラン」を新規に作成しています。理由は後ほど説明します。
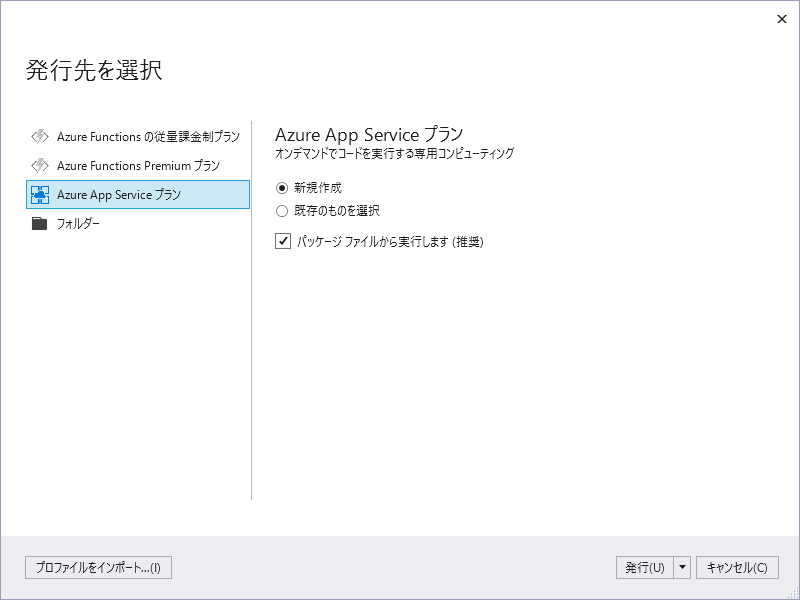
名称に「InvoiceFunction」を指定し、リソースグループ・ホスティングプラン・Azure Storage共にすべて新規で作成します。後々リソースグループごとすべて削除することでうっかり削除漏れが……といったことを防ぐため、ここではすべて新しく作成しています。
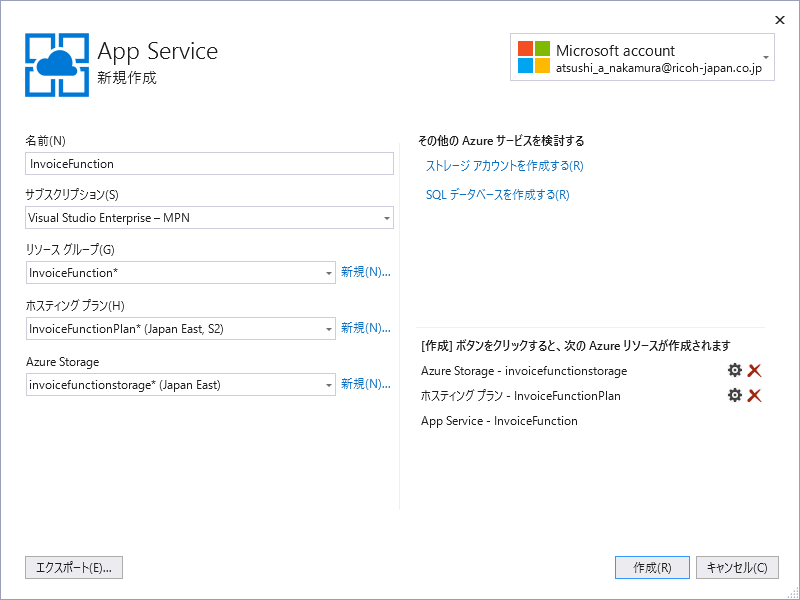
指定が済んだら[作成]を押し、Azure上にリソースを作成しましょう。やや時間がかかります。
作成が完了すると発行画面が表示されるので、そのまま[発行]します。
発行が済んだら、実際にAzureのポータルから正しく配置されているか確認しましょう。ポータルから「リソースグループ」を選び、先ほど作成したリソースグループを選択します。
すると「InvoiceFunction」という雷マークをしたAzure Functionのリソースが表示されるでしょう。
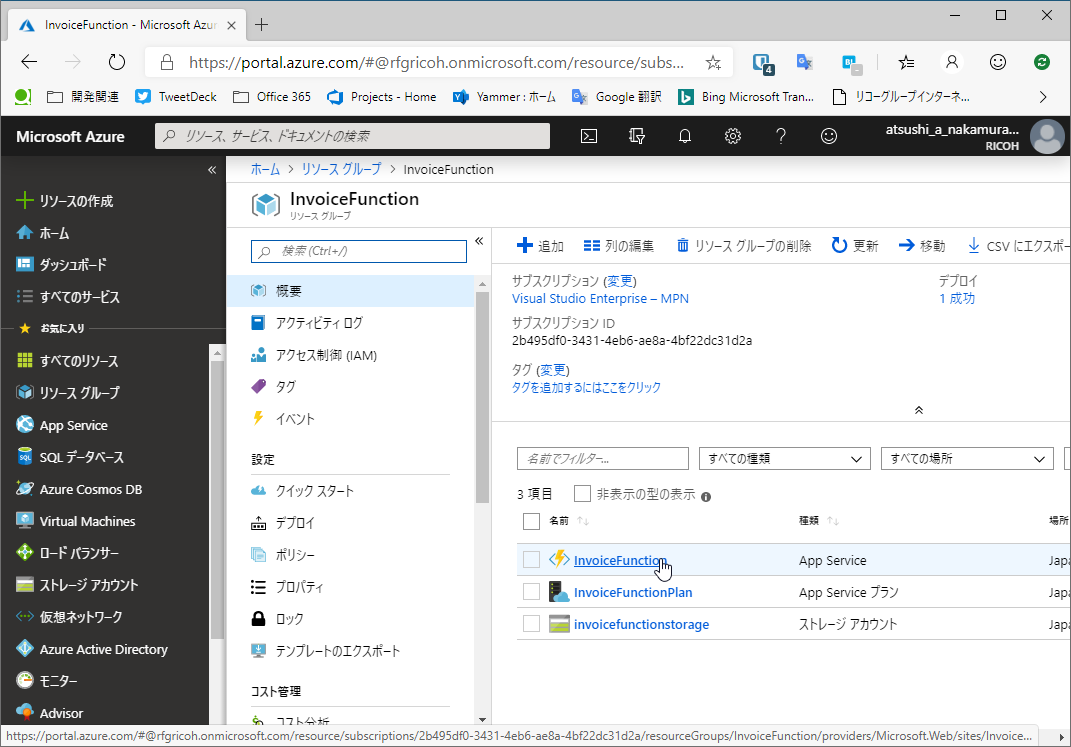
無事配備されているようですね。ここから下図の通り「Function1」を開いてください。「関数のURLを取得」という項目が開いて少し経つと表示されます。最初は表示されていないと思いますが慌てる必要はありません。
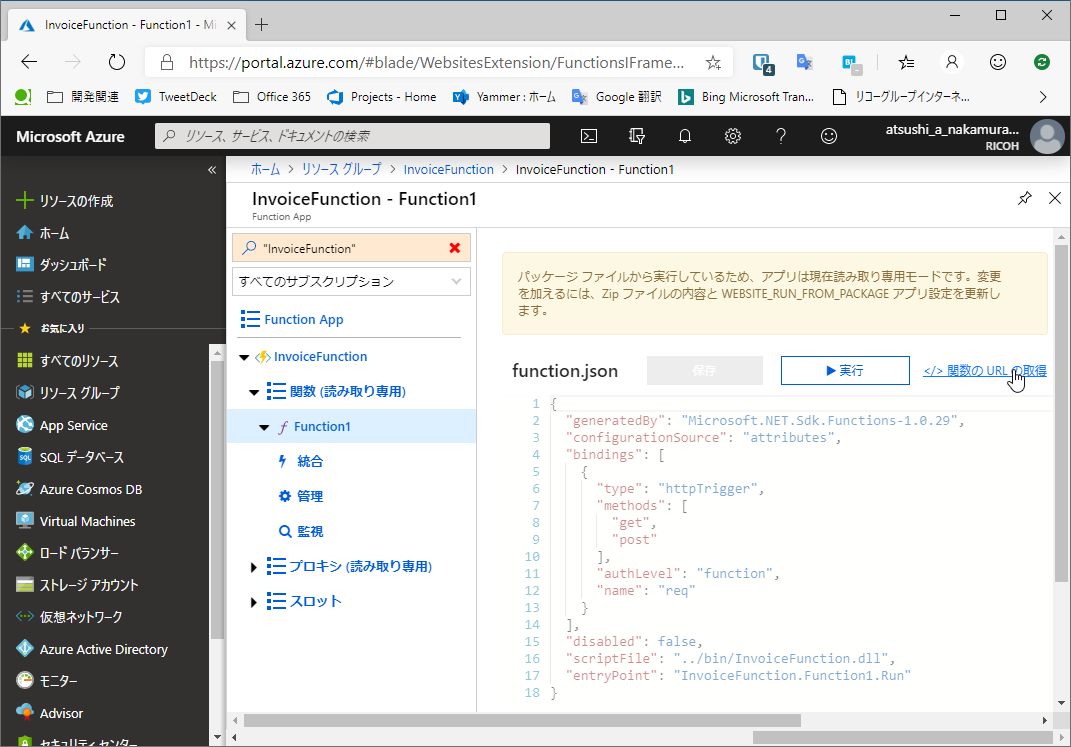
ここからURLをコピーし、末尾に&name=Workd!を付与してWebブラウザで開いてみてください。これで無事Azure Functionsデビューできたはずです。
BLOBサービスからExcelテンプレートの読み込み
では続いてBLOBサービスにExcelをアップロードして関数実行時に読み込んでみましょう。
まずはExcelのテンプレートを保管する「コンテナ」を作成します。
Azure BLOB Storageには「ストレージアカウント」と「コンテナ」という概念があります。Azure上には複数のストレージアカウントを作成することが可能で、そのストレージ内に複数の用途のコンテナを作成することができます。コンテナの中にはフォルダやファイルを作成できるので、コンテナが論理的な1つのストレージと考えていいかもしれません。
実はAzure Functionsを配備する際に、Azure Functionsの実行ファイルなどを保管するため、1つのストレージアカウントと2つのコンテナが作成されています。
今回はそのストレージアカウントに新しく次の2つのコンテナを追加して利用します。
- 帳票テンプレートとなるExcelを保管する「templates」コンテナ
- 作成された帳票PDFを保管する「reports」コンテナ
ではポータルを開き、InvoiceFunctionリソースグループ内のストレージアカウントを開いてください。その中から「BLOB」を選択します。
すでにコンテナが2つあるのが見て取れますね。
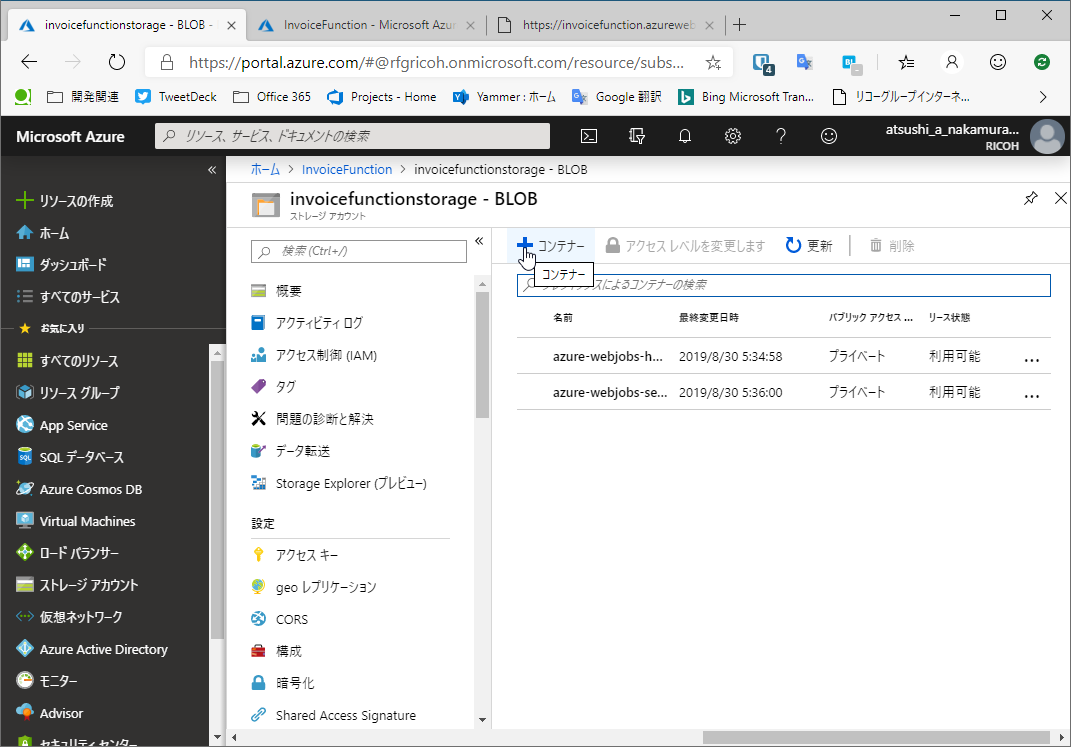
ここで[+コンテナー]を押下して次の2つのコンテナを追加してください。
- 「templates」
- 「reports」
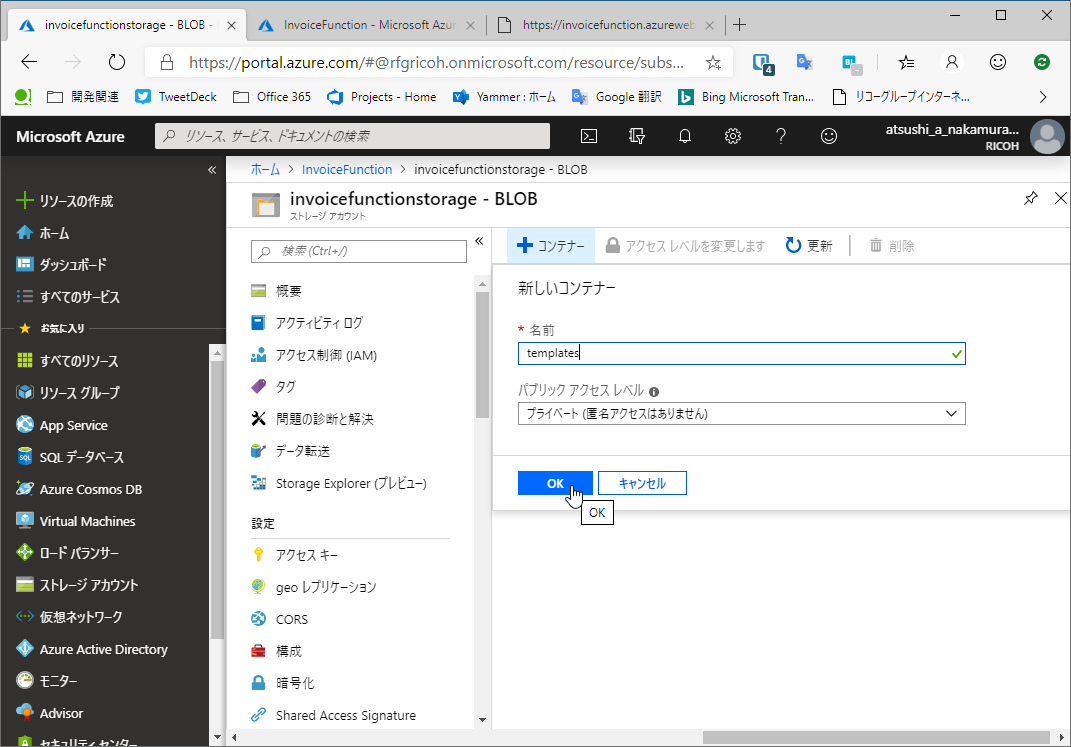
作成したらtemplatesコンテナを開いて適当なファイルをアップロードしてください。ここでは「Invoice.xlsx」というファイルをアップロードしました。こちらをダウンロードして利用します。
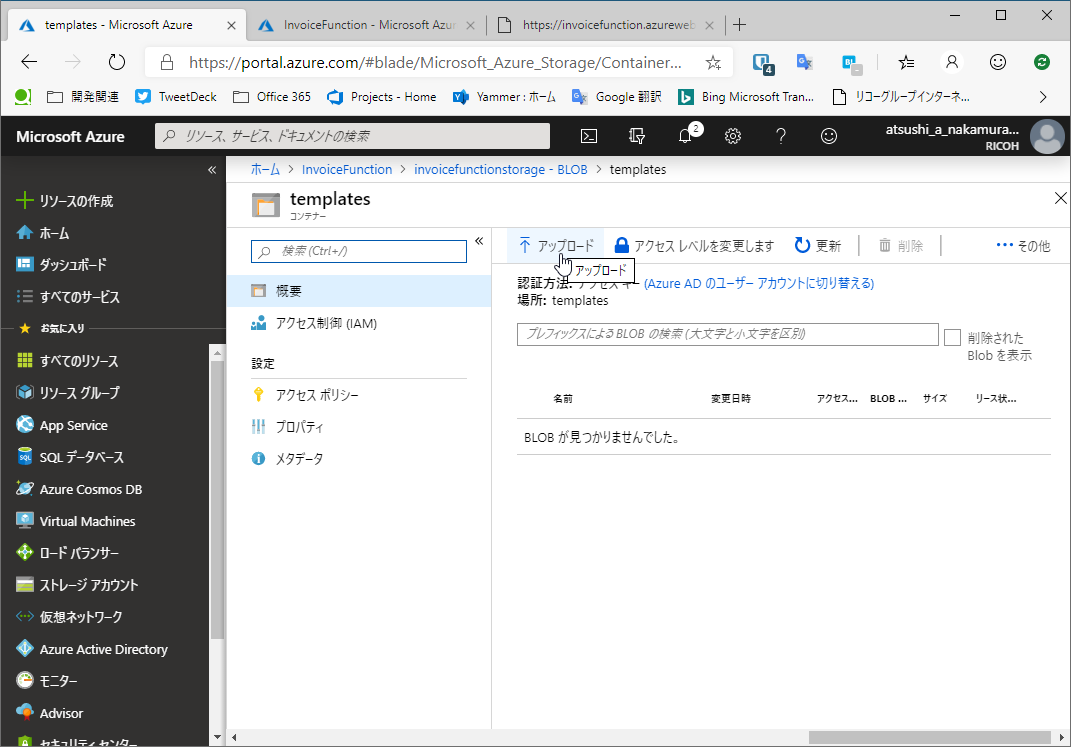
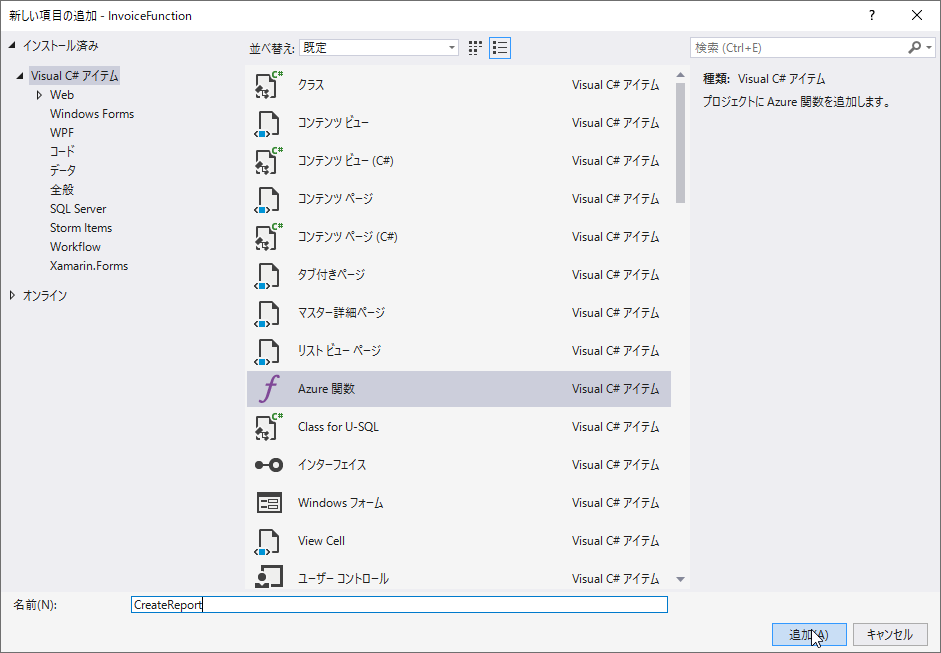
それではVisual Studioを開き、新しい関数を追加しましょう。プロジェクトを右クリックし[追加]から[新しいAzure 関数]を選択します。
![[新しいAzure 関数]を選択](http://cz-cdn.shoeisha.jp/static/images/article/11704/11704_019.png)
「CreateReport」という名前を指定し、Http triggerを指定して作成してください。
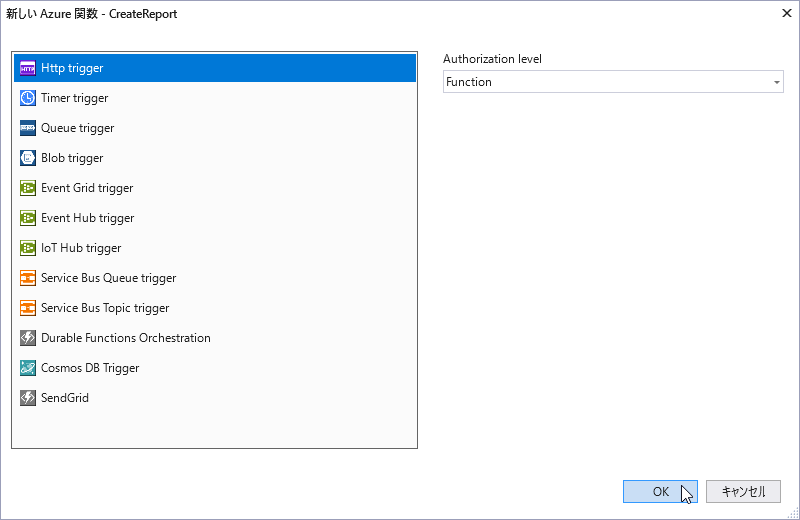
この関数に実装していきます。
Azure FunctionsではBLOB Storageにアクセスするにあたり、関数内から明示的に取得しに行く方法と、「バインド」という機能を利用して関数の引数に受け渡してもらう方法の2つがあります。詳細は以下をご覧ください。
利用するBLOBが実装時に自明なのであればバインドを利用したほうがいいでしょう。
新しく作成したCreateReport.csファイルを開き、次の通り実装を修正します。
[FunctionName("CreateReport")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
[Blob("templates/Report.xlsx", FileAccess.Read)]Stream input,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
return new OkObjectResult($"templates/Report.xlsx Size:{input.Length}");
}
次の引数が追加されています。
[Blob("templates/Report.xlsx", FileAccess.Read)]Stream input
引数にBlobAttributeを指定することで、宣言されたBLOBを操作するためのStreamを受け渡すことができます。コンテナの名称とファイル名とアクセスのモード(ここでは読み取り専用)を指定しているのが見て取れるでしょう。
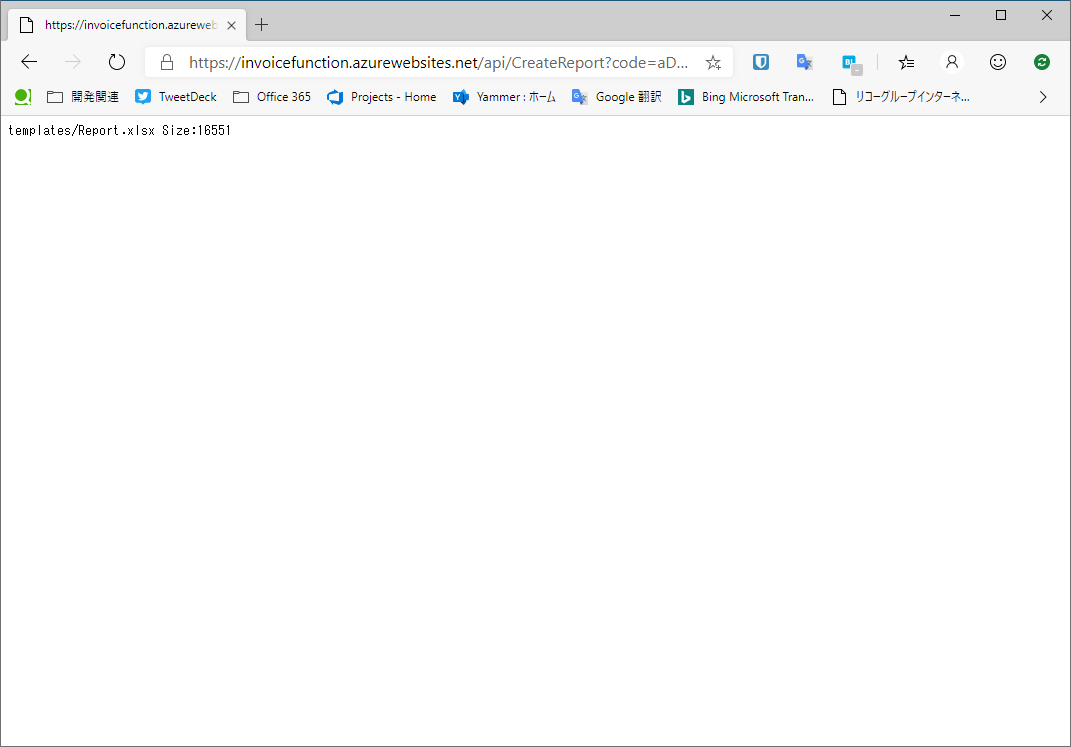
ここではStreamからファイルのサイズを取得しています。実行してみましょう。実行時は先ほどのFunction1と同じようにポータルからURLを取得します。下図のようにファイルサイズが表示されれば成功です。
BLOBサービスへの書き出し
それでは今度は書き出しを実装してみましょう。
書き出しも、書き出すBLOBが実行前に決定できるのであれば、書き出し可能なStreamをバインドすることができます。
ただ今回のケースではCreateReport関数が実行される都度ファイルを作成します。そのため実行時にファイルを決定することとします。その方法を紹介しましょう。以下をご覧ください。
[FunctionName("CreateReport")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
[Blob("templates/Invoice.xlsx", FileAccess.Read)]Stream input,
[Blob("reports", FileAccess.Write)] CloudBlobContainer outputContainer,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
await outputContainer.CreateIfNotExistsAsync();
var fileName = $"{Guid.NewGuid()}.txt";
var cloudBlockBlob = outputContainer.GetBlockBlobReference(fileName);
using (var writer = new StreamWriter(await cloudBlockBlob.OpenWriteAsync()))
{
writer.Write("Hello, Azure Functions!");
}
return new OkObjectResult($"fileName:{fileName}");
}
次の新たな引数で、関数を追加しました。
[Blob("reports", FileAccess.Write)] CloudBlobContainer outputContainer,
ポータルからreportsというコンテナを追加しました。ここではコンテナ内部のBLOBではなくBLOBコンテナそのものを引数に受け渡してもらいます。そして新しいBLOBを作成して追加しています。BLOBを追加する際、名称としてGUIDを生成して利用しています。
GUIDを作成後、次の通りBLOBを作成しそこに文字列を書き出しています。
var fileName = $"{Guid.NewGuid()}.txt";
var cloudBlockBlob = outputContainer.GetBlockBlobReference(fileName);
using (var writer = new StreamWriter(await cloudBlockBlob.OpenWriteAsync()))
{
writer.Write("Hello, Azure Functions!");
}
そしてレスポンスとして新しく作成されたファイルの名称を返却しています。
return new OkObjectResult($"fileName:{fileName}");
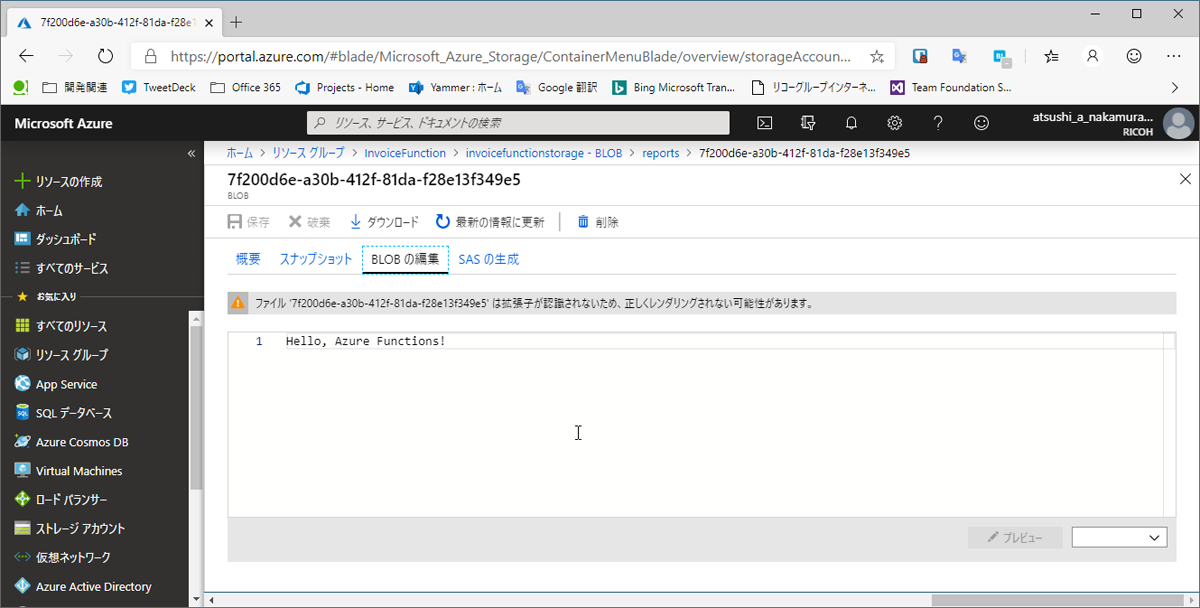
実行するとGUIDが表示されます。そのGUIDのファイルをreportsコンテナで探して開いてみましょう。「Hello, Azure Functions!」と表示されているのが確認できます。
これで書き出しができるようになりました。
POSTデータの利用
Functions側の実装課題はあとひとつ、帳票を作成するためのデータをどのように渡すかです。
Functionsは「トリガー」と呼ばれる仕組みで実行されます。HTTPリクエストやBLOBファイルの作成、Queueへのコマンドの追加など多種多様なトリガーが用意されています。具体的には以下をご覧ください。
今回の想定シナリオの場合、アプリケーションからの要求を受けて開始するためHTTPトリガーを利用します。HTTPトリガーで実行するのですから、帳票データはHTTPのBodyにJSONをのせて渡すのが自然でしょう。
POSTデータは関数の引数で渡されているHttpRequestオブジェクトのBodyプロパティからStreamを取得できます。Bodyの値をそのまま先ほどの出力先BLOBにコピーしてみましょう。
var fileName = $"{Guid.NewGuid()}.txt";
var cloudBlockBlob = outputContainer.GetBlockBlobReference(fileName);
using (var output = await cloudBlockBlob.OpenWriteAsync())
{
req.Body.CopyTo(output);
}
では実行してみましょう。今度はJSONをPOSTする必要があるので、新しくコンソールアプリケーションを作成し、次のコードを記述して実行しましょう。endpointには作成した関数の実行URLを記載してください。
var endpoint = "YOUR_URL";
var jsonContent =
new StringContent(
"{\"Message\":\"Hello, Azure Functions with JSON!\"}",
Encoding.UTF8,
"application/json");
var httpClient = new HttpClient();
var response = await httpClient.PostAsync(endpoint,jsonContent);
Console.WriteLine(await response.Content.ReadAsStringAsync());
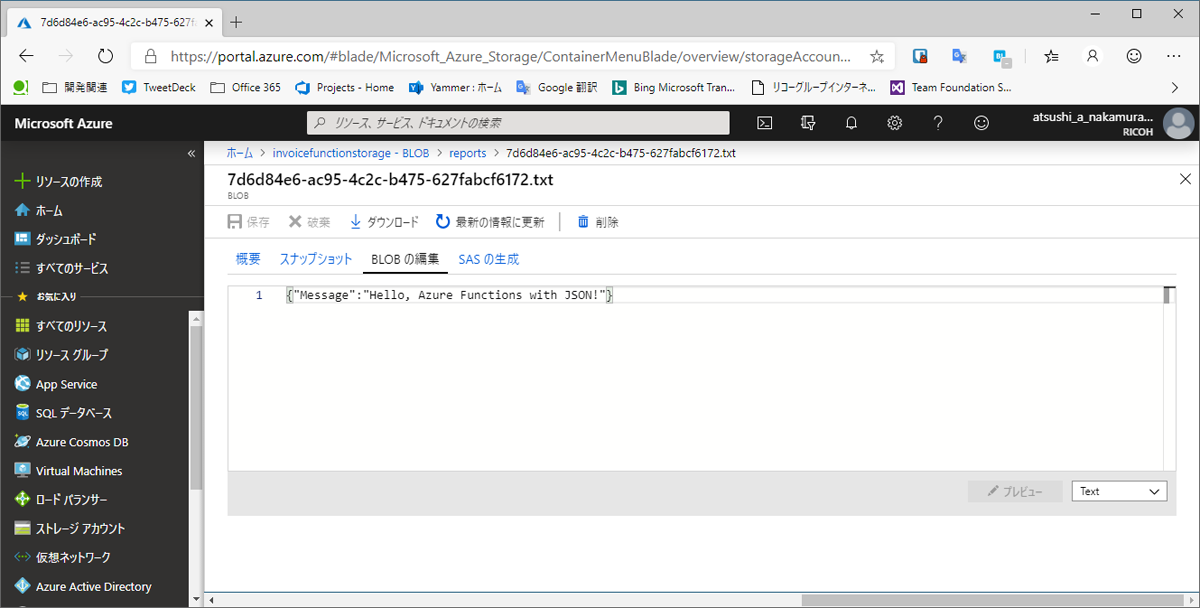
実行後、ポータルからBLOBを確認すると、ちゃんとJSONが書き出されているのが見て取れるでしょう。
これで関数実装のためのすべての課題がクリアされました。
Azure Functionsのプラン選択
さて、関数を実装するための課題は解決されましたが、Azure Functions側の大切な課題がもうひとつ残っています。「どのプランで実行するか」です。現在のAzure Functionsは大きく分けて次の3種類の課金プランがあります。
- 従量課金プラン
- App Serviceプラン
- Premiumプラン
基本的に上から下にいくほど実行性能が高く、実行コストも高くなります。
そこで実際にDioDocsでExcelからPDFを生成し、レスポンスタイムを計測してみました。計測に利用したプログラムは次のような関数です。
[FunctionName("CreatePdfForStreamNull")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
[Blob("templates/Report.xlsx", FileAccess.Read)]Stream input,
ILogger log)
{
var workbook = new Workbook();
workbook.Open(input);
workbook.Save(Stream.Null, SaveFileFormat.Pdf);
return new OkObjectResult("OK");
}
Excelを開いてPDFをNullデバイスへ書き出しています。この関数をBenchmarksDotNetを利用して各プランで計測してみた結果が次の通りです。
| 計測方法 | Mean | Error | StdDev | Median | Rank |
|---|---|---|---|---|---|
| ローカルPC | 212.6 ms | 21.49 ms | 63.35 ms | 260.3 ms | 2 |
| 従量課金プラン | 1069.6 ms | 315.26 ms | 899.46 ms | 644.1 ms | 5 |
| S1(App Service) | 683.0 ms | 147.74 ms | 430.97 ms | 551.1 ms | 4 |
| S2(App Service) | 353.3 ms | 47.22 ms | 138.50 ms | 382.7 ms | 3 |
| S3(App Service) | 327.2 ms | 44.43 ms | 130.99 ms | 325.6 ms | 3 |
| EP1(Premium) | 325.3 ms | 61.07 ms | 180.07 ms | 341.3 ms | 3 |
| EP2(Premium) | 180.2 ms | 30.77 ms | 89.75 ms | 144.5 ms | 1 |
| EP3(Premium) | 173.2 ms | 19.98 ms | 58.90 ms | 176.0 ms | 1 |
一番上は参考値のローカルPCでの計測です。ローカルPCのスペックは以下の通りです。
- CPU:Core i7-7700T
- メモリ:16G
この実行結果を見る上でもっとも重要なのは、従量課金プランの実行性能です。
他のプランに比べて大幅にレスポンスタイムで劣ります。個別に実行時間を見るとかなり大きな波があります。従量課金プランの場合、継続して負荷をかけると、インスタンスがスケールアウトします。しかし個別のインスタンスについてはCPUは1コアでメモリーは1.5Gで固定です。また上記のベンチマークはシングルスレッドで逐次実行しており、スケールアウトでは性能は改善しません。
またS1プランを見てみると、これもあまりS2以上のプランと比較すると速度が出ていません。そしてS1プランのメモリーは1.75Gです。
個別のレスポンスタイムを見てみると、従量課金プランの場合、300ms~600msが連続する中に1000ms~3000msの大きな値が20%~30%程度の割合で含まれています。
おそらくDioDocsを実行するのに従量課金プランやS1プランでは性能が不足しているのでしょう。
そのため、ある程度の性能を見込む場合はS2以上のプランを選んだほうが良さそうです。具体的にどのプランにするかは、個々の帳票生成次第なので別途評価が必要となるでしょう。従量課金プラン以外の場合、利用していない時間帯も継続的に課金されることになるため、その場合はプランを負荷状況に応じて調整する必要もあるかもしれません。
帳票生成ライブラリの実現検証
それではDioDocsを使用し、帳票生成処理の実装を検討していきましょう。
DioDocsの特長を最大限生かすためには、やはりソースコードを変更せずにレイアウト変更が実現できるようにしたいところです。そのための実装例については以前の記事で紹介しました。
こちらで紹介した帳票生成ライブラリはGitHubとNuGetにも公開しています。
具体的には次のコードで簡単に帳票を生成することが可能です。
var reportBuilder =
new ReportBuilder<InvoiceDetail>(template)
// 単一項目のSetterを設定
.AddSetter("$SalesOrderId", cell => cell.Value = invoice.SalesOrderId)
.AddSetter("$OrderDate", cell => cell.Value = invoice.OrderDate)
.AddSetter("$CompanyName", cell => cell.Value = invoice.CompanyName)
.AddSetter("$Name", cell => cell.Value = invoice.Name)
.AddSetter("$Address", cell => cell.Value = invoice.Address)
.AddSetter("$PostalCode", cell => cell.Value = invoice.PostalCode)
// テーブルのセルに対するSetterを設定
.AddTableSetter("$ProductName", (cell, detail) => cell.Value = detail.ProductName)
.AddTableSetter("$UnitPrice", (cell, detail) => cell.Value = detail.UnitPrice)
.AddTableSetter("$OrderQuantity", (cell, detail) => cell.Value = detail.OrderQuantity);
reportBuilder.Build(invoice.InvoiceDetails, outputStream, SaveFileFormat.Pdf);
この方法自体は我ながら良くできていると思うのですが、これは帳票生成するデータが.NETのクラスとして実装されていて、すでにオブジェクトが存在する前提となっています。ビジネスロジックと帳票生成が同じ場所で実行されるオンプレミスのサーバー上やクライアントサーバー型のWindowsアプリケーションなどでは最適な方法です。
しかしAzure Functions上では必ずしも最適とは言えません。主な理由として次の2つが挙げられます。
- 帳票生成データはJSONで送信されてくるが、それをいったん.NETのオブジェクトへデシリアライズしなくてはならない。
- 帳票生成データの構造が変更されたとき、Azure Functions上で実行されているコードを修正する必要がある。
性能的にはそれほど大きな差がある訳ではありませんが、特に後者は運用を想定すると大きな違いです。これらの問題はビジネスロジックと帳票生成が分離されており、間をJSONで受け渡していることに起因します。
ではどうするべきでしょうか?「JSONのままデータを処理すればよい」となるでしょう。
その際に課題になるのは以下2点です。
- JSONの値をExcelのどのセルに設定するか
- 値を設定するときに型はどうやって決定するか
Excelの書式情報を生かすには日付はDateTime、数字はdoubleで(Excelの数字は内部的にすべて浮動小数点で扱われています)といったように、適切に扱うべきでしょう。そのためにマッピングと型をどこかに定義する必要があります。
最適な場所がありますよね?
そうです。テンプレートとなるExcelの別シートに記述すればいいでしょう。下図をご覧ください。
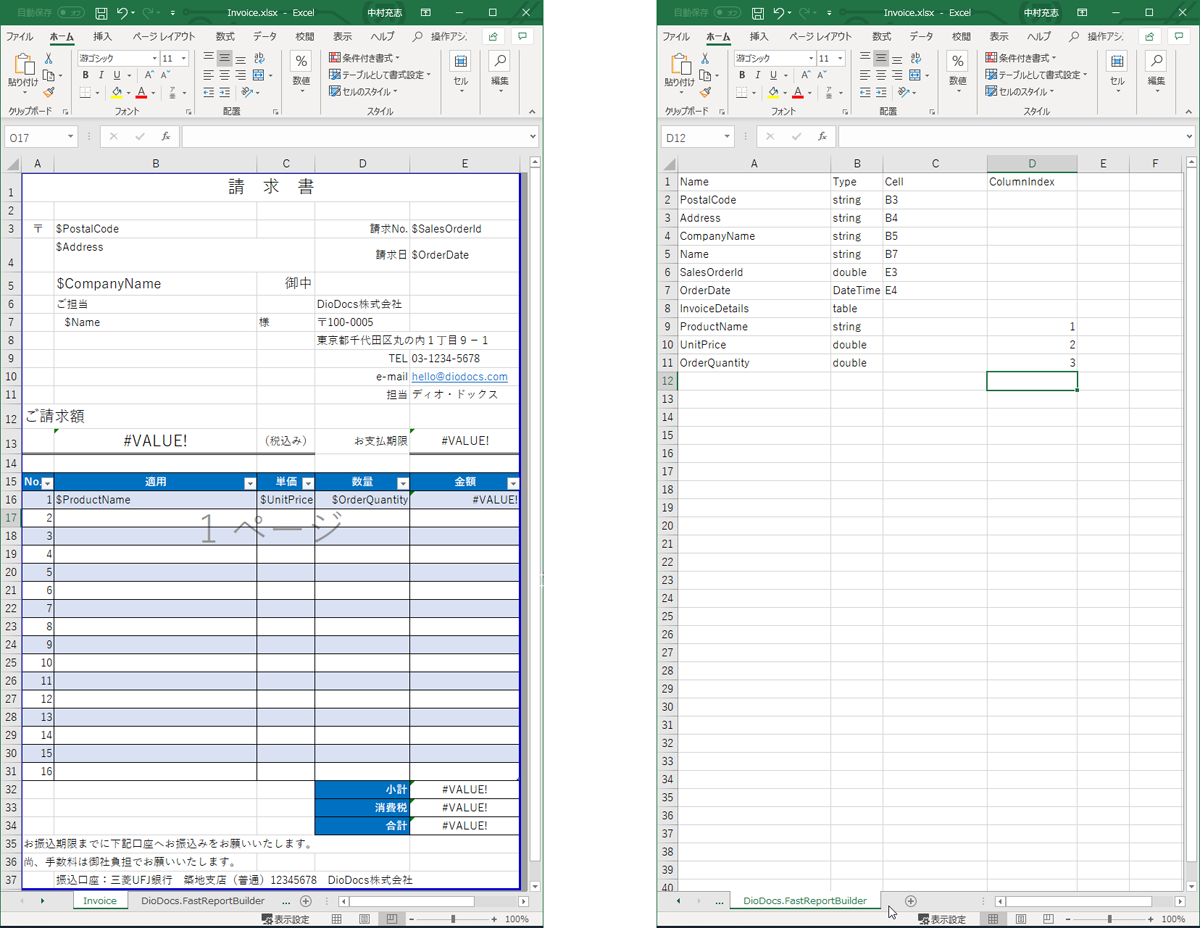
Excelには2つのシートを定義します。
1枚目のInvoiceシートは実際の帳票のレイアウトを定義したテンプレートです。今回は1枚の帳票に1つずつ存在する単独項目が任意の数存在し、それとは別に1つの表が存在するという一般的な構造の帳票を想定します。$PostalCodeといった、いかにもプレースホルダのような記述がありますが、今回はプレースホルダは使用せず、動的に変更する場所がどこにあるのか見やすくするために利用しています。
2枚目のDioDocs.FastReportBuilderシートがJSONとExcelの節をマッピングするための設定ファイルです。
JSONは次のような構造を想定しています。
{
"SalesOrderId": "71936",
"OrderDate": "2008-06-01T00:00:00",
"CompanyName": "Metropolitan Bicycle Supply",
"Name": "Krishna Sunkammurali",
"PostalCode": "W1N 9FA",
"InvoiceDetails": [
{
"OrderQuantity": "3",
"UnitPrice": "12",
"ProductName": "Chain"
},
{
"OrderQuantity": "4",
"UnitPrice": "63",
"ProductName": "Front Brakes"
},
...
Excelのシートには以下の列を定義します。
Name
JSONの項目名です。
Type
項目の型。stringやDateTime、doubleといった帳票的にプリミティブな型と、表を表すtable型が存在します。table型以降の行(8、9、10、11行目)が表の列を表すものとして扱います。
Cell
値を設定するセルです。固定位置の単一項目で利用します。
ColumnIndex
値を設定する列インデックス。表に対して複数行設定するテーブル項目の列を指定するために利用します。
実行効率を最大化するには、これらのメタデータもJSONなどで記述してBLOBに入れておくのがいいのでしょうが、テンプレートとメタデータが同じ場所で定義できることは運用上非常に大きなメリットです。実際の実行速度はそう変わりませんし、今回はこの方式で進めます。
さてこれらを利用して、JSONとExcelテンプレートからPDF帳票を生成することを考えましょう。
帳票中の決まったセルに設定する単一項目が複数と、表形式でExcel上でテーブルとして扱うテーブル項目という形式であれば、これらを利用することでマッピングとPDF生成のロジックは個別に記載する必要はなくなるはずです。
実際に次のクラス図のように設計実装しました。JSONの利用にはJson.NETを利用する前提です。
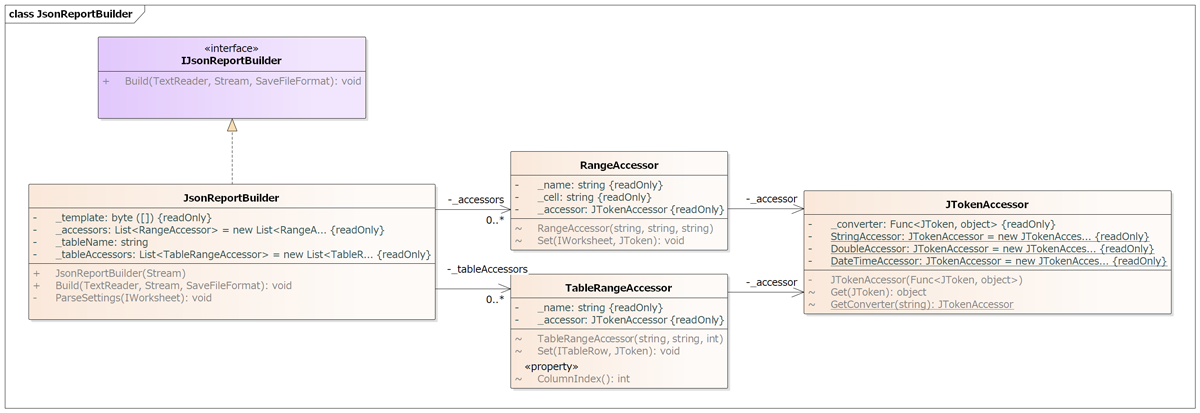
それぞれ次の役割を持ちます。
IJsonReportBuilder
JsonReportBuilderのインターフェース。帳票生成はテストの難しい部分です。このため帳票生成している箇所と利用している箇所は、分離してテストしたいケースが多いため、インターフェースと実装を分離します。
JsonReportBuilder
帳票生成の全体を制御するクラス。設定の読み込み、帳票データを設定値に基づきテンプレートに適用する処理、値を適用したPDFを生成する処理が含まれます。個別のセルにJSON文字列を型変換して設定する処理はRangeAccesorとTableRangeAccesorに移譲します。
RangeAccessor
単一項目へのアクセスを実装します。利用するJSONの属性名、値を設定するセルの名称を持ち、JTokenAccessorで変換された値をWorksheetへ設定します。
TableRangeAccessor
RangeAccesorのテーブル項目版です。
JTokenAccessor
JSONへアクセスし、文字列から値への変換を請け負います。
帳票生成の全体の制御構造はJsonReportBuilderに持ち、各セルへの値の設定はそれぞれRangeAccesorとTableRangeAccesorが請け負います。その際、JSON文字列をそれぞれのセルの型に変換するのはJTokenAccessorが請け負います。
具体的な実装を見ていきましょう。なお、コードの全貌は以下のリポジトリで公開しています。ぜひご覧ください。
まずはJsonReportBuilderから見ていきましょう。
public class JsonReportBuilder : IJsonReportBuilder
{
private readonly byte[] _template;
private bool _isInitialized;
private readonly List<RangeAccessor> _accessors = new List<RangeAccessor>();
private string _tableName;
private readonly List<TableRangeAccessor> _tableAccessors = new List<TableRangeAccessor>();
public JsonReportBuilder(Stream template)
{
_template = new byte[template.Length];
template.Read(_template, 0, _template.Length);
}
コンストラクタでExcelファイルを読み込んで_templateにバイト列で保持しています。実際に処理する際にはWorkbookに変換して利用しますが、Workbookオブジェクトを再利用した場合、帳票生成を複数回実行したときに前の帳票のデータが残ってしまうリスクがあります。そのため、コンストラクタでWorkbookオブジェクトを生成してキャッシュすることはせず、ベースとなるバイト列を毎回開く実装にします。
JsonReportBuilderにはJSON値を設定するRangeAccessorとTableRangeAccessor、表データを設定するExcelのテーブル名を所持しますが、コンストラクタでは設定せず、初回の帳票生成時に設定値を取得します。これはコンストラクタでWorkbookを開いて設定値を取得した場合、帳票生成時に再びWorkbookを開く必要ができてしまうためです。
実際に帳票生成するメソッドを見てみましょう。
public void Build(TextReader input, Stream output, SaveFileFormat saveFileFormat)
{
using (var memoryStream = new MemoryStream(_template))
using (var reader = new JsonTextReader(input))
{
IWorkbook workbook = new Workbook();
workbook.Open(memoryStream);
var settingWorksheet = workbook.Worksheets["DioDocs.FastReportBuilder"];
if (settingWorksheet == null) throw new InvalidOperationException("Setting Worksheet(DioDocs.FastReportBuilder) is not exist.");
if (!_isInitialized) ParseSettings(settingWorksheet);
settingWorksheet.Delete();
var worksheet = workbook.Worksheets[0];
var json = JToken.ReadFrom(reader);
foreach (var rangeAccessor in _accessors)
{
rangeAccessor.Set(worksheet, json);
}
if (_tableName != null)
SetTable(worksheet, json);
workbook.Save(output, (GrapeCity.Documents.Excel.SaveFileFormat)saveFileFormat);
}
}
大きく次のような流れになっています。
- ワークブックを開く。
- 初期化されていない状態であれば、設定値を読み込む。
- 設定ワークシートを削除する。
- 単項目にすべて値を設定する。
- 設定すべきテーブルがあるのであればテーブルに値を設定する。
- ワークブックをPDFに保存する。
設定値を保管するシート名はDioDocs.FastReportBuilderで固定としていますが、こちらは実行時に指定できるようにしてもいいでしょう。設定値を保管するシートを削除していますが、これはPDF化した際にそのページがPDFに含まれないようにするための対応です。それ以外は特に説明は不要でしょう。
続いてParseSettingsメソッドの中を見てみましょう。
private void ParseSettings(IWorksheet settingWorksheet)
{
var usedRange = settingWorksheet.UsedRange;
for (var i = 1; i < usedRange.Rows.Count; i++)
{
var name = usedRange[i, 0].Value.ToString();
var type = usedRange[i, 1].Value.ToString();
if (_tableName is null)
{
if (type == "table")
{
_tableName = name;
}
else
{
_accessors.Add(new RangeAccessor(name, type, usedRange[i, 2].Value.ToString()));
}
}
else
{
_tableAccessors.Add(new TableRangeAccessor(name, type, int.Parse(usedRange[i, 3].Value.ToString())));
}
}
_isInitialized = true;
}
最初にWorksheetのUseRangeを利用して値が入っている範囲のセルを取得しています。利用されている範囲だけをパースします。対象範囲から列ヘッダーが入ってる行を飛ばして順次処理していきます。
設定シートには先頭から単項目が設定されていて、途中でtypeにtableが出現したらそれ以降はテーブルへの設定とみなして処理しています。単項目はRangeAccessor、テーブル項目はTableRangeAccesorを設定します。
ではRangeAccessorの実装を見てみましょう。
internal class RangeAccessor
{
private readonly string _name;
private readonly string _cell;
private readonly JTokenAccessor _accessor;
internal RangeAccessor(string name, string type, string cell)
{
_name = name;
_accessor = JTokenAccessor.GetConverter(type);
_cell = cell;
}
...
RangeAccessorは単項目の値の設定に利用します。そのため以下のフィールドを保持しています。
_name
JSON上の該当項目の属性名です。
_cell
値を設定するセルの名称(A1やB2など)です。
_accessor
JSON(実際にはJson.NETのJTokenオブジェクト)から値を取得し変換するアクセサーオブジェクトです。
これらの属性を利用して、JSONの値をワークシートに設定しているのが以下のコードです。
internal void Set(IWorksheet worksheet, JToken jObject)
{
worksheet.Range[_cell].Value = _accessor.Get(jObject[_name]);
}
名称_nameの属性を取得して_accessorのGetメソッドに渡し、値を取得しつつ文字列から該当セルの型(stringやDateTime、doubleなど)に変更したものを、_cellのセルに値を設定しています。
以下のコードはRangeAccesorを利用しているJsonReportBuilderのBuildメソッドのコードです。
foreach (var rangeAccessor in _accessors)
{
rangeAccessor.Set(worksheet, json);
}
設定シートに記載されていた単項目すべてをループ処理しながら、JSONから値を取得して設定しています。表に対する処理もセル名から列番号に変化していますがおおむね同じ処理です。
ただ一点注意が必要です。Excel上の表は自動的に拡張してくれないので、値を設定する前に行数が多い場合は行を追加する必要があります。
var table = worksheet.Tables[_tableName];
var rows = json[_tableName];
if (table.Rows.Count < rows.Count())
{
var addCount = rows.Count() - table.Rows.Count;
for (var i = 0; i < addCount; i++)
{
table.Rows.Add(table.Rows.Count - 1);
}
}
これでJSONとExcelからPDF帳票を生成するための実装が完了しました。
帳票生成サービスの実装
ここまででAzure Functions上での実装課題が解消され、JSONとExcelからPDF帳票の生成が可能となりました。最後にこれらを組み合わせてAzure Functions上での帳票生成を実現しましょう。
現時点のAzure Functionsの実装は次の通りです。
[FunctionName("CreateReport")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "post", Route = null)] HttpRequest req,
[Blob("templates/Invoice.xlsx", FileAccess.Read)]Stream template,
[Blob("reports", FileAccess.Write)] CloudBlobContainer outputContainer,
ILogger log)
{
await outputContainer.CreateIfNotExistsAsync();
var fileName = $"{Guid.NewGuid()}.txt";
var cloudBlockBlob = outputContainer.GetBlockBlobReference(fileName);
using (var output = await cloudBlockBlob.OpenWriteAsync())
{
req.Body.CopyTo(output);
}
return new OkObjectResult(fileName);
}
ここにJsonReportBuilderを利用して、PDFを生成する処理を追加します。
[FunctionName("CreateReport")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "post", Route = null)] HttpRequest req,
[Blob("templates/Invoice.xlsx", FileAccess.Read)]Stream template,
[Blob("reports", FileAccess.Write)] CloudBlobContainer outputContainer,
ILogger log)
{
await outputContainer.CreateIfNotExistsAsync();
var fileName = $"{Guid.NewGuid()}.pdf"; // 1.
var cloudBlockBlob = outputContainer.GetBlockBlobReference(fileName);
var builder = new JsonReportBuilder(template); // 2.
using (var input = new StreamReader(req.Body, Encoding.UTF8)) // 3.
using (var output = await cloudBlockBlob.OpenWriteAsync())
{
builder.Build(input, output, SaveFileFormat.Pdf); // 4.
}
return new OkObjectResult(fileName);
}
元のコードに対して4カ所、追加・修正を行いました。
ひとつは、生成する拡張子をtxtからpdfに変更しました。
var fileName = $"{Guid.NewGuid()}.pdf";
続いて、BLOB Storageに格納されたExcelを読み取るためのStreamが引数で渡されてくるので、それをもとにJsonReportBuilderを生成します。
var builder = new JsonReportBuilder(template);
3つ目に、以下のようにHTTP RequestボディからTextReaderを生成します。
using (var input = new StreamReader(req.Body, Encoding.UTF8))
最後に、JSONをBLOBにそのまま書き出していた箇所を、JsonReportBuilderでPDFを生成してBLOBに書き出すように修正します。
builder.Build(input, output, SaveFileFormat.Pdf);
これで完成です。公開して実際に動作させてみましょう。
先ほどコンソールから実行したプログラムのJSONデータを指定していた箇所を、JSONファイルから取得するように改修しましょう。
var jsonContent =
new StringContent(
"{\"Message\":\"Hello, Azure Functions with JSON!\"}",
Encoding.UTF8,
"application/json");
var jsonContent =
new StreamContent(File.Open("Request.json", FileMode.Open));
JSONファイルの中身はこちら(GitHub)の通りです。
実行結果が以下の通りです。一番左のExcelテンプレートから、中央と右の2ページのPDFが生成されます。
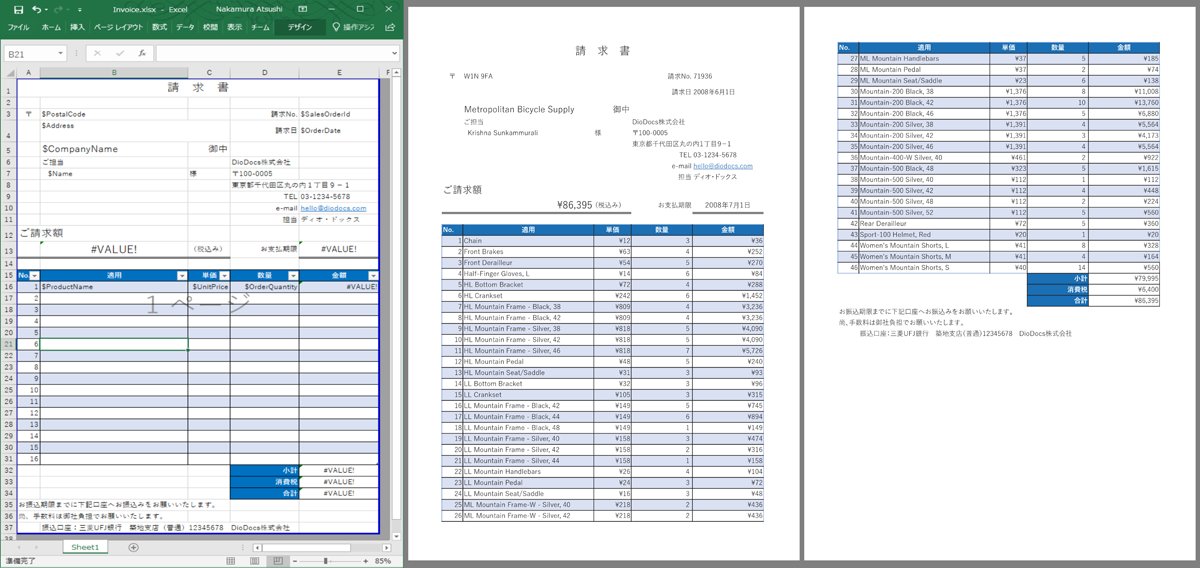
無事動作しましたね! これで帳票生成マイクロサービスの完成です!
まとめと注意事項
さて本稿では次のような帳票生成サービスを構築しました。
- Azure Functions上の帳票生成マイクロサービス
- Excelベースの帳票テンプレートからのPDF帳票生成
- 帳票生成ロジックとテンプレートを分離しコード修正なく帳票レイアウトが変更可能
ところで本稿の検証をしていく中で注意すべき点があることに気が付きました。
DioDocs for Excelを利用したPDF生成はAzure Functionsの従量課金プランでは十分な性能が出ない可能性があるということです(本稿の「Azure Functionsのプラン選択」参照)。
それでも、やはりExcelベースでの帳票生成は非常に手軽で、その点に強い魅力を感じました。
DioDocsはNuGetからパッケージをインストールすればすぐに評価利用することが可能です。皆さんもぜひ試してみてください。その魅力を感じていただけるはずです。

