






































【これまでの記事】.NET対応のクラウドデータ連携ライブラリセット「ComponentOne Data Services」活用術
必要な環境
本記事のサンプルコードは、以下の環境で動作を確認しています。
- Windows 11 Pro(22H2)
- ComponentOne Enterprise 2023J v3
- .NET SDK(8.0.101)
- Visual Studio 2022(17.8.6)
対象読者
- さまざまな種類のデータと簡単に連携したい方
- フォームや高機能なコントロールを利用したい方
- デスクトップアプリ開発、バックエンド開発が得意な方
ComponentOne Data Servicesの概要
まずは、ComponentOne 2023J v3を簡単に紹介します。ComponentOneは、メシウス株式会社が.NETプラットフォーム用に提供するUIコントロールセットです。Windows Forms、WPF、ASP.NET、ASP.NET Core、Blazor、WinUIに対応しています。このComponentOneですが、1月17日に「2023J v3」がリリースされました。2023J v3には、以下の特徴があります。
- .NET 8に対応したことによるパフォーマンスの向上
- Windows Formsにおけるリッチテキスト編集機能が正式リリースに
特に、LTS(Long Term Support)である.NET 8に対応したことで、安定した環境で良好なパフォーマンスの動作を期待できます。ComponentOne Data Servicesも簡単に紹介します。Data ServicesはComponentOneのエディションの一つで、さまざまなデータソースに接続して各種のデータ操作を実行するライブラリセットです。このData Servicesも、2023J v3において以下のように機能強化されました。
- DataConnectorにおけるSnowflake(SaaSプラットフォーム)のサポート
- 静的ファイルにおいて列のデータ型を決定するための行スキャン機能の追加
- Web API機能がASP.NET MVCとData Servicesでも利用可能に
特に、静的ファイルの行スキャン機能が追加されたことで、型情報を持たないCSVファイルやJSONファイルにおいて、列のデータ型を決定するのに役立ちます。この使用例は、後ほど紹介します。
開発環境の準備
開発環境を準備しておきましょう。本記事では、.NET 8とComponentOne 2023J v3がインストールされた環境で、Visual Studio 2022(バージョン17.8以降)を用いた開発を行っていきます。これらのインストールについては「【ComponentOne Data Services活用術】kintoneのデータをWindows FormsとBlazorで取得しよう」で紹介しているので、そちらを参照してください。当時とバージョンは変化していますが、基本的な手順は同じです。
なお、ComponentOneのインストール時に指定するエディションは、「WinForms Edition」と「Data Services Edition」としてください(他のエディションを含んでも問題ありません)。
データソースの準備
環境準備が済んだら、本記事のサンプルで使用するデータソースを準備します。Data Servicesでは、さまざまな形式の静的データファイルをサポートしているので、今回はCSV(Comma Separated Value)データとの連携を試してみます。用意するCSVファイルですが、ユーザーローカルが提供する「個人情報テストデータジェネレーター」(図1)を使って自動生成します。
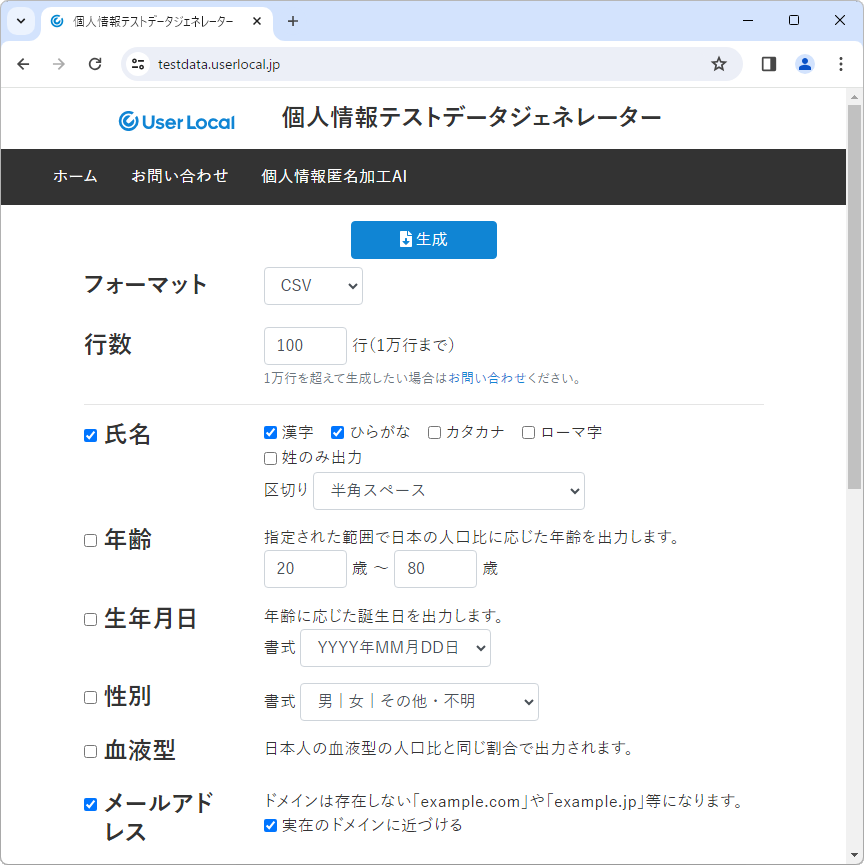
作成するデータは、顧客名簿を想定して、以下の項目とします。フォーマットはCSV、件数は100件とします。
- 氏名(漢字とひらがなでチェック。姓名の区切りは半角スペース)
- メールアドレス(好みで「実在のドメインに近づける」にチェック)
- 郵便番号
- 電話番号
- 住所
- 会社名(出力対象は0~100歳、100%とする)
以下の内容でCSVファイルが生成されていることを確認してください。先頭行が、CSVファイルにおけるデータの列名に相当します。ファイル名は、customer.csvとしておきましょう。
"氏名","氏名(ひらがな)","メールアドレス","電話番号","郵便番号","住所","会社名" "伊藤 直之","いとう ただゆき","ito_tadayuki_07656908@gmail.com","03-4660-9994","154-1001","東京都台東区浅草1-3-203","有限会社コーシン" …略…
主キーに相当する列は生成されないので、それに相当する「No」列を手動で追加します。ExcelでCSVファイルを読み込み、先頭列を挿入、列名を「No」として連番(1~)を入力します。ファイルを保存すれば完了です。
以降は、作成したCSVファイルを使ったサンプルを紹介していきます。なお、CSVファイルは自動生成されたものですが、実在する人物や会社と一致する可能性はゼロではありません。あくまでも動作検証での利用にとどめてください(よって配布サンプルには含めていません。各自で用意してください)。
[NOTE]Data Servicesで利用できるデータソース
Data Servicesでは、CSVを含め以下の静的データ、SaaSを利用できます。このうちkintoneを用いた事例は「【ComponentOne Data Services活用術】kintoneのデータをWindows FormsとBlazorで取得しよう」で紹介しています。
- OData、CSV、JSON、Salesforce、Google Analytics、Dynamics 365、kintoneなど
コンソールアプリで接続確認
データソースが準備できたら、DataConnectorsを使ってCSVファイルのスキーマ(列構成など)を出力するコンソールアプリを作成して、CSVファイルへの接続を確認しましょう。なお、Data Servicesのライブラリ構成については、第1回を参照してください。
空のコンソールアプリを作成する
Visual Studioで、空のコンソールアプリを作成します。[新しいプロジェクトの作成]から、「コンソールアプリ」(.NET Frameworkでない方)を選択して、プロジェクト名には「CSVConnectorConsoleApp」などと適当な名前を指定し、フレームワークは「.NET 8(長期的なサポート)」のままでプロジェクトを作成します。
プロジェクト作成後、CSVファイルとDataConnectorsの利用に必要なパッケージC1.AdoNet.CSVをプロジェクトに追加してください。なお、DataConnectorsにあたるC1.DataConnectorパッケージは依存関係で自動的にインストールされます。
[NOTE]英語版パッケージと日本語版パッケージ
パッケージには、名称の末尾に「.Ja」と付いたものがあります。これは日本語版のComponentOneの利用に必要なパッケージです。付いていないものは英語版に対応したパッケージです。可能な限り、「.Ja」の付いたパッケージを優先してインストールしてください。本記事では、後述するスキャン機能を使用するために、英語版のパッケージを使用しています(本稿作成時点では、日本語版では正常に動作しません。日本語版では2024J v1以降のバージョンでの対応を予定しているとのことです)。
コンソールアプリのコードを記述する
コンソールアプリに以下のリストのコードを記述します。Program.csファイルの既存のコードは全て削除して、以下のリストのコードを記述します。
using C1.AdoNet.CSV; (1)
using System.Data;
string connectionString = @"Uri='customer.csv';Trim Values=true;DetectionSchemeType=RowScan;RowsToScan=100"; (2)
using (var conn = new C1CSVConnection(connectionString)) (3)
{
conn.Open(); (4)
ShowSchema(conn); (5)
}
// DataTableの列情報と全データを出力する
void ShowDataTable(DataTable table) (6)
{
foreach (DataColumn col in table.Columns) (7)
{
Console.Write("{0} ", col.ColumnName);
}
Console.WriteLine();
foreach (DataRow row in table.Rows) (8)
{
foreach (DataColumn col in table.Columns)
{
Console.Write("{0} ", row[col]);
}
Console.WriteLine();
}
}
// CSVファイルのスキーマを出力する
void ShowSchema(C1CSVConnection conn) (9)
{
var table = conn.GetSchema("columns", new string[] { "customer" });
ShowDataTable(table);
}
シンプルなコードですが、CSVファイルを使う場合のDataConnectorsの基本的な使い方となっているので、以降のサンプルにも共通する内容となっています。(1)は、CSVファイルのプロバイダであるC1.AdoNet.CSVを使う宣言です。データプロバイダごとに名前空間が用意されます。(2)は、CSVファイルへの接続文字列の定義です。それぞれのパラメータの意味は以下の通りです。
- Uri:CSVファイルのパスを含めた名前。customer.csvファイルは、このパスでアクセスできる必要がある(この場合は実行ファイルと同じ場所)
- Trim Values:CSVデータの読み書きでトリミング(前後の空白文字などの削除)を実施するかの指定・ここではTrue(実施する)を指定
- DetectionSchemeType:スキーマ(データ型)の検出方法。この場合は行スキャンを表すRowScan
- RowsToScan:スキャンする行数。この場合は100行。0だとスキャンしない。-1だと全行をスキャン
(3)では、CSVファイルに接続するためのC1CSVConnectionオブジェクトを生成し、(4)でCSVファイルへの接続をオープンしています。(5)で、(9)で定義されているスキーマ出力関数ShowSchemaを呼び出しています。(6)は、DataTableの出力のための関数ShowDataTableの定義です。後半でCRUD処理を実装するので、そこから利用することも踏まえて独立した関数としています。
(7)からは、DataTableの列情報を出力しています。列情報は、TableName、ColumnName、OriginalColumnなどのフィールドから成ります。(8)からは、同じくDataTableの各行を出力しています。行の内容は、(7)で出力される列情報に準じたものとなります。(9)は、スキーマ出力関数ShowSchemaの定義です。DataConnectorsのgetSchemaメソッドで、CSVファイルのスキーマを取得しています。ここでのスキーマとは先頭行の列名文字列であり、このためスキーマ名は"column"としています。
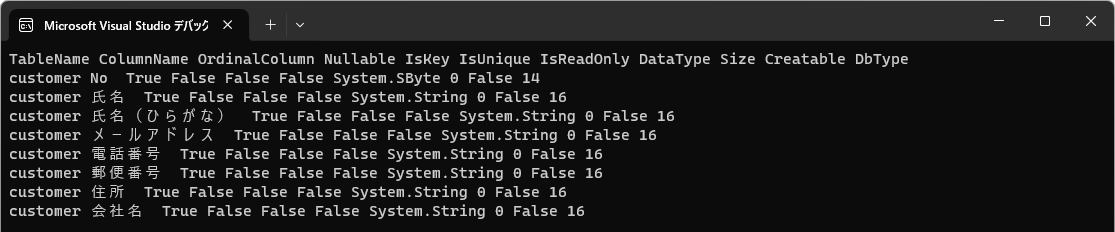
CSVファイルを設置し、アプリをビルド、実行して、図2のようにスキーマが出力されればCSVファイルへの接続は成功です。「No」列のDataTypeがSystem.SByteなど数値型になっていることを確認してください。
[NOTE]スキーマの決定方法
この例の通り、接続文字列でDetectionSchemeTypeを指定すると、列の型を自動判定できます。数値にも、整数や浮動小数点数の区別があり、日付なども判定できます。指定のない場合は、全ての列の型は文字列となります。また、行のスキャンで文字列型以外の判定を期待しても、一部でも異なるものが混じれば文字列となります(先頭の見出し行だけは例外です)。なお、上記でDataTypeがSystem.SByteとなったのは、メモリ消費ができるだけ少ない型を選択するようになっているからです。
コンソールアプリにCRUD機能を実装
CSVファイルへの接続確認ができたところで、アプリにCRUD(Create、Read、Update、Delete)機能を実装していきましょう。ここでは、DataAdapter(C1CSVDataAdapter)を使った例を紹介します。DataReader(C1CSVDataReader)を使った例は配布サンプルを参照してください。
また、ここでは全データ出力のIndex関数と、新規データ登録のCreate関数、データ削除のDelete関数を紹介します。個別行出力のRead関数、データ更新のUpdate関数については、こちらも配布サンプルを参照してください。
作成するアプリの説明
CRUDの操作は、コマンドラインで指示します。アプリのコマンドライン書式は以下の通りとします。
program [ [C|R|U|D] パラメータ]
1番目のパラメータで、CRUDの区別を指定します。省略時はインデックス(全データ)出力とします。パラメータには、CRUDごとに必要なデータを記述します。
- C:新規データをCSV形式で(No列は自動決定されるので省略可)
- R:対象のNo
- U:更新データをCSV形式で(No列に一致する行が置き換えられる)
- D:対象のNo
全データ出力を実装してみる(Index)
ここから、C1CSVDataAdapterを使ってクエリを実装していきます。C1CSVDataAdapterはC1.AdoNet.CSV名前空間にあるので、パッケージの追加は不要です。まずは、一覧表示のためのindex関数です。なお、以降で紹介する関数はコマンドラインパラメータによって振り分けて呼び出されますが、仕分け部分のコードは本記事の主旨とは関係が薄いので、掲載を割愛します。内容は配布サンプルを参照してください。
void index(C1CSVConnection conn)
{
var adapter = new C1CSVDataAdapter(); (1)
adapter.SelectCommand = new C1CSVCommand(conn); (2)
adapter.SelectCommand.CommandText = "SELECT * FROM customer";
var dataTable = new DataTable(); (3)
adapter.Fill(dataTable);
ShowDataTable(dataTable); (4)
}
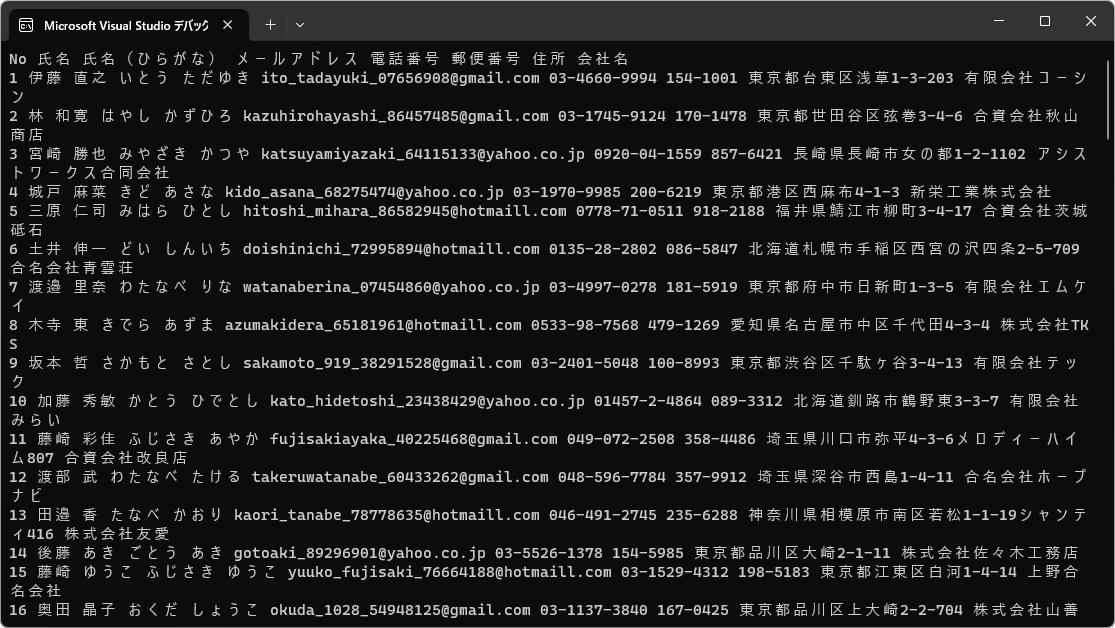
これは、DataAdapterを使う場合の典型的なコードとなっています。CRUDそれぞれの関数でもほぼ同様の展開となります。(1)は、DataAdapterであるC1CSVDataAdapterのインスタンスを生成しています。(2)からは、DataAdapterのSelectCommandプロパティで選択コマンドを生成、設定しています。この場合は全行選択のSQL文となっています。(3)からは、DataTableを生成してFillメソッドでクエリ結果を読み込んでいます。これをもとに、(4)でスキーマ情報と同様に全行を出力しています。プログラムをビルド、引数なしで実行してみて、図3のように全データが出力されることを確認してください。
新規データ登録(Create)を実装してみる
続いて、新規データ登録のCreate関数を紹介します。
void Create(C1CSVConnection conn, string record)
{
int no = 1; (1)
var cmd = conn.CreateCommand();
cmd.CommandText = "SELECT Max([No]) FROM customer";
var obj = cmd.ExecuteScalar();
if (obj != null)
{
no = Convert.ToInt32(obj);
no++;
}
string[] fields = record.Split(','); (2)
var adapter = new C1CSVDataAdapter(conn, "SELECT * FROM customer"); (3)
var dataTable = new DataTable();
adapter.Fill(dataTable);
adapter.InsertCommand = new C1CSVCommand(conn); (4)
adapter.InsertCommand.CommandText = "INSERT INTO customer([No],[氏名],[氏名(ひらがな)],[メールアドレス],[電話番号],[郵便番号],[住所],[会社名]) VALUES(@No,@Name,@Kana,@Email,@Tel,@Zip,@Address,@Company)";
adapter.InsertCommand.Parameters.Add("@No", "No");
adapter.InsertCommand.Parameters.Add("@Name", "氏名");
adapter.InsertCommand.Parameters.Add("@Kana", "氏名(ひらがな)");
adapter.InsertCommand.Parameters.Add("@Email", "メールアドレス");
adapter.InsertCommand.Parameters.Add("@Tel", "電話番号");
adapter.InsertCommand.Parameters.Add("@Zip", "郵便番号");
adapter.InsertCommand.Parameters.Add("@Address", "住所");
adapter.InsertCommand.Parameters.Add("@Company", "会社名");
var customerRow = dataTable.NewRow(); (5)
customerRow["No"] = no;
customerRow["氏名"] = fields[1];
customerRow["氏名(ひらがな)"] = fields[2];
customerRow["メールアドレス"] = fields[3];
customerRow["電話番号"] = fields[4];
customerRow["郵便番号"] = fields[5];
customerRow["住所"] = fields[6];
customerRow["会社名"] = fields[7];
dataTable.Rows.Add(customerRow);
if (adapter.Update(dataTable) < 0) (6)
{
Console.WriteLine("作成でエラーが発生しました。");
}
}
やや複雑に見えますが、基本的な構造はIndex関数と同じです。
(1)からは、挿入する行のNo列の値を求めています。具体的には、SQLのMax関数を使用して、No列の最大値を+1して求めています。(2)では、関数引数に与えられた登録データ(CSV)を分割して、文字列の配列を取得しています。(3)はIndex関数と同様で、全行をDataTableに取り込んでいます。(4)からは、挿入コマンドを生成しています。SQLのINSERT文を生成した後、パラメータをParameters.Addメソッドで追加しています。
(5)からは、DataTableに新しい行を追加し、各列に(2)で作成した文字列を割り当てています。これで、追加する行が完成するので、最後にRows.AddメソッドでDataTableに追加します。(6)のUpdateメソッドで、DataTableへの追加をデータソース(CSVファイル)に反映します。戻り値が負の場合はエラーメッセージを出力しています。アプリをビルドして、コマンドラインパラメータを例えば以下のように指定して実行し、CSVファイルを確認するか全データ出力を試してみて、新しい行が追加されていればCreate関数は正しく動作しています。
c ",NewName,NewKana,NewMail,NewTel,NewZip,NewAddress,NewCompany"
データ削除(Delete)を実装してみる
最後に、データ削除のDelete関数を紹介します。
void Delete(C1CSVConnection conn, long sno)
{
var adapter = new C1CSVDataAdapter(conn, $"SELECT * FROM customer WHERE [No] = {sno}"); (1)
var dataTable = new DataTable();
adapter.Fill(dataTable);
adapter.DeleteCommand = new C1CSVCommand(conn); (2)
adapter.DeleteCommand.CommandText = "DELETE FROM customer WHERE [No] = @no";
adapter.DeleteCommand.Parameters.Add("@no", "No");
var customerRow = dataTable.Rows[0]; (3)
customerRow.Delete();
if (adapter.Update(dataTable) < 0) (4)
{
Console.WriteLine("削除でエラーが発生しました。");
}
}
こちらも、基本的な構造はIndex関数、Create関数と同じです。(1)では、削除対象の行をDataTableに取り込んでいます。Index関数、Create関数と異なり、処理対象の行を特定するときの記述となります(Read関数、Update関数でも同様です)。(2)からは、削除コマンドを生成しています。SQLのDELETE文を生成した後、パラメータをParameters.Addメソッドで追加しています。
(3)からは、DataTableから0番目の行(すなわち削除対象の行)を削除しています。2行に分けていますが、dataTable.Rows[0].Delete()としても同様です。(4)のUpdateメソッドで、DataTableでの削除をデータソース(CSVファイル)に反映します。戻り値が負数の場合はエラーメッセージを出力しています。アプリをビルドして、コマンドラインパラメータを例えば以下のように指定して実行し、CSVファイルを確認するか全データ出力を試してみて、No=20である行が削除されていればDelete関数は正しく動作しています。
d 20
まとめ
今回は、CSVデータをComponentOne Data Servicesを使って操作する事例を紹介しました。従来のADO.NETにおける手順とほとんど変わらず、静的なデータを利用できることをお伝えできたのではないかと思います。
次回は、このアプリを一括処理に対応させて、Data Servicesが大量のデータの処理にも対応できることを紹介します。また、Entity Framework連携によるモデル指向のデータ操作を、Windows Formsアプリを作成する事例を通じて紹介します。

