






































本稿はActiveReportsの旧バージョンを用いた内容となっています。最新版に基づいた記事は連載の目次「5分でわかるActiveReports帳票」をご参照ください。
はじめに
ActiveReports for .NET(以下ActiveReports)は、Visual Studioと統合された使いやすいレポートデザイナや、高機能なレポートビューア、多彩な出力形態をサポートする帳票作成コンポーネントです。
今回は、前回に続き帳票アプリケーションを設計するための手順について紹介していきます。
これまでの記事
- 第1回:5分で"もっと"わかるActiveReports帳票-ランタイムデザイナの開発
- 第2回:5分で"もっと"わかるActiveReports帳票-Visual Studio 2008に対応したActiveReportsの新機能
- 第3回:5分で"もっと"わかるActiveReports帳票-帳票完成時にチェックしておきたいポイント集
- 第4回:5分で"もっと"わかるActiveReports帳票-帳票アプリケーション設計のポイント(1)
対象読者
- Visual Basic 2005/2008またはVisual C# 2005/2008を使ってプログラムを作ったことのある方。
- 帳票作成ツールに興味のある方。
必要な環境
開発ツール
- Visual Studio 2008
- Visual Studio 2005(※Windows Vistaで開発する場合はVisual Studio 2005 Service Pack 1 Update for Windows Vistaの適用が必要です)
- Visual Studio .NET 2003
Visual Studio 2005/2008 Express EditionではActiveReportsをインストールできません。
データモデルを設計しよう
前回は、ActiveReportsを利用した帳票アプリケーションで設計すべきポイントとして、「データモデルの定義」と「帳票レイアウトの定義」の2つがあると説明し、後者の「帳票レイアウトの定義」を中心に解説しました。今回は残っている「データモデルの定義」について解説していきますが、その前に、前回の内容を簡単におさらいしておきましょう。
帳票レイアウトの定義は「出力構造の定義」と「出力項目の定義」の2工程に分かれます。出力構造の定義では、ユーザーとの打ち合わせから得られたレイアウト案を元に出力構造を洗い出します。この工程では、帳票のレイアウトから繰り返し構造を抽出し、ActiveReportsのレポートファイルに用意された各種ヘッダ/フッタセクションとDetailセクションに対応づけていきます。
出力構造の定義が終わったら、次は出力項目の定義です。セクション定義済みのレポートファイルにLabelコントロールやTextBoxコントロールを配置して、出力項目の書式やフォント、折り返し設定などを定めていきます。出力項目を表すコントロールのDataFieldプロパティにレポートデータソースの各フィールド名を設定することで、ActiveReportsの帳票アプリケーションは完成します。
データモデルを意識しなくても帳票は作れる?
帳票アプリケーション開発の現場で使われている設計書を見てみると、出力項目の配置や書式など「帳票レイアウトの定義」は割と丁寧に記述されていることが多いのですが、帳票アプリケーションが読み取るためのデータについてはあまり細かく説明されていないことがあります。直接目にする帳票レイアウトと比べて、データモデルのほうは意識されることが少ない、ということでしょうか。
ActiveReportsでは、レポートデザイナのDetailセクションに表示されたアイコンをクリックして「レポートデータソース」ダイアログを起動し、データベースの接続やXMLファイルの情報を与えるだけで、(データの形をあまり考えなくても)簡単にデータバインドを実装できます。
これは間違いなくActiveReportsの大きな長所なのですが、反面、いきあたりばったりの実装でもそこそこ動くアプリケーションができてしまい、複雑なSQLを駆使した帳票の集計ミスが後になって見つかることも少なくありません。

帳票アプリケーションを設計するときは、目に見える帳票レイアウトの定義だけでなく、どのような構造のデータを読み取るのかについてもしっかり定義しておくことが重要です。今回は、ActiveReportsのレポートファイルで使うためのデータ構造を設計するポイントについて解説していきたいと思います。
データモデル設計のメリット
前回、ActiveReportsのレポートファイルで使うためのデータ構造を「データモデル」と呼ぶことにしました。帳票アプリケーションを開発するときは、データモデルを明確に定義しておくことで場当たり的な実装をけん制し、品質の高いアプリケーションを開発できるようになります。
ActiveReportsでは、レポートデータソースとしてSQL ServerなどのRDBMSや、CSVやXMLといったデータファイルなどさまざまな形式のデータに接続して帳票を出力できます。しかし、どのようなデータソースであってもDetailセクションに定義された1件分のデータを繰り返し出力していくのが基本です。そのため、ActiveReportsを利用した帳票アプリケーションの設計では、RDBのテーブルと同じような「行×列の表形式で表されるデータ構造」をベースにデータモデルを考えていくのがよいでしょう。
読者の皆さんの中には「このようなものを定義してなんの意味があるのか」と思われる方もいるかもしれません。しかし、帳票アプリケーション設計の段階でデータソースに依存しない形でデータモデルを定義しておくと、データの論理構造と表現形式の分離がはっきりとし、メンテナンス性が向上するというメリットがあります。例えば、それまでXMLファイルを読み込んで出力していた帳票アプリケーションがあったとしましょう。このXMLファイルは帳票アプリケーションのデータモデルに準拠した構造になっています。ここで、同じようにデータモデルに準拠した構造でRDBのテーブルを作れば、XMLベースのファイル帳票アプリケーションがそのまま、データベース帳票アプリケーションとして再利用できるのです。
この他にも、独立したデータモデルを作っておくと「開発用データベースが準備できるまではテスト用のスタブで仕事を進めておく」といった手段をとることもでき、開発効率の面でもメリットがあります。
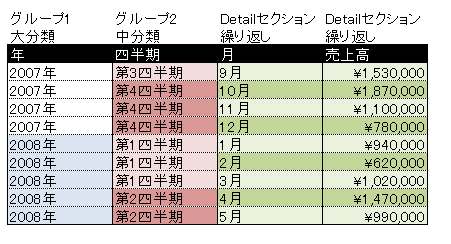


また、レポートデータソースとして指定するSELECT文やXMLファイルを直接読むよりも、データソースとは独立したデータモデルを用意しておくほうが、その帳票が何を出力するのかがわかりやすくなります。データモデルはあくまで抽象的な型の定義なので、ソースファイルとして実装するには具象クラスを使うよりもインタ-フェイスを使うのがよいでしょう。たとえばDetailセクション1件分を表す型をIDetailというインタ-フェイスで定義しておき、データモデル全体はIEnumerable<IDetail>のような形にしておけば、データソースの種類に依存しないモデルを作ることができます。また、IEnumerableインタ-フェイスにしておくことで、LINQによる操作も容易になります。
以下は、先ほど紹介した表形式のデータモデルをC#/VBのインターフェイスとして定義したものです。
public interface IDetail { public int Year { get; set; } public int Quarter { get; set; } public int Month { get; set; } public decimal SalesAmount { get; set; } }
Public Interface IDetail Property Year() As Integer Property Quarter() As Integer Property Month() As Integer Property SalesAmount() As Decimal End Interface
データモデルを用意しておくと、以下のように帳票生成部分のロジックをデータソースと分離することができます。帳票生成部分であるForm_Loadメソッドの中身を変えることなくGenerateDataメソッドを変更するだけで柔軟にデータソースを取り替えることが可能です。
private IEnumerable<IDatail> GenerateData() { //データ生成処理を記述 } private void Form1_Load(object sender, EventArgs e) { IEnumerable<IDetail> data = GenerateData(); NewActiveReport1 rpt = new NewActiveReport1(); rpt.DataSource = data.ToList(); rpt.Run(); }
Private Function GenerateData() As IEnumerable(Of IDetail) 'データ生成処理を記述 End Function Private Sub Form1_Load(ByVal sender As System.Object, _ ByVal e As System.EventArgs) Handles MyBase.Load Dim data = GenerateData() Dim rpt As New NewActiveReport1 rpt.DataSource = data.ToList() rpt.Run() End Sub
データモデル設計の3ポイント
それではさっそく、データモデルを設計するためのポイントについて紹介しましょう。
先ほど「データモデルは行×列の表形式をベースに考えるのが良い」と説明しましたが、だからといって帳票アプリケーションで使うデータモデルが、何もかもRDBのテーブルと同じ形になるわけではありません。データモデルを設計するときに考えるべきポイントは、ズバリ、以下の3つになります。
- 抽出条件の定義
- フィールドの型を定義
- 並び順の定義
最初の「抽出条件の定義」では、レポートデータソースから読み取るデータの範囲を定義します。データベース帳票の場合は、RDBMSに対して発行するSQL文のWHERE句を指定することで、抽出条件を規定することができます。ファイル帳票の場合はあらかじめ抽出条件に一致するデータだけを含むファイルを用意して、それを読み取ることが多いと思いますが、場合によってはファイル読み取り時に不正なデータをスキップするなどの処理が必要かもしれません。
次の「フィールドの型を定義」では、データモデルの各フィールドがどのようなデータ型になるのかを考えていきます。RDBのテーブルでは、フィールドを定義する列の型として文字列型や数値型、日付・時刻型などのデータ型を利用できますが、ファイル帳票の場合は、(データの読み取り時点では)すべてのデータが文字列として扱われます。データの集計結果を表示する帳票であれば、数値が期待されるフィールドで「aaaa」などの文字が入ってくるとデータを正しく集計することができなくなってしまいます。
最後の「並び順の定義」では、データモデル内の行がどのような順番で並んでいるかを定義します。データベース帳票の場合はRDBMSに対して発行するSQL文のORDER BY句で並び順を定義します。ファイル帳票の場合は、ファイル提供元がどのような順序でデータを並べているかを確認しておけばOKでしょう。万が一データの並び順が保証されていない場合は、帳票アプリケーションで読み込む前に、データを並べ替える処理が必要になるでしょう。ただし、データの並べ替え処理自体は帳票出力の本質ではないため、帳票アプリケーションとは分離しておくのが賢明です。
ここからは、今挙げた3つのポイントについて、気をつけたいポイントをそれぞれ解説します。
抽出条件だけでなく、イレギュラーケースについても考えておこう
帳票アプリケーションのデータモデルを設計するポイントとして、最初に「抽出条件の定義」を挙げました。毎回出力するデータの件数があらかじめ決まっているような場合や、読み込んだデータを全件出力するような場合は特に抽出条件を考える必要は特にありません。しかし、通常は出力するタイミングによってデータの件数は変わると考えるのが自然です。データモデルの定義内容にはまずどのような条件のデータを対象とするのかをはっきり指定しましょう。もし、特に条件がなくすべてのデータが対象となる場合でも、設計意図は明示的に「すべてのデータを対象とする」と記述すべきです。
データモデル側では取り扱うデータの範囲を抽出条件として定義しますが、同時に、帳票レイアウト側でも考えておかなければいけないことがあります。それは「検索結果が0件だったときはどうしたらいいのか」ということです。帳票アプリケーションの開発中はあらかじめ用意したテスト用のデータを繰り返し表示しながら、プログラムを作成していくことが多いのではないかと思います。そうしているとつい、データがないケースについてのテストを忘れてしまいがちです。
抽出条件に合致するデータが得られなかった場合、帳票レイアウトでは特別な項目を表示する必要があるかもしれません。データ全体がゼロ件になるケースはもちろん、グループ単位で該当するデータがゼロ件になったときはどうしたらいいのかについても、漏れなく指定するようにしましょう。
データ型は厳密にして、余計な情報はもたない
データモデルで定義する各フィールドのデータ型は、できるだけ目的にあったデータ型を選びましょう。例えば、数値を表すデータはintなど数値を表す型を使い、文字や文を表現するデータ型はstring型を使います。日付や時刻を表すデータはDatetime型で定義します。特に金額を扱う帳票の場合は、数値型であってもfloatやdoubleのような浮動小数型を避け、桁落ちの発生しないdecimal型を使いましょう。
データの取得元がCSVファイルや、ネットワーク経由で取得するXMLであることがわかっている場合、すべて文字型でデータモデルを定義してしまうことがありますが、設計判断としてはあまり好ましいものではありません。
たしかに、フィールドに設定された値をそのまま表示するだけなら、文字型と数値型のどちらを使ってもよいかもしれません。しかし、グループヘッダ・フッタを用いて集計値を計算する場合は、文字型を数値型に変換する必要があります。ActiveReportsではデータが文字列であったとしても(気を利かせて)自動的に型変換してくれますが、データソースの各フィールドが型を持つことができるのであれば、数値型のデータをDataFieldプロパティに指定すべきです。
また、数値や日付については「"10000"→10,000円」や「"2008-08-01 00:00:00"→2008年8月1日」などのように、データに対して書式付けをしたいという理由で文字列型が選ばれることもあります。しかし、これもあまり良い方法ではありません。データそのものが書式情報を持ってしまうと、書式を変えるためにはデータそのものを変更しなければならず、データ変換用のプログラムを作成するか、元データを生成するプログラムの方で書式を変更する必要があります。データモデルはあくまで「値」を正しく保持することに徹し、書式付けのような「データをどう見せるか」の機能は帳票レイアウトに任せるべきです。
このほか、データ型を指定するときは、読み込んだデータの値がnull(空文字)であったときの対処についても考えておく必要があります。文字列型であれば、ほとんどの場合「null=空白」としておけば間違いないですが、数値型の場合は空欄にするのか、ゼロにするのかなど、場合によって最適な値は異なるでしょう。
データの順序が決まっていないと、データの集計結果が変わってしまう
抽出条件、データ型の設計が終わったら、次は帳票を出力するためのデータ出力順序を指定するのですが、ActiveReportsの帳票出力において、データソースから取得されるデータがどのような順序で並んでいるかはとても重要な要素です。
データモデルを設計するときは必ず、データの並び順を明示的に指定しましょう。ActiveReportsでは、データソースから取得した値を読み取った順番に処理していくため、データの並び順が決まっていないと予期せぬ集計結果を出力することがあります。
例えば、あるフィールドのデータが「A→A→B→A」のような順序で読み込まれると、このフィールドは「A(2件)」「B(1件)」「A(1件)」のようにグループ分けされ、最初に出てきたAと後に出てきたAが別なグループとして扱われてしまいます。
特にレポートデータソースとしてRDBMSを使う場合、SQL文のORDER BY句で順序を指定していないために結果セットの順番が変わってしまい、上記のような問題が起こってしまうことがあります。レポートデータソースとしてSQLを記述する場合は、必ずORDER BY句を明示的に指定するようにしましょう。
おわりに
前回、今回の2回にわたって、帳票アプリケーション設計で押さえておきたい2つのポイントについて解説しました。
これまで前半5回、後半5回の計10回にわたりActiveReportsの機能を紹介してきましたが、本連載は今回でひと区切りとなりますが、ActiveReportsにはこれまでに紹介したもの以外にも、多くの便利な機能があります。グレープシティ社のActiveReports 3.0J FAQページには有益なTipsが多数紹介されているので、開発中に困ったことがあれば、まずここで調べてみるのがよいでしょう。

