




































はじめに
PHPにおいてDBアクセスを行う場合、古くはPHPLIB、最近ではPEAR::DBやPEAR::DB_DataObjectなどを利用して、処理の実装を行います。PHPでは、こうしたモジュールのおかげで容易にDBにアクセスできるため、実用的なwebによるサービスを簡単に構築できます。
現在のPHPにおいては、PEARライブラリが、事実上の標準ライブラリの位置付けにあります。しかし、PEAR::DBは、その機能の割に実行速度が出ないと指摘されることが多く、PEAR::DB_DataObjectは、DBのスキーマ定義に基づいて動作する構成となっているため、その設計概念に馴染めないと、使い難い印象を拭えません。
そこで、PEAR::DB程度の機能しか持っていなくて、機能面でリッチではないけれども、その分、PEAR::DB_DataObjectよりも自由度が高く、手軽に使えて、尚且つ、PEAR::DBよりも実行速度の出るDBアクセスモジュールがあれば、利用価値があると考えられます。
本稿では、そうした位置付けにあるDBアクセスモジュールとして「ADOdb」を紹介します。
対象読者
主に、LAMP構成(Linux+Apache+MySQL+PHP)の環境下で、Webアプリケーション構築を行った経験がある方を対象としています。特に、PEAR::DBの代替案を検討されていて、ADOdbを知らない方や、日本語の資料がなくて困っていた方に有益でしょう。
必要な環境
筆者は、本稿の内容に関して、White Box Enterprise Linux 3.0 Resipin1、CentOS 4.0(x86-64版)といった複数のLAMP環境で開発、動作確認をしています。Googleなどで検索すると、ADOdbを利用している、PHPで書かれたアプリケーションを、Windows上で動作させる話題などが見つかるので、Windows上でも、問題なく動作するものと考えられます。
ADOdbとは
「ADOdb」とは、PHPにおいてDBのアクセスを行うためのモジュールです。
キーワードを「php adodb」として日本語でググると、侵入検知システム「Snort」のフロントエンド「ACID」の動作に必要なモジュールなので、インストールの仕方はこれこれ、などと書かれたページをたくさん見かけます。「ACID」の他にも、「PostNuke」「Moodle」「phpWiki」「TikiWiki」「Mantis」など、PHPで構築された有名なアプリケーションで利用されています。本稿の読者であれば、どれか1つくらいは試された経験があるでしょう。海外では実績のあるモジュールなのです。
標準の地位にあるPEAR::DB、PEAR::DB_DataObjectを差し置いて、有名プロジェクトへの採用実績があるのは、ADOdbに何らかの優位性があることを示しています。
まず、PEAR::DBとの比較において、速度的優位性があります。少し古い情報になりますが、ベンチマーク結果を掲載した「Comparing ADODB with PEAR DB, MDB, dbx, Metabase and Native MySQL」を見ると、ADOdbはPEAR::DBよりも高速に動作するとの結果が出ています。Zend Optimizerなど、コードをプリコンパイルしてキャッシュしておき、PHPの実行自体を高速化する環境下では、ADOdbとPEAR::DBの差は縮まる傾向があります。しかし、さらにADOdbには、C言語で書かれた共有ライブラリと連携して、速度を稼ぐ拡張が用意されています。
また、PEAR::DBのサポートするDBの種類は、本稿執筆時点の日本語マニュアルに記載されているもので13種類となっているのに対して、ADOdbでは38種類となっています。これらの中には、同じDBの異なる版のためにそれぞれ調整されたものを、別の種類として数えているものも含まれています。しかし、例えば、PEAR::DBではODBC経由でないと使えないDB2を、ADOdbでは、十分にテスト済みのDBとして使えるなど、ADOdbに優位性が認められます。
次に、PEAR::DB_DataObjectでは、DBのスキーマ定義を自動的に取得して、そのDBをハンドリングする専用のオブジェクトを生成します。オブジェクトのメンバにアクセスすることで、DB内の情報にアクセスできるので、SQLからある程度解放されるメリットがあります。しかし、DBから取得できる情報をオブジェクトから取得できるように、DBの論理構造だけを表現して、SQLで操作される実体を隠蔽する程度の機能であれば、それほど実装は難しくありません。
また、オブジェクトを操作するための表現をSQLから分離しようとした結果、結局はSQLよりも表現力が劣った業界標準でないAPIを構築してしまう危険性とその弊害の方が大きい、と考えられます。SQLは今となっては古臭さも目に付きますが、SQLに変わる標準的なDB操作APIが存在しない以上、手放すのは危険でしょう。ADOdbにも、そうした野心的な機能が実装されていますが、必ず使わなければならないものでもないですし、十分にテストも行われていない感じなので、しばらくは様子見でしょう。
ADOdbには他にも、各種DBを抽象化して同一視するための枠組みや、SQL文の生成支援機能、DBへの操作をロギングし、DBのパフォーマンスを監視する機能などが盛り込まれています。
Nagadodbの基本的な機能
ADOdbは、基本的に、DBとの接続を表すADOConnection型のオブジェクトに対して、DB操作を与えることで、その結果をADORecordSet型のオブジェクトとして取得できるようになっています。但し、「RecordSet」という名前からも察しがつくように、SQLにおけるSelectの実行結果を返すのが基本と考えられています。DBに対するINSERT/UPDATE/DELETEといった操作の場合は、操作によって影響を受けた行数などの情報を、ADOConnection型のオブジェクトから得るようになっています。
それでは、実際にどのような操作が行えるのか、順に見ていくことにしましょう。ここでは、筆者が実務で利用するべく作成した「Nagadodb」クラスの中身を覗きながら、解説していきます。Nagadodbは、筆者の考え方に沿って、ADOdbを利用しやすくしたラッパーです。PhpDocumenterで処理できるような日本語コメントを入れてありますので、筆者と設計思想が異なる方は、コメントとコードを読んで、自分なりのラッパーを作ることができるでしょう。
準備
まずは、ADOdbとNagadodbが動作する環境を整えましょう。
ADOdbそのものは、ADOdbの公式ページからリンクを辿ってダウンロードできます。Project: ADOdb: File Listから、最新版の「adodb-x.xx-for-php」をダウンロードして下さい。本稿執筆時点での最新版は、「4.61」です。ADOdbは、まだまだ精力的に開発が継続されているプロジェクトなので、頻繁にアップデートされています。本稿の情報が古くなってしまって、正しくなくなる可能性がありますので、注意して下さい。ダウンロードしたら展開し、皆さんそれぞれのポリシーに従って、配置して下さい。DocumentRoot以下に置く必要はありません。ここでは、「/usr/local/php-modules/」に「adodb」ディレクトリを配置したものとして、話を進めます。
次に、上記「nagadodb.zip」をダウンロードして、展開して下さい。中に含まれている2つのディレクトリのうち、「nagadodb」ディレクトリを、皆さんそれぞれのポリシーに従って、配置して下さい。これも、DocumentRoot以下に置く必要はありません。ここでは、「/usr/local/php-modules/」に「nagadodb」ディレクトリを配置したものとして、話を進めます。つまり、「adodb」ディレクトリと横並びに配置するものとします。
もし、「adodb」ディレクトリと「nagadodb」ディレクトリを異なる場所に配する場合には、以下に示す修正を施して下さい。Nagadodbは、ADOdbのラッパーなので、ADOdbの位置を知っている必要があります。「nagadodb.inc」では、
if(!defined('NAGA_ADODB_PATH')) { /** adodb.inc.phpの場所を指定(外部で指定も可) */ define('NAGA_ADODB_PATH', '../adodb'); }
という記述によって、ADOdbの位置を設定しています。ADOdbの位置に応じて変更する必要がある場合は、このモジュールを読み込む前にdefine()することで対応できます。「nagadodb.zip」の場合、「nagadodb.zip」に含まれる、もう1つのディレクトリ「htdocs」の「test.conf」に修正すべき個所があります。
「nagadodb.zip」に含まれる、もう1つのディレクトリ、「htdocs」ディレクトリは、DocumentRoot以下に配置して下さい。このディレクトリにあるファイルに、Webサーバを介してアクセスすることで、Nagadodbの動作サンプルを試せるようになっています。
また、ADOdbに含まれるログ機能を拡張して利用するために、「adodb」ディレクトリの「adodb-perf.inc.php」内で定義されているfunction& adodb_log_sql(&$conn,$sql,$inputarr)に追記します。この処理の流れを読んでもらうと、$tracerに文字列を組み立てている処理を見つけられます。ここに、
global $_NAGA_ADODB_TRACER; if(isset($_NAGA_ADODB_TRACER)) $tracer .= '<br>'.$_NAGA_ADODB_TRACER;
という処理を、
$tracer = (string) substr($tracer,0,500);
の直前、つまり、$tracer確定の直前に入れる修正を行って下さい。所謂「ハック」というやつですね。
この動作サンプルでは、MySQLを想定したものとなっており、試験用のDBやユーザを作成するのも、PHP上で行うようになっています。このため、最初にDBを作成する「setup.php」のみ、root権限でDBに接続させる必要があります。具体的には、「test.conf」の
// DSN文字列(DB作成用) define('ROOT_DSN', 'mysql://root:@localhost');
で定義されているDSN(DataSourceName)文字列を適切に修正する必要があります。MySQLでは、自分で設定するまで、rootパスワードが未設定の状態であることが多いので、もしrootパスワードが未設定の場合は、修正の必要はありません。ちゃんとrootパスワードを設定されている場合は、
// DSN文字列(DB作成用) define('ROOT_DSN', 'mysql://root:pass@localhost');
として、DSN文字列にパスワードを組み込んで下さい。DSN表現は、PEARでも使われていますので、皆さんにもお馴染みだと思います。MySQLを使う場合は、一般的に
$db = new Nagadodb("mysql://user:pass@localhost/db_name?persist");
のように書けます。最後のパラメータpersistは、DBへの持続的接続を指定しています。
サンプルの初期化処理を実行させる
結構面倒な準備をお願いしましたが、準備が整ったら、早速、サンプルを動かしてみましょう。
「setup.php」に、Webサーバ経由で、ブラウザを使って、1回だけアクセスして下さい。すると、「test.sql」を実行して、「DBを生成しました。」という返答を得ることができます。DBクライアント(mysqlコマンドなど)を使ってDBを確認すると、テーブルなどが作成されていることが確認できるでしょう。
「setup.php」では、Nagadodb型オブジェクトの生成と、executeFileメソッドの実行を行っています。
executeFileメソッドは、SQL文の記述されたファイルを実行するメソッドです。指定されたファイルの内容をSQL文と解釈して、書かれた順に逐次実行していきます。また、第2引数をとることもでき、第2引数を配列で、
$argArr["name"] = "value";
の形式で、名前と、それに対応した値の組を、複数与えると、ファイル内に記述された「$name」を全て対応した値で置き換えてから、SQL文を実行します。複数のSQL文を組み合わせた、定型的な処理を行いたい場合などに利用できるでしょう。
NagadodbのexecuteFileメソッドの機能は、ADOdbと直接関係するものではありませんが、こうした機能は有益です。PHPで構築された多くのアプリケーションにおいて、変数の内容に基づいたSQL文を組み立てるために、コード内にSQL文が埋め込まれてしまう傾向があります。executeFileメソッドのように、PHPとSQL文を分離できる仕組みがあれば、本来異なる2つの技術を分離してメンテナンスできます。SQL文には詳しいけれども、PHPは使ったことがないスタッフには、分離したSQL文の構築と最適化を、業務として与えることができます。
接続したいDBがMySQLでない場合は、「test.sql」の中身を参考に、「nagadodb_db」というDBを生成し、「test」テーブルと「adodb_logsql」テーブルをその中に作り、ユーザ名「nagauser」パスワード「nagapass」でフルアクセスできるようにして下さい。そうすることで、「setup.php」を実行したのと同じような状態を作れます。この場合、「test.conf」の
// DSN文字列 define('NAGA_DSN','mysql://nagauser:nagapass@localhost/nagadodb_db?persist');
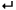
を修正する必要があります。例えば、PostgreSQL7.xを使っているなら、
// DSN文字列 define('NAGA_DSN', 'postgres7://nagauser:nagapass@localhost/nagadodb_db?persist');
などとする必要があります。
サンプルの操作:新規登録
初期化が終わったら、「index.php」に、Webサーバ経由で、ブラウザを使って、アクセスして下さい。このサンプルでは、メモを残すことができます。まずは、新しいメモを残して見ましょう。ID欄に何も入れず、memo欄にメモを書き込んで、「更新」を押すと、メモ一覧に新しいメモが追加されることが確認できます。
新規登録時の「index.php」では、Nagadodb型オブジェクトを生成し、操作ログを全て残すように設定したあとで、$recordの内容に基づいてDBへの追加を行います。
DBの操作ログの扱い方を決めるNagadodbのsetLoggingLevelメソッドでは、引数に応じて、DBが操作されたことをログに残します。ADOdbのLogSQLメソッドを使うと、実行したSQL文を、ログとして残すことができます。この機能を使うための仕組みが、setLoggingLevelメソッドとして実装されています。引数に「full」を与えると、全てのDB操作をログに残します。ログは、「adodb_logsql」テーブルに残されます。
ADOdbが実装しているログ機能では、実行されたSQL文と一緒に、SQL文を実行したコンピュータのIPアドレス、SQL文を実行したPHPファイルを記録するようになっています。しかし、実際のログとして活用することを考えると、誰がそのPHPファイルを実行したのか特定できる情報が必要です。Nagadodbでは、ADOdbが実装しているログ機能を拡張して、SQL文を実行するPHPファイルをブラウジングした端末のIPアドレスとユーザエージェント文字列も合わせて記録するようにしています。準備のところで「adodb-perf.inc.php」に対して行ったハックは、この機能のためです。もし、合わせて記録する内容を変更したい場合は、setTracerメソッドが使えます。
DBへの追加にはNagadodbのinsertメソッドが用いられます。insertメソッドでは、追加するデータの配列表現を元に、1行のデータを、テーブルに追加します。配列表現は、カラム名を配列のindexに、追加したいデータを配列の値とします。「index.php」では、配列$recordに、id、date、memoが設定され、使われています。
サンプルの操作:修正
続いてメモを修正してみます。修正するメモのIDをメモ一覧から選び、ID欄に入力し、memo欄に新しいメモを書き込んで、「更新」を押すと、メモ一覧でメモが修正されたことが確認できます。
修正時の「index.php」では、$recordの内容に基づいてDBへの更新を行います。
DBの更新にはNagadodbのupdateメソッドが用いられます。updateメソッドでは、更新するデータの配列表現を元に、Where条件に一致する行のデータを更新します。配列表現は、先ほどの追加時と同様です。「index.php」では、ID欄に入力されたものと同じidを持つ行に対して更新が行われています。メソッドの戻り値で、影響を与えた行数が分かるので、それに応じたメッセージを出力できるようになっています。
DBの操作時には、該当する行がなかったら新規登録、あったら修正という操作を行いたいことがあります。例えば、ユーザ管理を行うDBで、ユーザの最新の状態を保持している場合、既にユーザ情報が存在するなら更新、なかったら新規ユーザとして登録、といった処理を行うことがあるでしょう。Nagadodbでは、updateBe4Insertメソッドによって、そうした処理を実現できます。
サンプルの操作:削除
最後にメモの削除を行ってみます。削除するメモのIDをメモ一覧から選び、ID欄に入力し、「更新」を押すと、メモ一覧でメモが削除されたことが確認できます。
削除時の「index.php」では、Nagadodbのdeleteメソッドによって、Where条件に一致する行のデータをデリートします。
パフォーマンスモニタ
サンプルを操作して、DBの操作が行えることが確認できたら、DBの操作結果について見てみます。
ADOdbでは、パフォーマンスモニタという機能が提供されており、DBの運用状況を確認して、チューニングの基礎情報を得たり、「adodb_logsql」テーブルに残されたログを確認したり、SQL文を発行したりすることができます。「pm.php」に、Webサーバ経由で、ブラウザを使って、アクセスして下さい。パフォーマンスモニタの操作画面が現れます。
「View SQL」では、これまでに実行されたSQL文を見ることができます。Nagadodbによる拡張によって、個々のSQLをクリックしてみると、実行に使われたブラウザの情報が確認できます。もしDBを間違って操作した犯人を探したければ、間違った操作を実行されたSQL文一覧から探し出し、その操作がどの端末から行われたか突き止められます。
「Run SQL」では、SQL文を実行することができます。メンテナンスなどの、ちょっとしたDB操作を行いたい時に、Webベースで行えるので便利です。開発中にも、便利に使えるでしょう。
ADOdbのその他の機能
Nagadodbは、多くの方にとって、DB操作を行うのに十分な機能を提供していると思いますし、足りない機能は、Nagadodbの中身を覗けば、実装の仕方が分かるでしょう。しかし、ADOdbの持つ機能は、それだけではありません。
ADOdb Extension
PHPは、インタプリタ型言語であり、変数の型の概念が緩いため、実行速度があまり出ません。そこで、PHPでは遅くなりがちな処理を、C言語で記述しコンパイルした共有ライブラリに実行させて、速度を稼ぐことが考えられます。「ADOdb Extension」は正にそうした仕組みで作られた、ADOdbの追加モジュールです。
ダウンロードしたソースをmakeする必要があるので、rpmでのバイナリインストールしか経験のない方には、ちょっと抵抗があるかも知れませんが、makeする必要のあるものの中では、簡単な部類に入ると思います。
私も使っていますが、安定して動作しています。
セッション管理
利用者のある程度見込まれる実サービスでは、ロードバランサなどを使った負荷分散が行われます。こうした環境下では、負荷分散の手法によっては、同一の端末からのリクエストを、同じWebサーバで処理させることが保証できない場合が生じます。そうなってしまうと、セッション変数などの永続的なリソースを利用できなくなってしまいます。そこで、全てのWebサーバから利用されるDB内に、永続的なリソースを保持させ、セッションの保証を行うことを考えます。
ページビュー毎にDBアクセスが生じるため、DBへの負荷は高くなります。しかし、ADOdbは高速性が特徴でもあるので、耐えられる限度がそこそこ見込めます。
残念ながら、私はまだ試していません。
データディクショナリ
カラムの型や制約などは、細かいことをいうと、DBの種類によって異なります。それほどつっこんだ使い方をしなければ、主要なDBの何れでも動くSQL文を書けますが、つっこんだ使い方を求められる場合もあるでしょう。そこで、DBの種類による差異を吸収して、DBを論理的に表現する方法が必要となります。個々のDBの多少の差異は、表現の仕方の差異であることが殆どで、論理的には、差異がないと考えられる場合が多いのです。
ADOdbでは、そうした表現を行うために、「データディクショナリ」という仕組みを持っています。テーブルの作成やカラムの追加、制約条件の設定などを、SQL文ではなく、PHPのメソッドで行うことができます。また「ADOdb XML Schema (AXMLS)」という、XMLでデータベースのスキーマ定義を行える仕組みも用意されています。
私はAXMLSを試してみましたが、「AUTOINCREMENT」は正しく設定されるが、「AUTO」では正しく設定されないなどの問題点がありました。DBのスキーマ定義をXMLで行おうというアプローチは、今後、標準仕様が出てくる可能性が高く、特に必要がなければ、AXMLSを使う必要はないと感じました。
データディクショナリは、SQLでできることを、SQLを使わずに実現することを指向しています。確かに、SQLの方言に悩まされることはなくなりますが、SQLと論理的な概念が同じであるにも関わらず、DB操作を行う技術者が慣れ親しんだSQLとは異なる表現を使う必要があることは、デメリットでしょう。例えば、「int」を「I」と表現することになっている点などがそうです。
まとめ
本稿では、ADOdbのラッパーであるNagadodbを通じて、ADOdbを使う方法について述べました。皆さんのスキルに応じて、Nagadodbを利用するだけでもよいでしょうし、Nagadodbを改造して使ってもよいでしょうし、これをきっかけにADOdbのマニュアルを読んでもよいでしょう。

