





































parallel_for
for ( T i = first; i < last; i += step ) {
func(i);
}
という、典型的なループにおいて、ループ内の処理func(i)を複数個同時にやってしまうのがparallel_for(first, last, step, func)です(stepを省略すると1とみなされます)。素数探しはこんな実装。
void prime_parallel_for(unsigned int limit, vector<unsigned int>& primes) {
critical_section cs;
parallel_for(0U, limit, [&primes, &cs](unsigned int i) {
unsigned int n = nth_prime_candidate(i);
if (is_prime(n)) {
critical_section::scoped_lock guard(cs);
primes.push_back(n);
}
});
}
parallel_for_each
標準C++ライブラリ:<algorithm>に定義されたstd::for_each()の並列版がparallel_for_each()です。"コンテナの各要素に対して関数オブジェクトを適用"を並列に(複数個同時に)行ってくれます。
void prime_parallel_for_each(unsigned int limit, vector<unsigned int>& primes) {
vector<unsigned int> candidates(limit);
iota(begin(candidates), end(candidates), 0U);
parallel_transform(begin(candidates), end(candidates), begin(candidates),[](unsigned int n) { return nth_prime_candidate(n);});
critical_section cs;
parallel_for_each(begin(candidates), end(candidates),
[&primes,&cs](unsigned int n) {
if ( is_prime(n) ) {
critical_section::scoped_lock guard(cs);
primes.push_back(n);
}
});
}
このコードでは素数候補を詰め込んだコンテナ:candidatesを作るのにstd::transform()の並列版: parallel_transform()を使っています。
parallel_invoke(),parallel_for(),parallel_for_each()を使った3つの素数探しの実行時間を、並列アルゴリズムを使わない版と比べてみました。
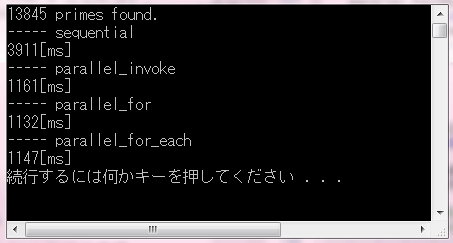
スピードはどれも大差なく、並列アルゴリズムを使わない版よりおよそ4倍速くなっています。CPUはi7-2600K、コアは4つだけどhyper-threadingを有効にしているので同時に8つのスレッドが動きます。なので8倍速くなるのを期待していたのですが……コアがいくつあろうがメモリ・バスは一本しかないのだし、スレッド・コンテキストの切り替えにも相応のオーバーヘッドを伴いますから、まぁこんなもんでしょう。アルゴリズムを一切変更せずに4倍速くなったのだから上等と言えるでしょうね。
ところでこれら並列アルゴリズムによる素数探し、見つけた素数はvector<unsigned int>に蓄えられていますが、昇順に並んではいません。PPLが用意してくれているソート関数をいくつか紹介しておきましょう。
- parallel_sort(first, last, comp):std::sort()の並列版。2つのイテレータ:firstとlastに挟まれた半開区間[first,last)を(比較オブジェクトcompの結果に基づいて)ソートします。
- parallel_buffered_sort(first, last, comp):作業領域を内部的に確保することでより高速化したparallel_sort。
- parallel_radixsort(first, last, key):ソート対象がunsigned intに限定されるものの、とにかく高速。要素型がunsigned intであればkeyは不要ですが、それ以外であった場合は各要素からunsigned int型のソート・キーを作る関数オブジェクト:keyを与えます。
上記3種の並列ソートとstd::sort()の処理時間を比べてみました。
#undef NDEBUG
#include <iostream>
#include <numeric>
#include <vector>
#include <chrono>
#include <cassert>
#include <ppl.h>
using namespace std;
using namespace concurrency;
template<typename Function>
inline const std::chrono::milliseconds measure_exec(const Function& fun) {
std::chrono::high_resolution_clock::time_point start = std::chrono::high_resolution_clock::now();
fun();
return std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start);
}
int main() {
const unsigned int N = 5000000;
vector<unsigned int> src(N);
{ // setup initial data to be sorted
iota(begin(src), end(src), 0U);
random_shuffle(begin(src), end(src));
}
{
vector<unsigned int> c(src);
cout << "----- sort" << endl;
auto dur = measure_exec([&]() {
sort(begin(c), end(c));
});
assert(is_sorted(begin(c), end(c)));
cout << dur.count() << "[ms]" << endl;
}
{
vector<unsigned int> c(src);
cout << "----- parallel_sort" << endl;
auto dur = measure_exec([&]() {
parallel_sort(begin(c), end(c));
});
assert(is_sorted(begin(c), end(c)));
cout << dur.count() << "[ms]" << endl;
}
{
vector<unsigned int> c(src);
cout << "----- parallel_buffered_sort" << endl;
auto dur = measure_exec([&]() {
parallel_buffered_sort(begin(c), end(c));
});
assert(is_sorted(begin(c), end(c)));
cout << dur.count() << "[ms]" << endl;
}
{
vector<unsigned int> c(src);
cout << "----- parallel_radixsort" << endl;
auto dur = measure_exec([&]() {
parallel_radixsort(begin(c), end(c));
});
assert(is_sorted(begin(c), end(c)));
cout << dur.count() << "[ms]" << endl;
ref(c);
}
}
実行結果は……
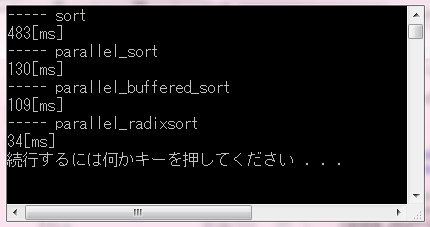
……ほほぉ、std::sort()はかなり速いソートなんですけど、並列ソートはさらにその4倍以上のスピード、特にparallel_radixsort()のスピードが際立っています。大量のデータをソート、あるいは頻繁にソートしなければならないアプリケーションには(コア数に依存するとはいうものの)かなり役に立ちそうです。

