





































はじめに
前回『δ符号によるデータ領域の節約』にて紹介したδ符号を応用して、アドホックな高密度データ圧縮を実装した応用例を紹介します。
対象読者
データ圧縮、特に独自方式での高密度データ格納に興味がある方を対象としています。δ符号に関する知識(参考:拙稿『δ符号によるデータ領域の節約』)を前提としています。
また、C++の基本的な文法および演算子についての知識が必要です。クラスやテンプレート、STLなどは使用していません。
必要な環境
本稿の対象環境は、Microsoft Visual C++ 6.0以降のMicrosoft社製C++コンパイラです。一部にインラインアセンブラ、およびPentium命令を使用しています。他のC++環境への移植はさほど困難ではありません。しかし、C環境に移植する場合は、関数の多重定義に留意してください。
圧縮を行ったデータについて
本稿にて圧縮を行ったのは、Unicodeのすべての文字コードが「何語で使用される記号なのか」を格納した65,536バイトの文字種テーブルです。1文字あたり1バイトを使用しています。格納された値と対応する言語は、以下に示すヘッダファイルを参照してください。
なお、このヘッダファイルは、何らかのアプリケーションに組み込んで使用するために用意したものであり、サンプル中では使用していません。実際の文字種テーブルは、添付アーカイブの「EncodeUTable」フォルダ内にある「CodeTbl.bin」を参照してください。
#ifndef __WCHARTYPE #define __WCHARTYPE #define CHARTYPE_NONE 0 // 分類なし #define CHARTYPE_SPACE 1 // 空白 #define CHARTYPE_SYMBOL 2 // 記号 #define CHARTYPE_NUMBER 3 // 数字 #define CHARTYPE_LATIN 4 // ラテンアルファベット #define CHARTYPE_IPA 5 // 発音記号 #define CHARTYPE_GREEK 6 // ギリシア語 #define CHARTYPE_CYRIL 7 // キリル #define CHARTYPE_ARMENIA 8 // アルメニア #define CHARTYPE_HEBREW 9 // ヘブライ #define CHARTYPE_ARABIC 10 // アラビア #define CHARTYPE_CYRIA 11 // シリア #define CHARTYPE_THAANA 12 // #define CHARTYPE_DEVA 13 // デーヴァナーガリー文字 #define CHARTYPE_BENGAL 14 // ベンガル語 #define CHARTYPE_GURU 15 // グルムキー文字 #define CHARTYPE_GUJA 16 // グジャラート語 #define CHARTYPE_ORIYA 17 // オリヤー語 #define CHARTYPE_TAMIL 18 // タミル語 #define CHARTYPE_TELUGU 19 // テルグ語 #define CHARTYPE_KANNADA 20 // カナラ語 #define CHARTYPE_MALAYA 21 // マラヤーラム語 #define CHARTYPE_SINHALA 22 // シンハラ語 #define CHARTYPE_THAI 23 // タイ語 #define CHARTYPE_LAO 24 // ラオ語 #define CHARTYPE_TIBETAN 25 // チベット語 #define CHARTYPE_MYANMAR 26 // ミャンマー #define CHARTYPE_GEORGIA 27 // グルジア語 #define CHARTYPE_HANGUL 28 // ハングル #define CHARTYPE_ETHIOPI 29 // 古代エチオピア語 #define CHARTYPE_CHERO 30 // チェロキー語 #define CHARTYPE_CANADA 31 // #define CHARTYPE_OGHAM 32 // オガム文字 #define CHARTYPE_RUNIC 33 // ルーン文字 #define CHARTYPE_TAGALOG 34 // タガログ語 #define CHARTYPE_HANUNOO 35 // #define CHARTYPE_BUHID 36 // #define CHARTYPE_TAGB 37 // #define CHARTYPE_KHMER 38 // クメール語 #define CHARTYPE_MONGOL 39 // モンゴル語 #define CHARTYPE_LIMBU 40 // #define CHARTYPE_TAILE 41 // #define CHARTYPE_UPA 42 #define CHARTYPE_HIRA 43 // ひらがな #define CHARTYPE_KATA 44 // カタカナ #define CHARTYPE_KANJI 45 // 漢字 #define CHARTYPE_BOPO 46 // #define CHARTYPE_YI 47 // #define CHARTYPE_PUA 48 // (外字) #endif //__WCHARTYPE
圧縮フォーマット
テーブルの各バイトの値をそのままδ符号にするのは芸がありません。また実際のところ、それほど圧縮効果が上がるわけでもありません。文字種テーブル「CodeTbl.bin」をバイナリエディタで眺めてみましょう。すぐに、あることに気付くと思います。それは値が連続した箇所が極めて多いことです。
最も長い箇所で、オフセット0x4e00から20911バイトもの間、0x2dが続きます。このようなデータの場合は、RLE(Run Length Encoding:ランレングス法)を用いると効率よく圧縮することができます。RLEとは「データ中のある値がどのくらいの長さ(length)で連続(run)しているか」、つまりランレングス(run length)の情報に置き換えてデータを保存する圧縮方式です。
ここでは、少しでもデータを小さくすべく検討した結果、次のようなフォーマットにすることにしました。
- 文字種テーブルは1バイト単位で走査する。
- 文字種テーブル上の前バイトの値との差分をデータとして記録する。先頭バイトは0と比較する。
- ランレングスは、先頭に1のビットを配置し、続くビット列でランレングス値の格納ビット数を判断できる形とする。
| 整数 | 自然数 |
| -3 | 7 |
| -2 | 5 |
| -1 | 3 |
| 0 | 1 |
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
この定義に従ってランレングスを書き出しているのは、下記ソースコード中、WRITE_SEQ_INFOマクロです。行展開したコードを示します。
//#define WRITE_SEQ_INFO if(1 == byPrevWrite) // 直前の差が1ならば { Delta(1); // ランレングスを示す先頭ビット lCount++; if(lCount <= 31) // length<=31ならばδ符号で出力 { // この場合、先頭ビットは0となる Delta(lCount); } else if( lCount <= 127) // length<=127ならば7ビットで記述可能 { lCount |= 0x00000100; //'10'に続けて7ビットがランレングス Bits(lCount, 9); // 合計9ビットが出力対象 } else { lCount |= 0x00018000; // '11'に続けて15ビットがランレングス Bits(lCount, 17); // 合計17ビットが出力対象 } lCount = 0; }
Encode部の実装
上記圧縮フォーマットに従って実際に圧縮を行うEncode関数を示します。ループ終了後、ランレングスの残分があればそれを出力しなくてはなりません。また、バイト境界整合をとることを忘れないようにします。
// 同じ値であることを示す"1"と、 // それがいくつ連続しているかを書き出すマクロ #define WRITE_SEQ_INFO if(1 == byPrevWrite){Delta(1); lCount++; if(lCount <= 31) {Delta(lCount);} else if
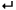 {Delta(1); lCount++;
{Delta(1); lCount++; Decode部の実装
上記圧縮フォーマットのルールに従って実装したDecode関数を示します。展開したデータをアプリケーションで使用することを想定しているので、メモリ上にそのまま残すようにしています。
// 名称:BYTE *Decode(const BYTE *pbyRF) // 機能:Encode時のルールに準拠してデータを展開する。 // 展開先のはDecode関数内で確保し、そのポインタを返す。 // 当該領域は、呼び出し元で開放しなくてはならない。 // 引数:const BYTE * Encodeされたデータの先頭アドレス // 返値:BYTE * デコードされたデータ(65536バイト)の先頭アドレス BYTE *Decode(const BYTE *pbyRF) { BYTE *pbyTable = (BYTE*)calloc(sizeof(BYTE), UNICODE_TABLE_LENGTH); if(!pbyTable) return NULL; BYTE *pby = pbyTable; BYTE byPrev; BYTE byRead; DeltaInit((void *)pbyRF); // δ符号処理の初期化 byPrev = 0; // 1つ前の値の初期値=0 long lCount = 0; // 連続する値を格納する for(int j = 0; j < 65536; j+=lCount) { byRead = (BYTE)Delta(); if(1 == byRead) // 読み取った値が1ならば、 // その後に何バイト連続するか格納されている { if(1 == (lCount = Delta())) // それが1の場合、 lCount = Bits(Bit() ? 15 : 7); // 続くビットが0ならば7ビット。1ならば15ビットが連続数 lCount--; for(long l = 0; l < lCount; l++) // 連続するデータをメモリに書き出す *pby++ = byPrev; } else { if(byRead & 1) // 最下位ビットが1なら、 byPrev += (byRead>>1); // 前の値に差を加える else // そうでなければ byPrev -= (byRead>>1); // 前の値から差を引く *pby++ = byPrev; // メモリに書き出す lCount = 1; } } return pbyTable; // 展開したデータの先頭アドレスを返す }
サンプルについて
圧縮側は「EncodeUTable」フォルダに、展開側は「DecodeUTable」フォルダに、それぞれコマンドラインツールの形で用意しています。圧縮側は、同フォルダ内にある「CodeTbl.bin」(文字種別テーブル)を読み取って「CodeTbl.enc」(圧縮済バイナリ)ファイルを出力します。
展開側は、同フォルダ内にある「CodeTbl.enc」(圧縮済バイナリ)を読み取って「CodeTbl.ext」(展開済の文字種テーブル)ファイルを出力します。
圧縮済バイナリサイズは、わずか284バイトなので、実に99.57%という脅威の圧縮率が達成されています。この値は、このデータに関する限りでは、zipなどに引けを取らない成績です。
おわりに
今回紹介した事例は、汎用的ではありませんでしたが、用途はいろいろと考えられます。例えば、1チッププロセッサのROMやROMカートリッジなど、ROM側の容量が限られた環境でテーブルを設けたい場合などに有効です。
データ圧縮フォーマットの決定時に最も重要なのは、データの性質に着目し、より適した手法を選択することです。実際の業務で用いる場合には、できるだけ安全かつ低コストで利用できるかどうかが重要な尺度になります。そういった面でも、このような平易な方式は、十分参考になるのではないかと思います。

