



































[注意] 今回はPower Automate Desktopの作業しているPCにExcelがインストールされていることを前提としています。
また、前回取得したXMLを使用しますので、ファイル内容などは第12回を参照してください。
XMLからデータを抽出する
XMLデータの取得を確認できたところで、ここからはXMLデータから必要な情報を取り出し、Excelシートにまとめてみましょう。
[1]新しいフローを作成して前回のフローをコピーする
Power Automate for Desktopのトップ画面から[+新しいフロー]をクリックして、適当な名前で新規のフローを作成します。
第12回のサンプルをダウンロードして、テキストエディターですべてを選択してコピー、作成したフローのワークスペースにペーストします。
[2]XPath式でXMLデータを読み込む
XMLのツリー構造は、XPath式を用いることで読み取ることが可能です。[XML]アクショングループの[XPath式を実行します]アクションを配置すると、設定ダイアログが開きます。
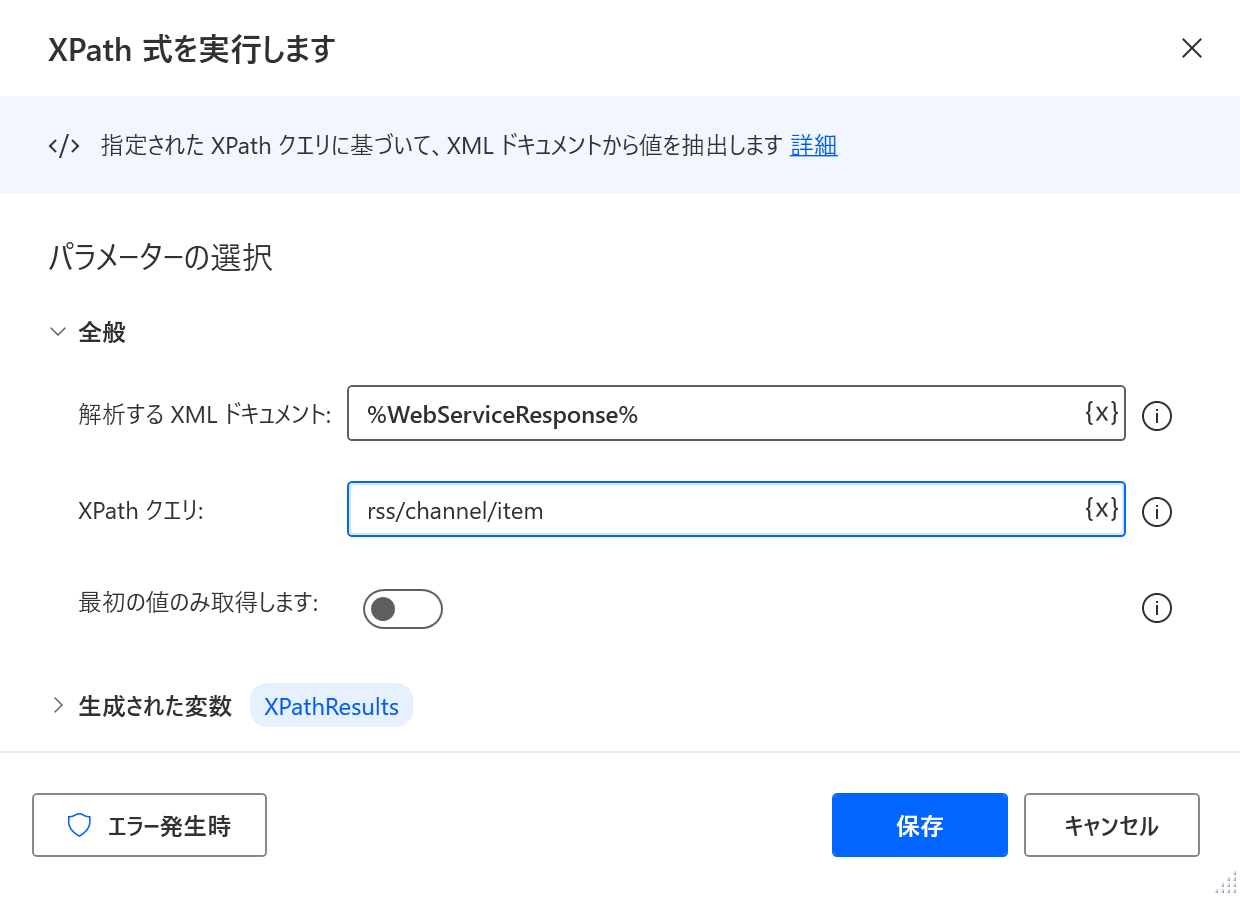
以下の設定を選択/入力し、保存します。
- 解析するXMLドキュメント:%WebServiceResponse%
- XPathクエリ:rss/channel/item
WebServiceResponseは、HTTP経由で取得したXMLデータそのものを表す変数です。rss/channel/itemで、rss-channel要素配下のitem要素をすべて取得します。この結果は、XPathResults変数に反映されます。
[Note]XPathについて
XPath(XML Path Language)は、XMLの特定の要素・属性(1個~複数個)を指定する構文です。同様なツリー構造であるファイルシステムにおけるファイルパスと似ています。「親要素/子要素」のように子要素を指定すると、「rss/channel/item」はrss要素の子要素channelの子要素itemのすべてにマッチします。[XPath式を実行します]アクションの本文の指定では、以下の複数組の<item>~</item>を抽出できます。
以下に、XPath式の最低限の構文を示します。
<rss version="2.0" ...> <channel> <item> </item> <item> </item> ... ... </channel> </rss>
- 先頭の「/」はXMLドキュメントのトップレベルノードを表します。
- 要素名の代わりに「*」を指定すると、任意の要素名のノードすべての意味になります。
- 「要素名[条件式]」で、条件式を満たすノードのみ抽出できます。条件式の部分では、XPath関数を使用できます。
- 要素、属性名を指定した場合には、その要素/属性が存在するかを判定します
例えば、条件式を応用して「rss/channel/item」を「rss/channel/item[pubDate]」と変更すると、子要素として<pubDate>をもつ<item>要素のみを抽出することができます。
また、後のアクション設定の箇所で、
/item/*[local-name()='xxxx']
という式を指定しています。
XMLドキュメントの「要素名」は「:」が含まれるものがあります(例えば<dcndl:price>)。「:」の前と後ろで「(名前空間):(ローカル名)」に分かれます。local-name()はノードのローカル名を取得するXPath関数です。トップレベルのitem要素のすべての子要素のうち、ローカル名が「xxxx」になるものを取得するという意味になります。
詳細は、以下のページや、検索サイトでキーワード「XPath」で検索した結果のページなどを参照してください。

